 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Transfer Learning for Multilingual Task Oriented Dialog
Paper and Code
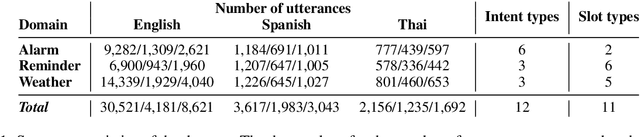
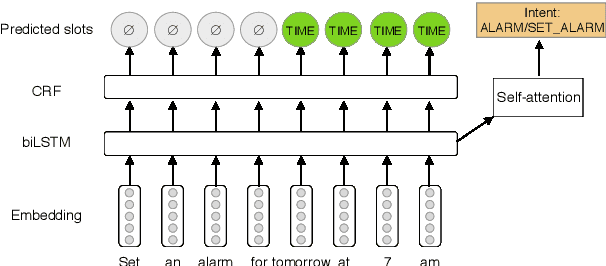
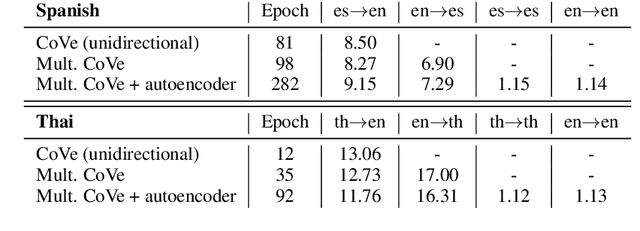
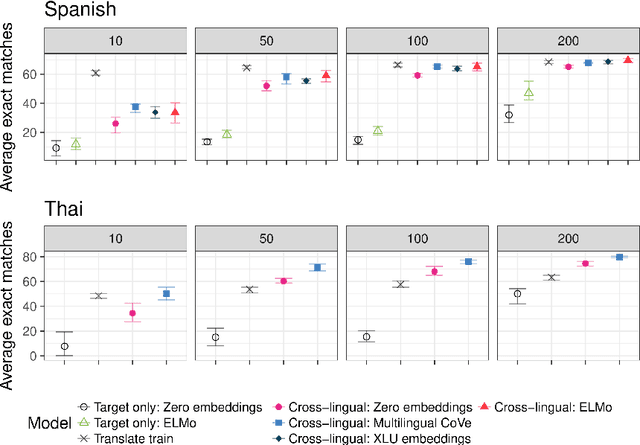
One of the first steps in the utterance interpretation pipeline of many task-oriented conversational AI systems is to identify user intents and the corresponding slots. Neural sequence labeling models have achieved very high accuracy on these tasks when trained on large amounts of training data. However, collecting this data is very time-consuming and therefore it is unfeasible to collect large amounts of data for many languages. For this reason, it is desirable to make use of existing data in a high-resource language to train models in low-resource languages. In this paper, we investigate the performance of three different methods for cross-lingual transfer learning, namely (1) translating the training data, (2) using cross-lingual pre-trained embeddings, and (3) a novel method of using a multilingual machine translation encoder as contextual word representations. We find that given several hundred training examples in the the target language, the latter two methods outperform translating the training data. Further, in very low-resource settings, we find that multilingual contextual word representations give better results than using cross-lingual static embeddings. We release a dataset of around 57k annotated utterances in English (43k), Spanish (8.6k) and Thai (5k) for three task oriented domains at https://fb.me/multilingual_task_oriented_data.