 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Sight, Not Out of Context? Egocentric Spatial Reasoning in VLMs Across Disjoint Frames
May 30, 2025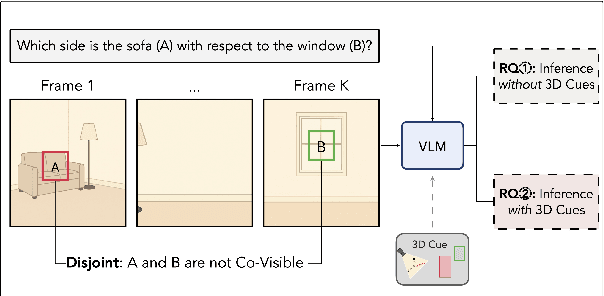

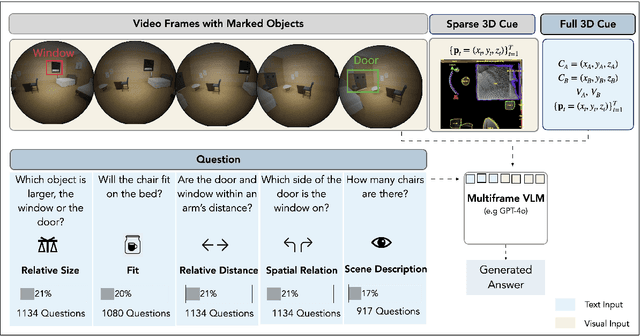

An embodied AI assistant operating on egocentric video must integrate spatial cues across time - for instance, determining where an object A, glimpsed a few moments ago lies relative to an object B encountered later. We introduce Disjoint-3DQA , a generative QA benchmark that evaluates this ability of VLMs by posing questions about object pairs that are not co-visible in the same frame. We evaluated seven state-of-the-art VLMs and found that models lag behind human performance by 28%, with steeper declines in accuracy (60% to 30 %) as the temporal gap widens. Our analysis further reveals that providing trajectories or bird's-eye-view projections to VLMs results in only marginal improvements, whereas providing oracle 3D coordinates leads to a substantial 20% performance increase. This highlights a core bottleneck of multi-frame VLMs in constructing and maintaining 3D scene representations over time from visual signals. Disjoint-3DQA therefore sets a clear, measurable challenge for long-horizon spatial reasoning and aims to catalyze future research at the intersection of vision, language, and embodied AI.
Grounding Task Assistance with Multimodal Cues from a Single Demonstration
May 02, 2025

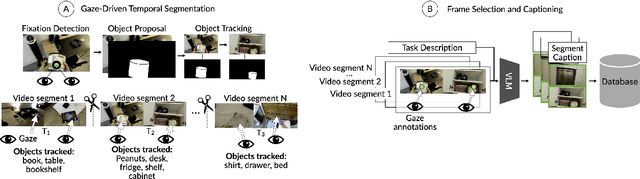
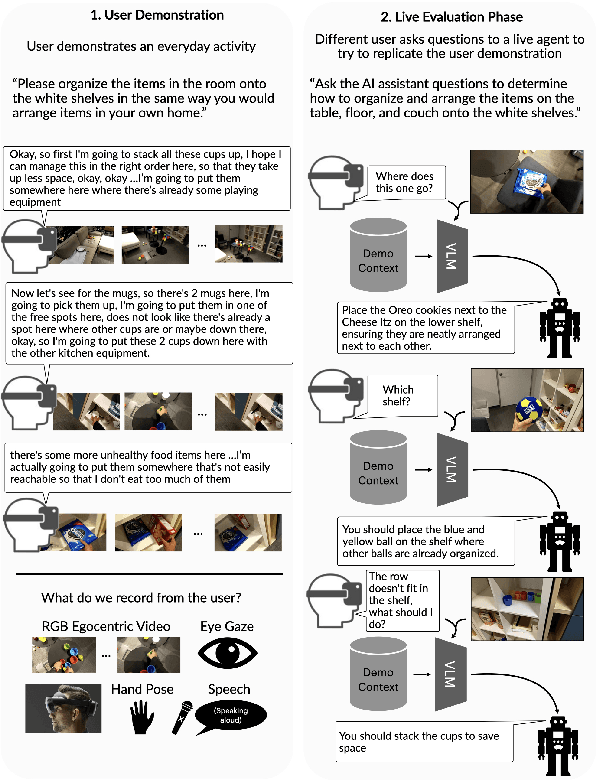
A person's demonstration often serves as a key reference for others learning the same task. However, RGB video, the dominant medium for representing these demonstrations, often fails to capture fine-grained contextual cues such as intent, safety-critical environmental factors, and subtle preferences embedded in human behavior. This sensory gap fundamentally limits the ability of Vision Language Models (VLMs) to reason about why actions occur and how they should adapt to individual users. To address this, we introduce MICA (Multimodal Interactive Contextualized Assistance), a framework that improves conversational agents for task assistance by integrating eye gaze and speech cues. MICA segments demonstrations into meaningful sub-tasks and extracts keyframes and captions that capture fine-grained intent and user-specific cues, enabling richer contextual grounding for visual question answering. Evaluations on questions derived from real-time chat-assisted task replication show that multimodal cues significantly improve response quality over frame-based retrieval. Notably, gaze cues alone achieves 93% of speech performance, and their combination yields the highest accuracy. Task type determines the effectiveness of implicit (gaze) vs. explicit (speech) cues, underscoring the need for adaptable multimodal models. These results highlight the limitations of frame-based context and demonstrate the value of multimodal signals for real-world AI task assistance.
Black Swan: Abductive and Defeasible Video Reasoning in Unpredictable Events
Dec 07, 2024



