 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Conflicting Data for Model Updates
Oct 23, 2020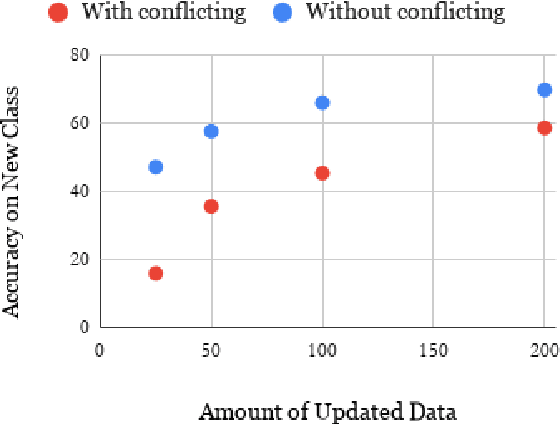

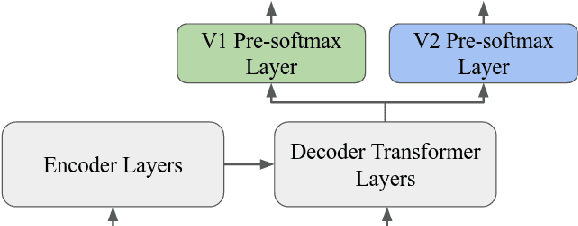
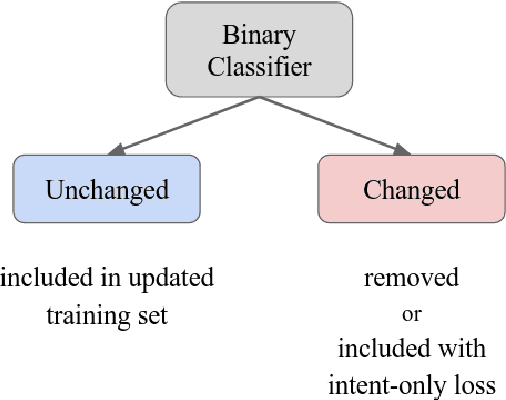
In this paper, we explore how to use a small amount of new data to update a model when the desired output for some examples has changed. When making updates in this way, one potential problem that arises is the presence of conflicting data, or out-of-date labels in the original training set. To evaluate the impact of this problem, we propose an experimental setup for simulating changes to a neural semantic parser. We show that the presence of conflicting data greatly hinders learning of an update, then explore several methods to mitigate its effect. Our methods lead to large improvements in model accuracy compared to a naive mixing strategy, and our best method closes 86% of the accuracy gap between this baseline and an oracle upper bound.
Defending Malware Classification Networks Against Adversarial Perturbations with Non-Negative Weight Restrictions
Jun 23, 2018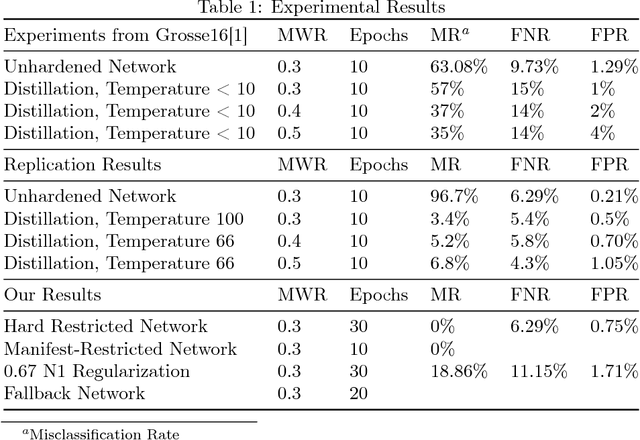
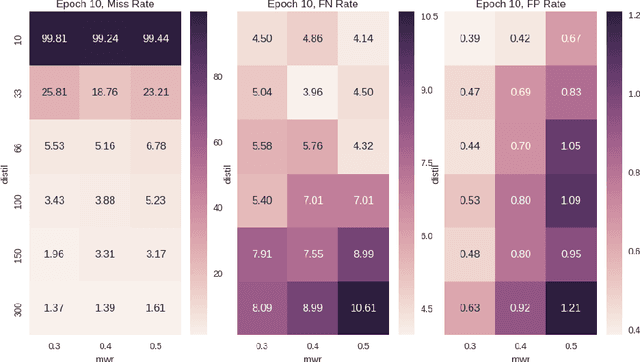
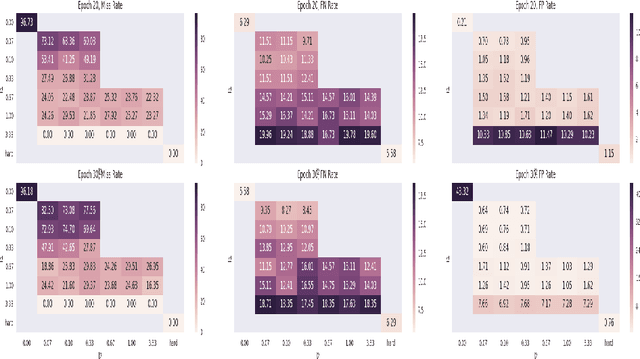
There is a growing body of literature showing that deep neural networks are vulnerable to adversarial input modification. Recently this work has been extended from image classification to malware classification over boolean features. In this paper we present several new methods for training restricted networks in this specific domain that are highly effective at preventing adversarial perturbations. We start with a fully adversarially resistant neural network that has hard non-negative weight restrictions and is equivalent to learning a monotonic boolean function and then attempt to relax the constraints to improve classifier accuracy.