 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness of Task Oriented Dialog Systems
Paper and Code
Nov 12, 2019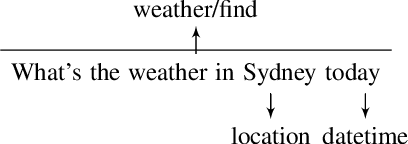



Task oriented language understanding in dialog systems is often modeled using intents (task of a query) and slots (parameters for that task). Intent detection and slot tagging are, in turn, modeled using sentence classification and word tagging techniques respectively. Similar to adversarial attack problems with computer vision models discussed in existing literature, these intent-slot tagging models are often over-sensitive to small variations in input -- predicting different and often incorrect labels when small changes are made to a query, thus reducing their accuracy and reliability. However, evaluating a model's robustness to these changes is harder for language since words are discrete and an automated change (e.g. adding `noise') to a query sometimes changes the meaning and thus labels of a query. In this paper, we first describe how to create an adversarial test set to measure the robustness of these models. Furthermore, we introduce and adapt adversarial training methods as well as data augmentation using back-translation to mitigate these issues. Our experiments show that both techniques improve the robustness of the system substantially and can be combined to yield the best results.