 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASIL: Balanced Active Semi-supervised Learning for Class Imbalanced Datasets
Mar 10, 2022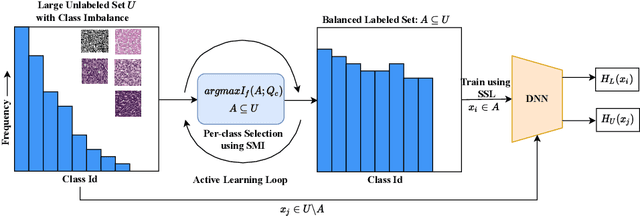

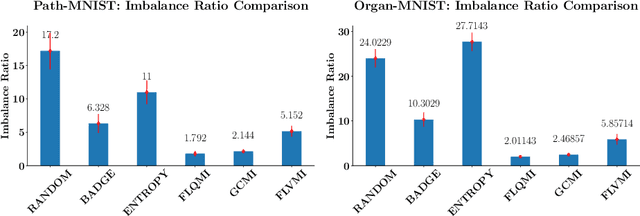
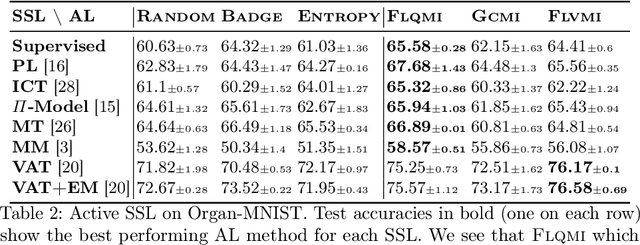
Current semi-supervised learning (SSL) methods assume a balance between the number of data points available for each class in both the labeled and the unlabeled data sets. However, there naturally exists a class imbalance in most real-world datasets. It is known that training models on such imbalanced datasets leads to biased models, which in turn lead to biased predictions towards the more frequent classes. This issue is further pronounced in SSL methods, as they would use this biased model to obtain psuedo-labels (on the unlabeled data) during training. In this paper, we tackle this problem by attempting to select a balanced labeled dataset for SSL that would result in an unbiased model. Unfortunately, acquiring a balanced labeled dataset from a class imbalanced distribution in one shot is challenging. We propose BASIL (Balanced Active Semi-supervIsed Learning), a novel algorithm that optimizes the submodular mutual information (SMI) functions in a per-class fashion to gradually select a balanced dataset in an active learning loop. Importantly, our technique can be efficiently used to improve the performance of any SSL method. Our experiments on Path-MNIST and Organ-MNIST medical datasets for a wide array of SSL methods show the effectiveness of Basil. Furthermore, we observe that Basil outperforms the state-of-the-art diversity and uncertainty based active learning methods since the SMI functions select a more balanced dataset.
Overcoming Conflicting Data for Model Updates
Oct 23, 2020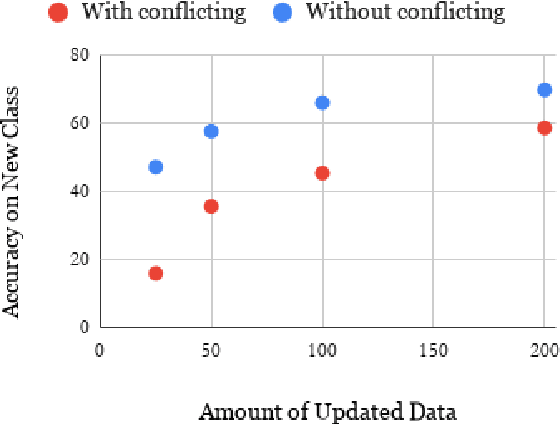

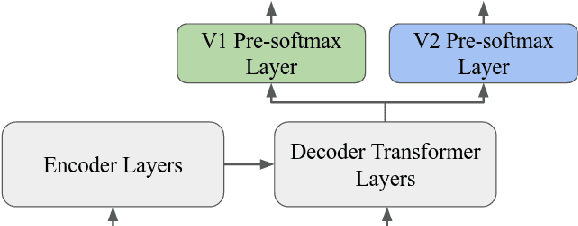
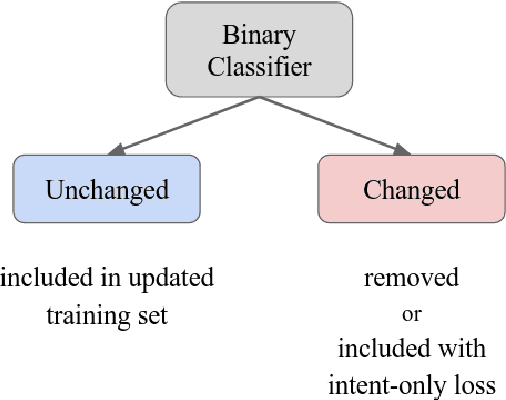
In this paper, we explore how to use a small amount of new data to update a model when the desired output for some examples has changed. When making updates in this way, one potential problem that arises is the presence of conflicting data, or out-of-date labels in the original training set. To evaluate the impact of this problem, we propose an experimental setup for simulating changes to a neural semantic parser. We show that the presence of conflicting data greatly hinders learning of an update, then explore several methods to mitigate its effect. Our methods lead to large improvements in model accuracy compared to a naive mixing strategy, and our best method closes 86% of the accuracy gap between this baseline and an oracle upper bound.