 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDi: Conversational Distillation for Grounded Question Answering
Aug 20, 2024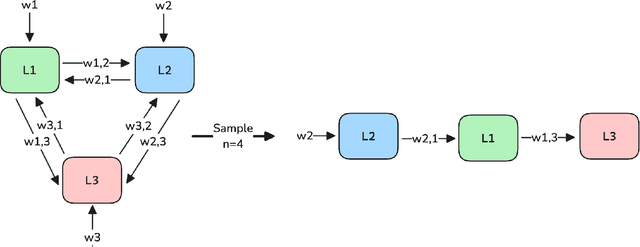
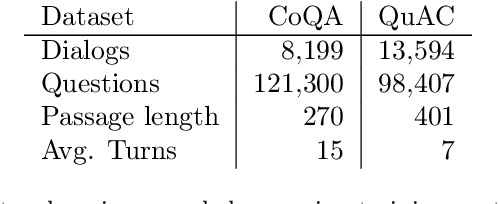
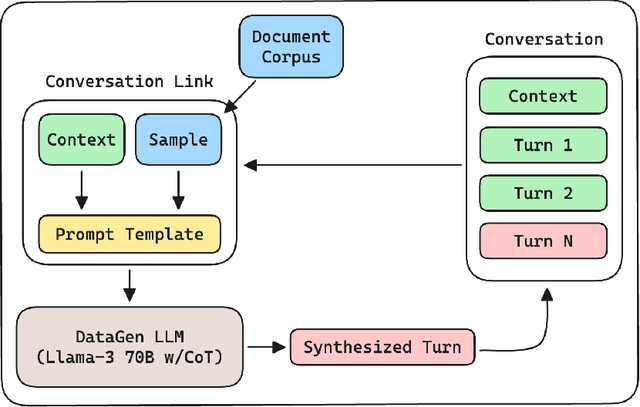
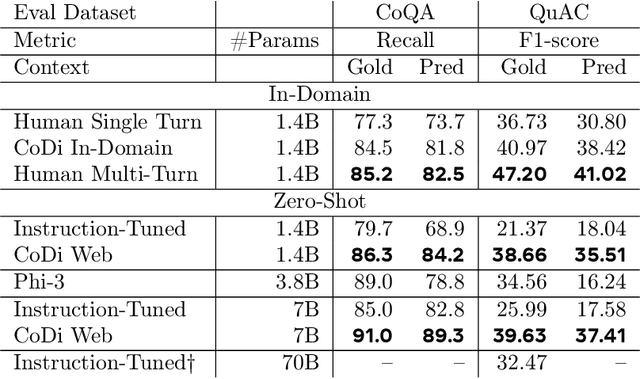
Distilling conversational skills into Small Language Models (SLMs) with approximately 1 billion parameters presents significant challenges. Firstly, SLMs have limited capacity in their model parameters to learn extensive knowledge compared to larger models. Secondly, high-quality conversational datasets are often scarce, small, and domain-specific. Addressing these challenges, we introduce a novel data distillation framework named CoDi (short for Conversational Distillation, pronounced "Cody"), allowing us to synthesize large-scale, assistant-style datasets in a steerable and diverse manner. Specifically, while our framework is task agnostic at its core, we explore and evaluate the potential of CoDi on the task of conversational grounded reasoning for question answering. This is a typical on-device scenario for specialist SLMs, allowing for open-domain model responses, without requiring the model to "memorize" world knowledge in its limited weights. Our evaluations show that SLMs trained with CoDi-synthesized data achieve performance comparable to models trained on human-annotated data in standard metrics. Additionally, when using our framework to generate larger datasets from web data, our models surpass larger, instruction-tuned models in zero-shot conversational grounded reasoning tasks.
