 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRESTO: A Multilingual Dataset for Parsing Realistic Task-Oriented Dialogs
Mar 17, 2023



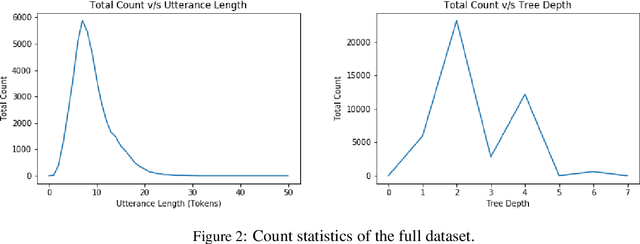
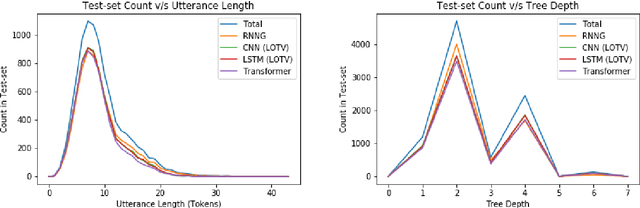
Research interest in task-oriented dialogs has increased as systems such as Google Assistant, Alexa and Siri have become ubiquitous in everyday life. However, the impact of academic research in this area has been limited by the lack of datasets that realistically capture the wide array of user pain points. To enable research on some of the more challenging aspects of parsing realistic conversations, we introduce PRESTO, a public dataset of over 550K contextual multilingual conversations between humans and virtual assistants. PRESTO contains a diverse array of challenges that occur in real-world NLU tasks such as disfluencies, code-switching, and revisions. It is the only large scale human generated conversational parsing dataset that provides structured context such as a user's contacts and lists for each example. Our mT5 model based baselines demonstrate that the conversational phenomenon present in PRESTO are challenging to model, which is further pronounced in a low-resource setup.
DAMP: Doubly Aligned Multilingual Parser for Task-Oriented Dialogue
Dec 15, 2022Modern virtual assistants use internal semantic parsing engines to convert user utterances to actionable commands. However, prior work has demonstrated that semantic parsing is a difficult multilingual transfer task with low transfer efficiency compared to other tasks. In global markets such as India and Latin America, this is a critical issue as switching between languages is prevalent for bilingual users. In this work we dramatically improve the zero-shot performance of a multilingual and codeswitched semantic parsing system using two stages of multilingual alignment. First, we show that constrastive alignment pretraining improves both English performance and transfer efficiency. We then introduce a constrained optimization approach for hyperparameter-free adversarial alignment during finetuning. Our Doubly Aligned Multilingual Parser (DAMP) improves mBERT transfer performance by 3x, 6x, and 81x on the Spanglish, Hinglish and Multilingual Task Oriented Parsing benchmarks respectively and outperforms XLM-R and mT5-Large using 3.2x fewer parameters.
Improving Top-K Decoding for Non-Autoregressive Semantic Parsing via Intent Conditioning
Apr 14, 2022
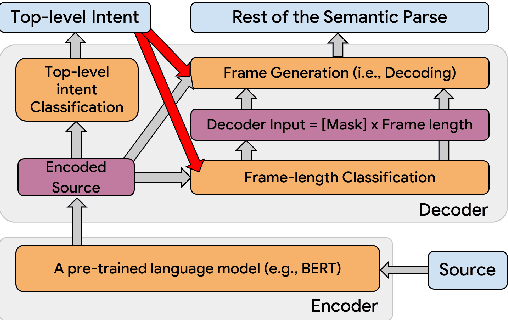

