 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumos : Empowering Multimodal LLMs with Scene Text Recognition
Feb 12, 2024



We introduce Lumos, the first end-to-end multimodal question-answering system with text understanding capabilities. At the core of Lumos is a Scene Text Recognition (STR) component that extracts text from first person point-of-view images, the output of which is used to augment input to a Multimodal Large Language Model (MM-LLM). While building Lumos, we encountered numerous challenges related to STR quality, overall latency, and model inference. In this paper, we delve into those challenges, and discuss the system architecture, design choices, and modeling techniques employed to overcome these obstacles. We also provide a comprehensive evaluation for each component, showcasing high quality and efficiency.
Latency-Aware Neural Architecture Search with Multi-Objective Bayesian Optimization
Jun 25, 2021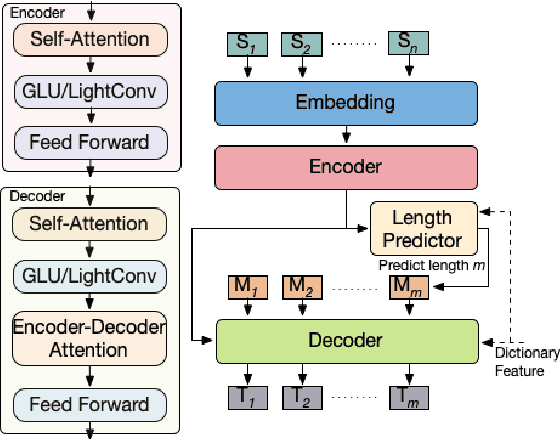

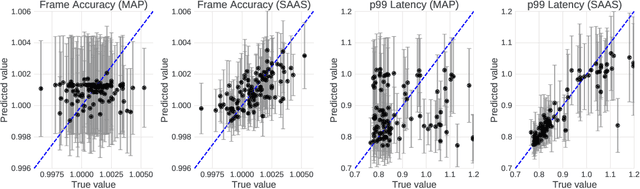
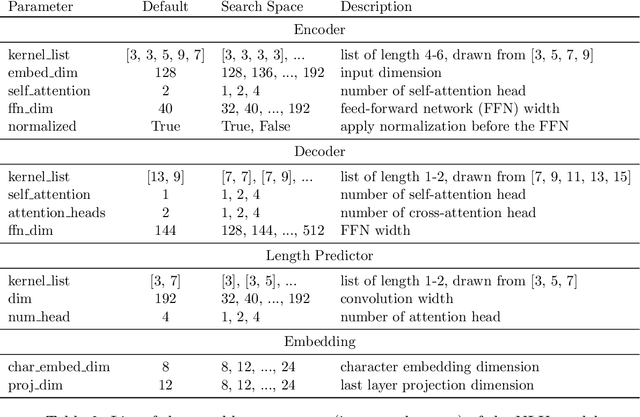
When tuning the architecture and hyperparameters of large machine learning models for on-device deployment, it is desirable to understand the optimal trade-offs between on-device latency and model accuracy. In this work, we leverage recent methodological advances in Bayesian optimization over high-dimensional search spaces and multi-objective Bayesian optimization to efficiently explore these trade-offs for a production-scale on-device natural language understanding model at Facebook.
PyText: A Seamless Path from NLP research to production
Dec 12, 2018



We introduce PyText - a deep learning based NLP modeling framework built on PyTorch. PyText addresses the often-conflicting requirements of enabling rapid experimentation and of serving models at scale. It achieves this by providing simple and extensible interfaces for model components, and by using PyTorch's capabilities of exporting models for inference via the optimized Caffe2 execution engine. We report our own experience of migrating experimentation and production workflows to PyText, which enabled us to iterate faster on novel modeling ideas and then seamlessly ship them at industrial scale.