Small But Funny: A Feedback-Driven Approach to Humor Distillation
Feb 28, 2024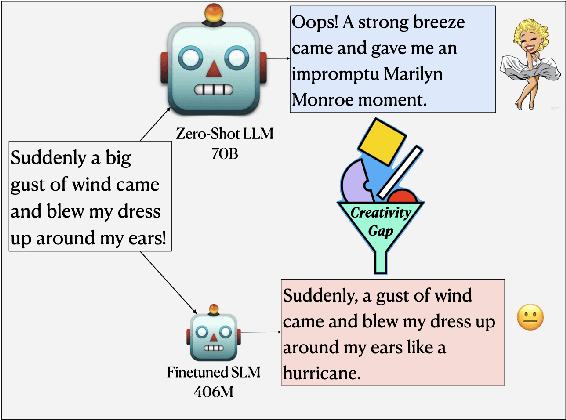



The emergence of Large Language Models (LLMs) has brought to light promising language generation capabilities, particularly in performing tasks like complex reasoning and creative writing. Consequently, distillation through imitation of teacher responses has emerged as a popular technique to transfer knowledge from LLMs to more accessible, Small Language Models (SLMs). While this works well for simpler tasks, there is a substantial performance gap on tasks requiring intricate language comprehension and creativity, such as humor generation. We hypothesize that this gap may stem from the fact that creative tasks might be hard to learn by imitation alone and explore whether an approach, involving supplementary guidance from the teacher, could yield higher performance. To address this, we study the effect of assigning a dual role to the LLM - as a "teacher" generating data, as well as a "critic" evaluating the student's performance. Our experiments on humor generation reveal that the incorporation of feedback significantly narrows the performance gap between SLMs and their larger counterparts compared to merely relying on imitation. As a result, our research highlights the potential of using feedback as an additional dimension to data when transferring complex language abilities via distillation.
Improving Faithfulness of Abstractive Summarization by Controlling Confounding Effect of Irrelevant Sentences
Dec 19, 2022



Lack of factual correctness is an issue that still plagues state-of-the-art summarization systems despite their impressive progress on generating seemingly fluent summaries. In this paper, we show that factual inconsistency can be caused by irrelevant parts of the input text, which act as confounders. To that end, we leverage information-theoretic measures of causal effects to quantify the amount of confounding and precisely quantify how they affect the summarization performance. Based on insights derived from our theoretical results, we design a simple multi-task model to control such confounding by leveraging human-annotated relevant sentences when available. Crucially, we give a principled characterization of data distributions where such confounding can be large thereby necessitating the use of human annotated relevant sentences to generate factual summaries. Our approach improves faithfulness scores by 20\% over strong baselines on AnswerSumm \citep{fabbri2021answersumm}, a conversation summarization dataset where lack of faithfulness is a significant issue due to the subjective nature of the task. Our best method achieves the highest faithfulness score while also achieving state-of-the-art results on standard metrics like ROUGE and METEOR. We corroborate these improvements through human evaluation.