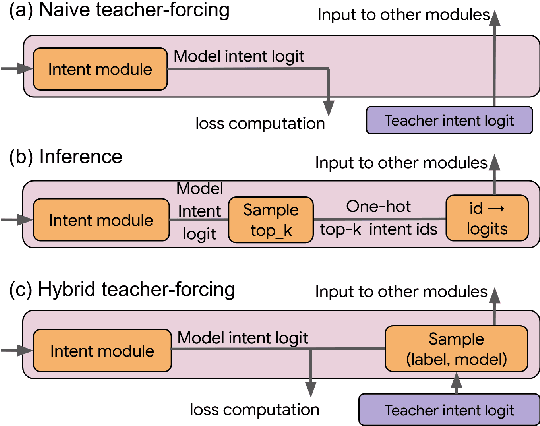
Semantic parsing (SP) is a core component of modern virtual assistants like Google Assistant and Amazon Alexa. While sequence-to-sequence-based auto-regressive (AR) approaches are common for conversational semantic parsing, recent studies employ non-autoregressive (NAR) decoders and reduce inference latency while maintaining competitive parsing quality. However, a major drawback of NAR decoders is the difficulty of generating top-k (i.e., k-best) outputs with approaches such as beam search. To address this challenge, we propose a novel NAR semantic parser that introduces intent conditioning on the decoder. Inspired by the traditional intent and slot tagging parsers, we decouple the top-level intent prediction from the rest of a parse. As the top-level intent largely governs the syntax and semantics of a parse, the intent conditioning allows the model to better control beam search and improves the quality and diversity of top-k outputs. We introduce a hybrid teacher-forcing approach to avoid training and inference mismatch. We evaluate the proposed NAR on conversational SP datasets, TOP & TOPv2. Like the existing NAR models, we maintain the O(1) decoding time complexity while generating more diverse outputs and improving the top-3 exact match (EM) by 2.4 points. In comparison with AR models, our model speeds up beam search inference by 6.7 times on CPU with competitive top-k EM.
Overcoming Conflicting Data for Model Updates
Oct 23, 2020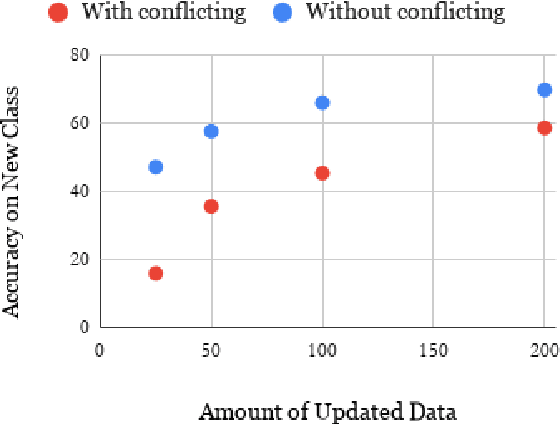

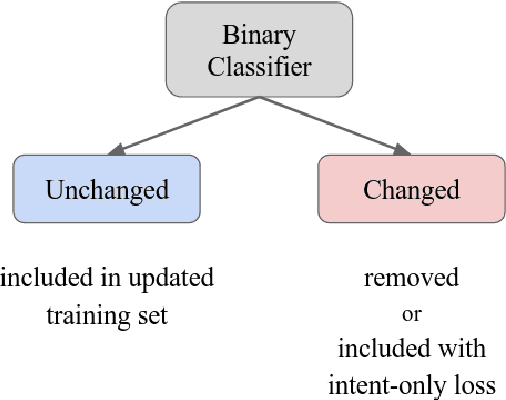
In this paper, we explore how to use a small amount of new data to update a model when the desired output for some examples has changed. When making updates in this way, one potential problem that arises is the presence of conflicting data, or out-of-date labels in the original training set. To evaluate the impact of this problem, we propose an experimental setup for simulating changes to a neural semantic parser. We show that the presence of conflicting data greatly hinders learning of an update, then explore several methods to mitigate its effect. Our methods lead to large improvements in model accuracy compared to a naive mixing strategy, and our best method closes 86% of the accuracy gap between this baseline and an oracle upper bound.
Continual Learning for Neural Semantic Parsing
Oct 15, 2020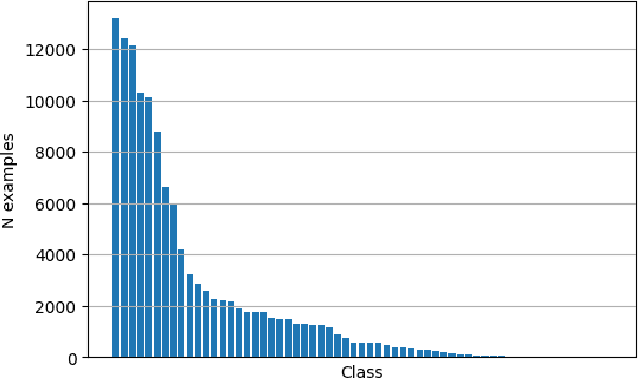
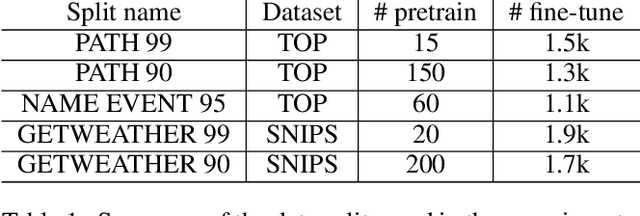
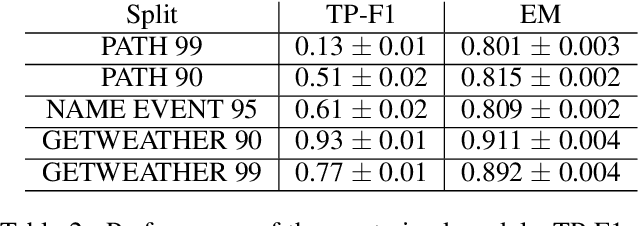
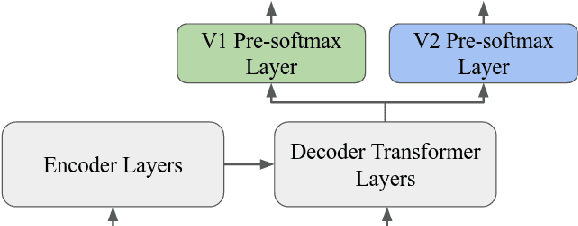
A semantic parsing model is crucial to natural language processing applications such as goal-oriented dialogue systems. Such models can have hundreds of classes with a highly non-uniform distribution. In this work, we show how to efficiently (in terms of computational budget) improve model performance given a new portion of labeled data for a specific low-resource class or a set of classes. We demonstrate that a simple approach with a specific fine-tuning procedure for the old model can reduce the computational costs by ~90% compared to the training of a new model. The resulting performance is on-par with a model trained from scratch on a full dataset. We showcase the efficacy of our approach on two popular semantic parsing datasets, Facebook TOP, and SNIPS.
Improving Robustness of Task Oriented Dialog Systems
Nov 12, 2019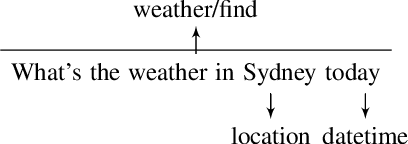



