 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for Neural Semantic Parsing
Paper and Code
Oct 15, 2020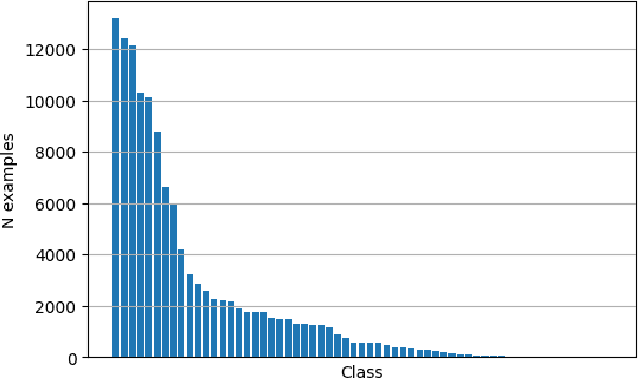
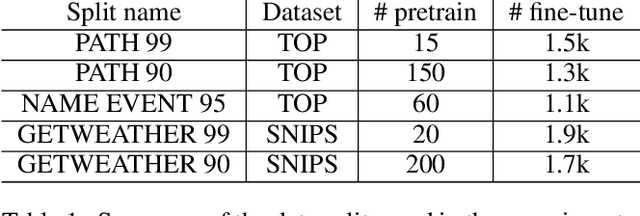
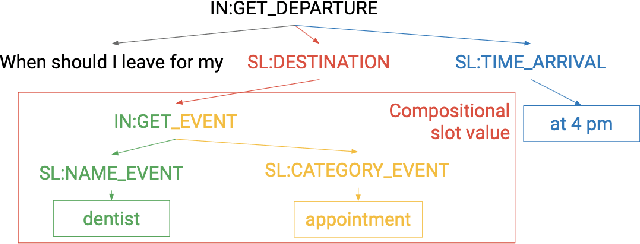
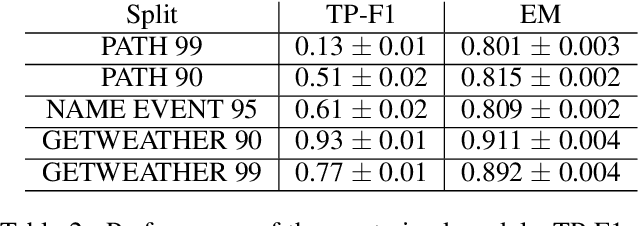
A semantic parsing model is crucial to natural language processing applications such as goal-oriented dialogue systems. Such models can have hundreds of classes with a highly non-uniform distribution. In this work, we show how to efficiently (in terms of computational budget) improve model performance given a new portion of labeled data for a specific low-resource class or a set of classes. We demonstrate that a simple approach with a specific fine-tuning procedure for the old model can reduce the computational costs by ~90% compared to the training of a new model. The resulting performance is on-par with a model trained from scratch on a full dataset. We showcase the efficacy of our approach on two popular semantic parsing datasets, Facebook TOP, and SNIPS.