A Study on the Efficiency and Generalization of Light Hybrid Retrievers
Oct 04, 2022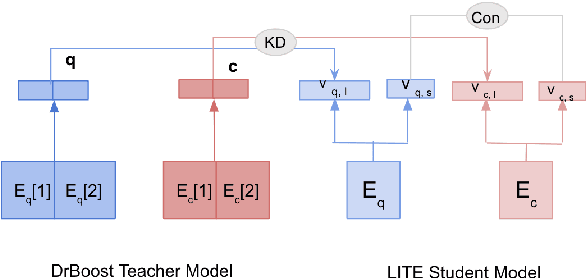
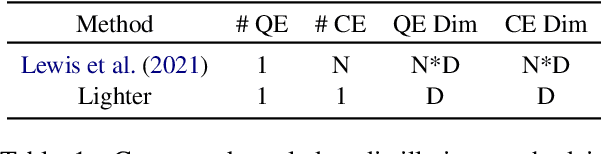
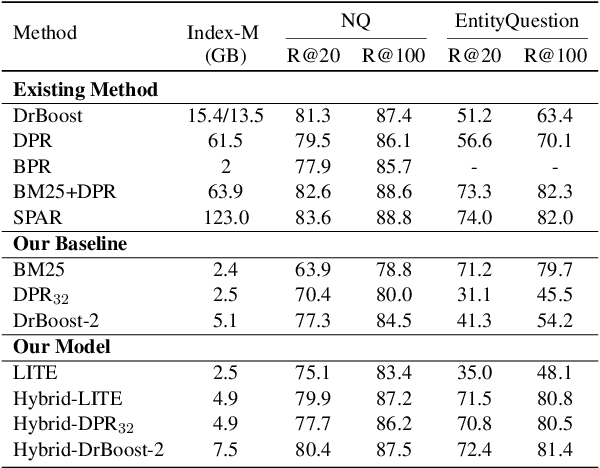
Existing hybrid retrievers which integrate sparse and dense retrievers, are indexing-heavy, limiting their applicability in real-world on-devices settings. We ask the question "Is it possible to reduce the indexing memory of hybrid retrievers without sacrificing performance?" Driven by this question, we leverage an indexing-efficient dense retriever (i.e. DrBoost) to obtain a light hybrid retriever. Moreover, to further reduce the memory, we introduce a lighter dense retriever (LITE) which is jointly trained on contrastive learning and knowledge distillation from DrBoost. Compared to previous heavy hybrid retrievers, our Hybrid-LITE retriever saves 13 memory while maintaining 98.0 performance. In addition, we study the generalization of light hybrid retrievers along two dimensions, out-of-domain (OOD) generalization and robustness against adversarial attacks. We evaluate models on two existing OOD benchmarks and create six adversarial attack sets for robustness evaluation. Experiments show that our light hybrid retrievers achieve better robustness performance than both sparse and dense retrievers. Nevertheless there is a large room to improve the robustness of retrievers, and our datasets can aid future research.
EASE: Extractive-Abstractive Summarization with Explanations
May 14, 2021
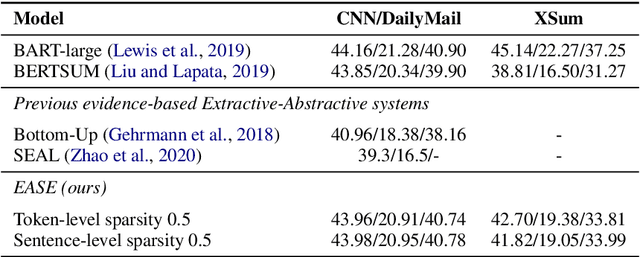
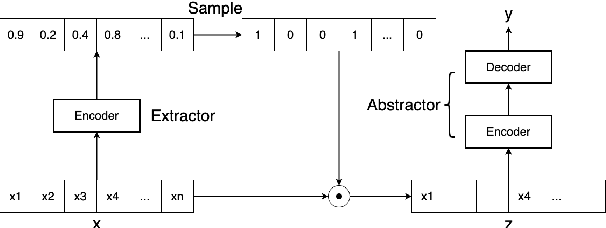
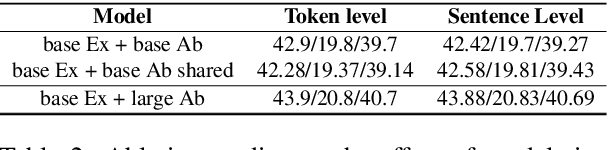
Current abstractive summarization systems outperform their extractive counterparts, but their widespread adoption is inhibited by the inherent lack of interpretability. To achieve the best of both worlds, we propose EASE, an extractive-abstractive framework for evidence-based text generation and apply it to document summarization. We present an explainable summarization system based on the Information Bottleneck principle that is jointly trained for extraction and abstraction in an end-to-end fashion. Inspired by previous research that humans use a two-stage framework to summarize long documents (Jing and McKeown, 2000), our framework first extracts a pre-defined amount of evidence spans as explanations and then generates a summary using only the evidence. Using automatic and human evaluations, we show that explanations from our framework are more relevant than simple baselines, without substantially sacrificing the quality of the generated summary.