Task oriented language understanding in dialog systems is often modeled using intents (task of a query) and slots (parameters for that task). Intent detection and slot tagging are, in turn, modeled using sentence classification and word tagging techniques respectively. Similar to adversarial attack problems with computer vision models discussed in existing literature, these intent-slot tagging models are often over-sensitive to small variations in input -- predicting different and often incorrect labels when small changes are made to a query, thus reducing their accuracy and reliability. However, evaluating a model's robustness to these changes is harder for language since words are discrete and an automated change (e.g. adding `noise') to a query sometimes changes the meaning and thus labels of a query. In this paper, we first describe how to create an adversarial test set to measure the robustness of these models. Furthermore, we introduce and adapt adversarial training methods as well as data augmentation using back-translation to mitigate these issues. Our experiments show that both techniques improve the robustness of the system substantially and can be combined to yield the best results.
Improving Semantic Parsing for Task Oriented Dialog
Feb 15, 2019

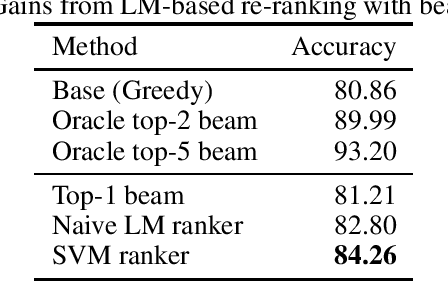
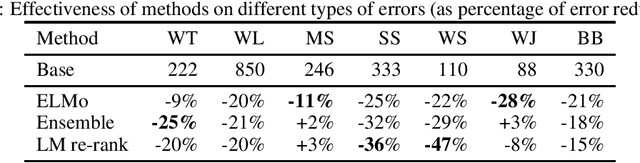
Semantic parsing using hierarchical representations has recently been proposed for task oriented dialog with promising results [Gupta et al 2018]. In this paper, we present three different improvements to the model: contextualized embeddings, ensembling, and pairwise re-ranking based on a language model. We taxonomize the errors possible for the hierarchical representation, such as wrong top intent, missing spans or split spans, and show that the three approaches correct different kinds of errors. The best model combines the three techniques and gives 6.4% better exact match accuracy than the state-of-the-art, with an error reduction of 33%, resulting in a new state-of-the-art result on the Task Oriented Parsing (TOP) dataset.
PyText: A Seamless Path from NLP research to production
Dec 12, 2018



