 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrusting Your Evidence: Hallucinate Less with Context-aware Decoding
May 24, 2023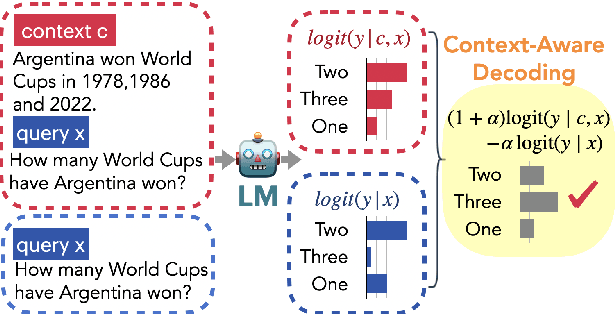

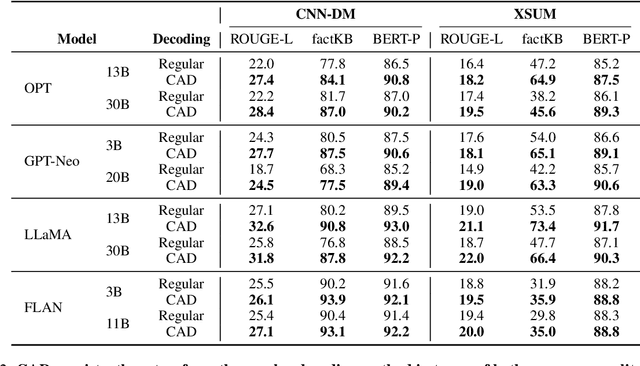
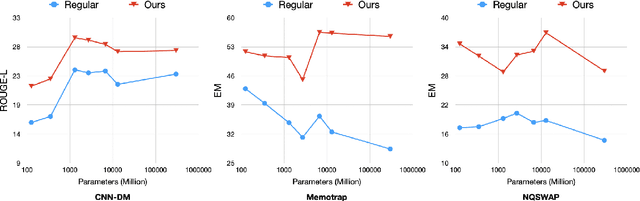
Language models (LMs) often struggle to pay enough attention to the input context, and generate texts that are unfaithful or contain hallucinations. To mitigate this issue, we present context-aware decoding (CAD), which follows a contrastive output distribution that amplifies the difference between the output probabilities when a model is used with and without context. Our experiments show that CAD, without additional training, significantly improves the faithfulness of different LM families, including OPT, GPT, LLaMA and FLAN-T5 for summarization tasks (e.g., 14.3% gain for LLaMA in factuality metrics). Furthermore, CAD is particularly effective in overriding a model's prior knowledge when it contradicts the provided context, leading to substantial improvements in tasks where resolving the knowledge conflict is essential.
Improving Faithfulness of Abstractive Summarization by Controlling Confounding Effect of Irrelevant Sentences
Dec 19, 2022



Lack of factual correctness is an issue that still plagues state-of-the-art summarization systems despite their impressive progress on generating seemingly fluent summaries. In this paper, we show that factual inconsistency can be caused by irrelevant parts of the input text, which act as confounders. To that end, we leverage information-theoretic measures of causal effects to quantify the amount of confounding and precisely quantify how they affect the summarization performance. Based on insights derived from our theoretical results, we design a simple multi-task model to control such confounding by leveraging human-annotated relevant sentences when available. Crucially, we give a principled characterization of data distributions where such confounding can be large thereby necessitating the use of human annotated relevant sentences to generate factual summaries. Our approach improves faithfulness scores by 20\% over strong baselines on AnswerSumm \citep{fabbri2021answersumm}, a conversation summarization dataset where lack of faithfulness is a significant issue due to the subjective nature of the task. Our best method achieves the highest faithfulness score while also achieving state-of-the-art results on standard metrics like ROUGE and METEOR. We corroborate these improvements through human evaluation.
DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation
Nov 18, 2022



We introduce DS-1000, a code generation benchmark with a thousand data science problems spanning seven Python libraries, such as NumPy and Pandas. Compared to prior works, DS-1000 incorporates three core features. First, our problems reflect diverse, realistic, and practical use cases since we collected them from StackOverflow. Second, our automatic evaluation is highly specific (reliable) -- across all Codex-002-predicted solutions that our evaluation accept, only 1.8% of them are incorrect; we achieve this with multi-criteria metrics, checking both functional correctness by running test cases and surface-form constraints by restricting API usages or keywords. Finally, we proactively defend against memorization by slightly modifying our problems to be different from the original StackOverflow source; consequently, models cannot answer them correctly by memorizing the solutions from pre-training. The current best public system (Codex-002) achieves 43.3% accuracy, leaving ample room for improvement. We release our benchmark at https://ds1000-code-gen.github.io.
Blockwise Self-Attention for Long Document Understanding
Nov 07, 2019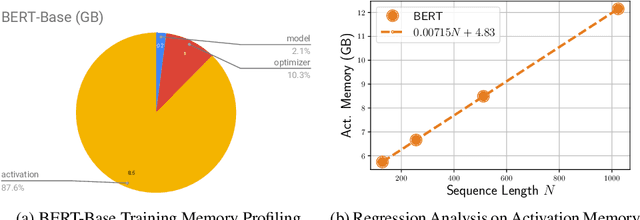