El Volumen Louder Por Favor: Code-switching in Task-oriented Semantic Parsing
Jan 28, 2021
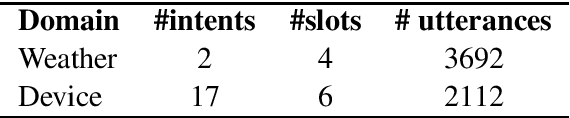
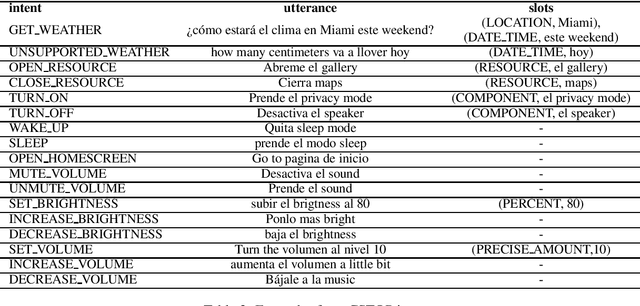
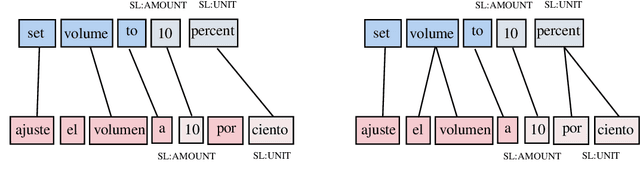
Being able to parse code-switched (CS) utterances, such as Spanish+English or Hindi+English, is essential to democratize task-oriented semantic parsing systems for certain locales. In this work, we focus on Spanglish (Spanish+English) and release a dataset, CSTOP, containing 5800 CS utterances alongside their semantic parses. We examine the CS generalizability of various Cross-lingual (XL) models and exhibit the advantage of pre-trained XL language models when data for only one language is present. As such, we focus on improving the pre-trained models for the case when only English corpus alongside either zero or a few CS training instances are available. We propose two data augmentation methods for the zero-shot and the few-shot settings: fine-tune using translate-and-align and augment using a generation model followed by match-and-filter. Combining the few-shot setting with the above improvements decreases the initial 30-point accuracy gap between the zero-shot and the full-data settings by two thirds.
Sound Natural: Content Rephrasing in Dialog Systems
Nov 03, 2020



We introduce a new task of rephrasing for a more natural virtual assistant. Currently, virtual assistants work in the paradigm of intent slot tagging and the slot values are directly passed as-is to the execution engine. However, this setup fails in some scenarios such as messaging when the query given by the user needs to be changed before repeating it or sending it to another user. For example, for queries like 'ask my wife if she can pick up the kids' or 'remind me to take my pills', we need to rephrase the content to 'can you pick up the kids' and 'take your pills' In this paper, we study the problem of rephrasing with messaging as a use case and release a dataset of 3000 pairs of original query and rephrased query. We show that BART, a pre-trained transformers-based masked language model with auto-regressive decoding, is a strong baseline for the task, and show improvements by adding a copy-pointer and copy loss to it. We analyze different tradeoffs of BART-based and LSTM-based seq2seq models, and propose a distilled LSTM-based seq2seq as the best practical model.
Likelihood Ratios and Generative Classifiers for Unsupervised Out-of-Domain Detection In Task Oriented Dialog
Dec 30, 2019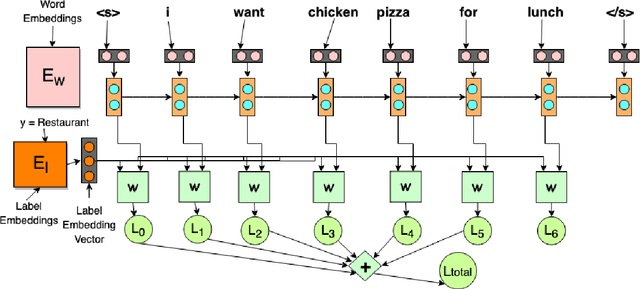


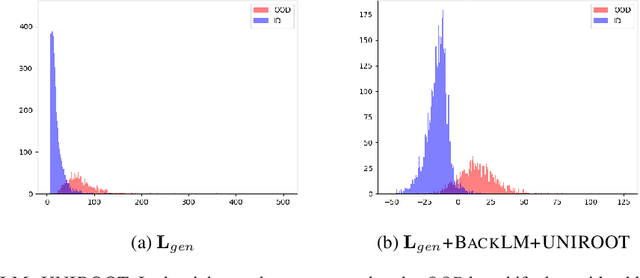
The task of identifying out-of-domain (OOD) input examples directly at test-time has seen renewed interest recently due to increased real world deployment of models. In this work, we focus on OOD detection for natural language sentence inputs to task-based dialog systems. Our findings are three-fold: First, we curate and release ROSTD (Real Out-of-Domain Sentences From Task-oriented Dialog) - a dataset of 4K OOD examples for the publicly available dataset from (Schuster et al. 2019). In contrast to existing settings which synthesize OOD examples by holding out a subset of classes, our examples were authored by annotators