We introduce PyText - a deep learning based NLP modeling framework built on PyTorch. PyText addresses the often-conflicting requirements of enabling rapid experimentation and of serving models at scale. It achieves this by providing simple and extensible interfaces for model components, and by using PyTorch's capabilities of exporting models for inference via the optimized Caffe2 execution engine. We report our own experience of migrating experimentation and production workflows to PyText, which enabled us to iterate faster on novel modeling ideas and then seamlessly ship them at industrial scale.
Cross-lingual Transfer Learning for Multilingual Task Oriented Dialog
Oct 31, 2018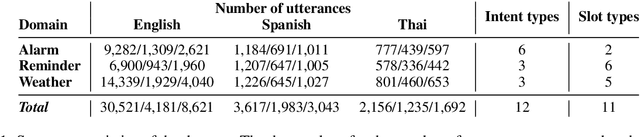
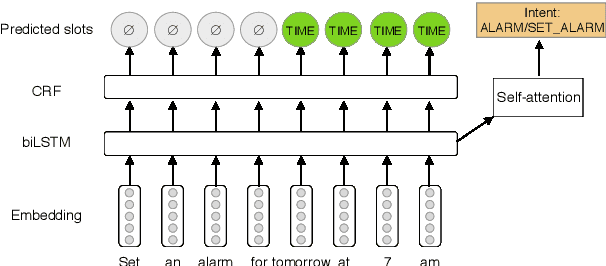
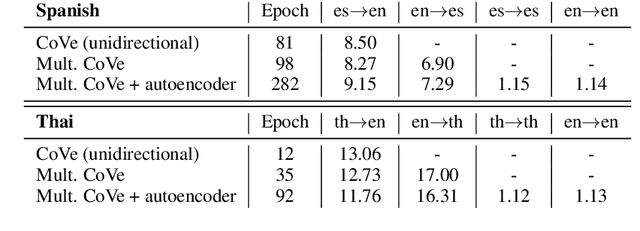
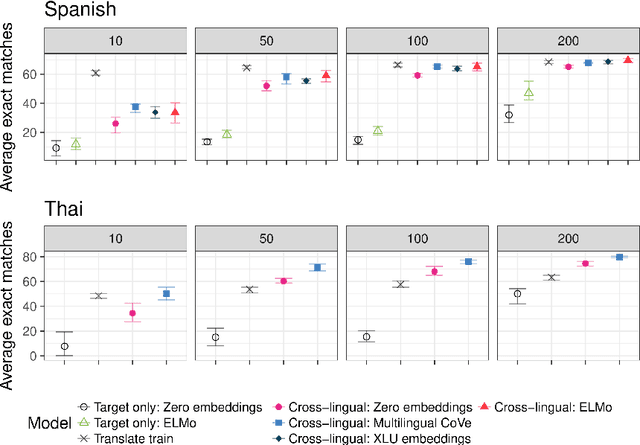
One of the first steps in the utterance interpretation pipeline of many task-oriented conversational AI systems is to identify user intents and the corresponding slots. Neural sequence labeling models have achieved very high accuracy on these tasks when trained on large amounts of training data. However, collecting this data is very time-consuming and therefore it is unfeasible to collect large amounts of data for many languages. For this reason, it is desirable to make use of existing data in a high-resource language to train models in low-resource languages. In this paper, we investigate the performance of three different methods for cross-lingual transfer learning, namely (1) translating the training data, (2) using cross-lingual pre-trained embeddings, and (3) a novel method of using a multilingual machine translation encoder as contextual word representations. We find that given several hundred training examples in the the target language, the latter two methods outperform translating the training data. Further, in very low-resource settings, we find that multilingual contextual word representations give better results than using cross-lingual static embeddings. We release a dataset of around 57k annotated utterances in English (43k), Spanish (8.6k) and Thai (5k) for three task oriented domains at https://fb.me/multilingual_task_oriented_data.
Semantic Parsing for Task Oriented Dialog using Hierarchical Representations
Oct 18, 2018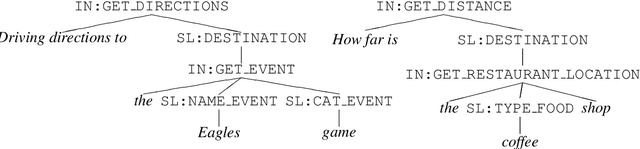

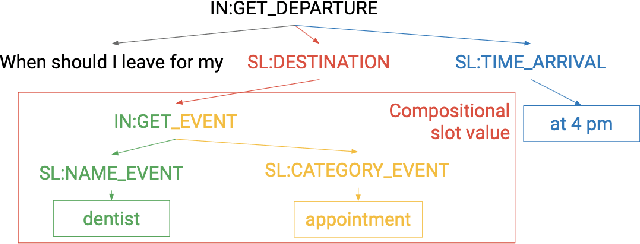
Task oriented dialog systems typically first parse user utterances to semantic frames comprised of intents and slots. Previous work on task oriented intent and slot-filling work has been restricted to one intent per query and one slot label per token, and thus cannot model complex compositional requests. Alternative semantic parsing systems have represented queries as logical forms, but these are challenging to annotate and parse. We propose a hierarchical annotation scheme for semantic parsing that allows the representation of compositional queries, and can be efficiently and accurately parsed by standard constituency parsing models. We release a dataset of 44k annotated queries (fb.me/semanticparsingdialog), and show that parsing models outperform sequence-to-sequence approaches on this dataset.