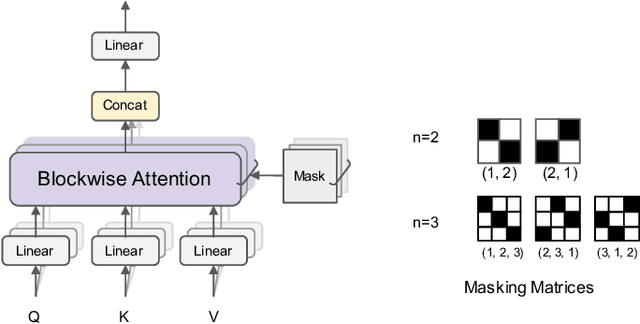
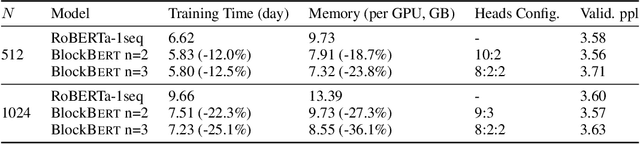
We present BlockBERT, a lightweight and efficient BERT model that is designed to better modeling long-distance dependencies. Our model extends BERT by introducing sparse block structures into the attention matrix to reduce both memory consumption and training time, which also enables attention heads to capture either short- or long-range contextual information. We conduct experiments on several benchmark question answering datasets with various paragraph lengths. Results show that BlockBERT uses 18.7-36.1% less memory and reduces the training time by 12.0-25.1%, while having comparable and sometimes better prediction accuracy, compared to an advanced BERT-based model, RoBERTa.
Abductive Commonsense Reasoning
Aug 15, 2019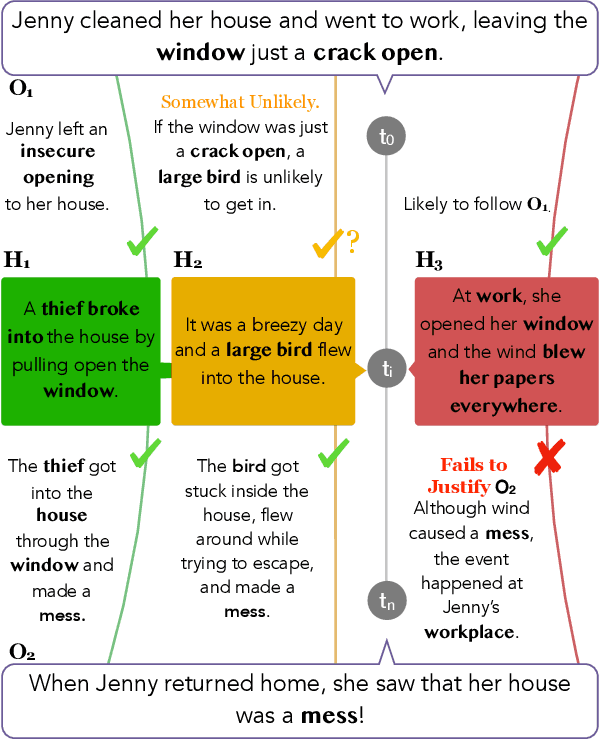
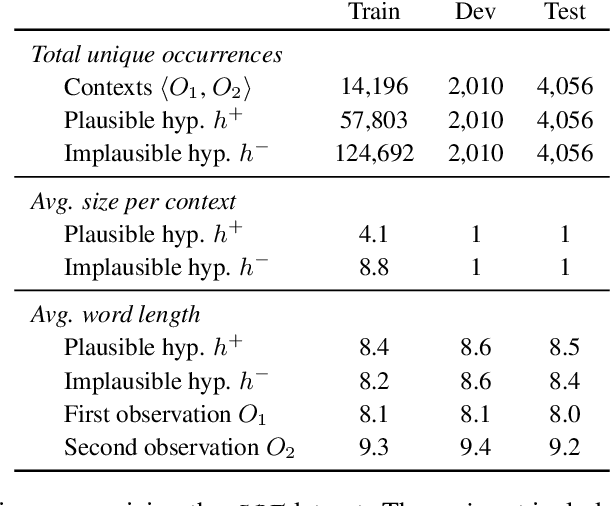

Abductive reasoning is inference to the most plausible explanation. For example, if Jenny finds her house in a mess when she returns from work, and remembers that she left a window open, she can hypothesize that a thief broke into her house and caused the mess, as the most plausible explanation. While abduction has long been considered to be at the core of how people interpret and read between the lines in natural language (Hobbs et al. (1988)), there has been relatively little NLP research in support of abductive natural language inference. We present the first study that investigates the viability of language-based abductive reasoning. We conceptualize a new task of Abductive NLI and introduce a challenge dataset, ART, that consists of over 20k commonsense narrative contexts and 200k explanations, formulated as multiple choice questions for easy automatic evaluation. We establish comprehensive baseline performance on this task based on state-of-the-art NLI and language models, which leads to 68.9% accuracy, well below human performance (91.4%). Our analysis leads to new insights into the types of reasoning that deep pre-trained language models fail to perform -- despite their strong performance on the related but fundamentally different task of entailment NLI -- pointing to interesting avenues for future research.