with apriori instructions to be out-of-domain with respect to the sentences in an existing dataset. Second, we explore likelihood ratio based approaches as an alternative to currently prevalent paradigms. Specifically, we reformulate and apply these approaches to natural language inputs. We find that they match or outperform the latter on all datasets, with larger improvements on non-artificial OOD benchmarks such as our dataset. Our ablations validate that specifically using likelihood ratios rather than plain likelihood is necessary to discriminate well between OOD and in-domain data. Third, we propose learning a generative classifier and computing a marginal likelihood (ratio) for OOD detection. This allows us to use a principled likelihood while at the same time exploiting training-time labels. We find that this approach outperforms both simple likelihood (ratio) based and other prior approaches. We are hitherto the first to investigate the use of generative classifiers for OOD detection at test-time.
Improving Robustness of Task Oriented Dialog Systems
Nov 12, 2019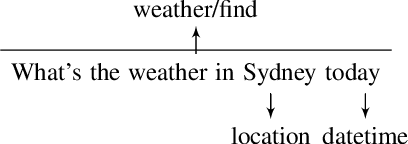



Task oriented language understanding in dialog systems is often modeled using intents (task of a query) and slots (parameters for that task). Intent detection and slot tagging are, in turn, modeled using sentence classification and word tagging techniques respectively. Similar to adversarial attack problems with computer vision models discussed in existing literature, these intent-slot tagging models are often over-sensitive to small variations in input -- predicting different and often incorrect labels when small changes are made to a query, thus reducing their accuracy and reliability. However, evaluating a model's robustness to these changes is harder for language since words are discrete and an automated change (e.g. adding `noise') to a query sometimes changes the meaning and thus labels of a query. In this paper, we first describe how to create an adversarial test set to measure the robustness of these models. Furthermore, we introduce and adapt adversarial training methods as well as data augmentation using back-translation to mitigate these issues. Our experiments show that both techniques improve the robustness of the system substantially and can be combined to yield the best results.
Improving Semantic Parsing for Task Oriented Dialog
Feb 15, 2019

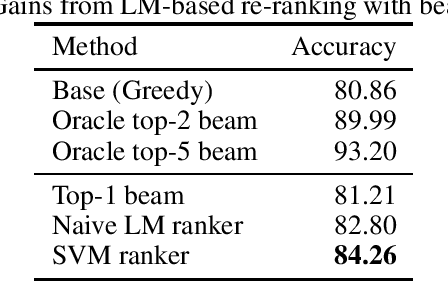
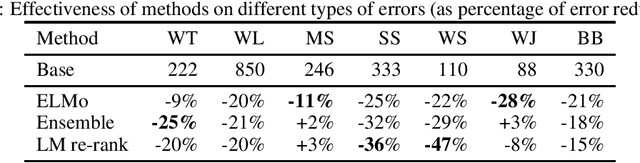
Semantic parsing using hierarchical representations has recently been proposed for task oriented dialog with promising results [Gupta et al 2018]. In this paper, we present three different improvements to the model: contextualized embeddings, ensembling, and pairwise re-ranking based on a language model. We taxonomize the errors possible for the hierarchical representation, such as wrong top intent, missing spans or split spans, and show that the three approaches correct different kinds of errors. The best model combines the three techniques and gives 6.4% better exact match accuracy than the state-of-the-art, with an error reduction of 33%, resulting in a new state-of-the-art result on the Task Oriented Parsing (TOP) dataset.