The commonsense reasoning capabilities of vision-language models (VLMs), especially in abductive reasoning and defeasible reasoning, remain poorly understood. Most benchmarks focus on typical visual scenarios, making it difficult to discern whether model performance stems from keen perception and reasoning skills, or reliance on pure statistical recall. We argue that by focusing on atypical events in videos, clearer insights can be gained on the core capabilities of VLMs. Explaining and understanding such out-of-distribution events requires models to extend beyond basic pattern recognition and regurgitation of their prior knowledge. To this end, we introduce BlackSwanSuite, a benchmark for evaluating VLMs' ability to reason about unexpected events through abductive and defeasible tasks. Our tasks artificially limit the amount of visual information provided to models while questioning them about hidden unexpected events, or provide new visual information that could change an existing hypothesis about the event. We curate a comprehensive benchmark suite comprising over 3,800 MCQ, 4,900 generative and 6,700 yes/no tasks, spanning 1,655 videos. After extensively evaluating various state-of-the-art VLMs, including GPT-4o and Gemini 1.5 Pro, as well as open-source VLMs such as LLaVA-Video, we find significant performance gaps of up to 32% from humans on these tasks. Our findings reveal key limitations in current VLMs, emphasizing the need for enhanced model architectures and training strategies.
CulturalBench: a Robust, Diverse and Challenging Benchmark on Measuring the (Lack of) Cultural Knowledge of LLMs
Oct 03, 2024



To make large language models (LLMs) more helpful across diverse cultures, it is essential to have effective cultural knowledge benchmarks to measure and track our progress. Effective benchmarks need to be robust, diverse, and challenging. We introduce CulturalBench: a set of 1,227 human-written and human-verified questions for effectively assessing LLMs' cultural knowledge, covering 45 global regions including the underrepresented ones like Bangladesh, Zimbabwe, and Peru. Questions - each verified by five independent annotators - span 17 diverse topics ranging from food preferences to greeting etiquettes. We evaluate models on two setups: CulturalBench-Easy and CulturalBench-Hard which share the same questions but asked differently. We find that LLMs are sensitive to such difference in setups (e.g., GPT-4o with 27.3% difference). Compared to human performance (92.6% accuracy), CulturalBench-Hard is more challenging for frontier LLMs with the best performing model (GPT-4o) at only 61.5% and the worst (Llama3-8b) at 21.4%. Moreover, we find that LLMs often struggle with tricky questions that have multiple correct answers (e.g., What utensils do the Chinese usually use?), revealing a tendency to converge to a single answer. Our results also indicate that OpenAI GPT-4o substantially outperform other proprietary and open source models in questions related to all but one region (Oceania). Nonetheless, all models consistently underperform on questions related to South America and the Middle East.
From Local Concepts to Universals: Evaluating the Multicultural Understanding of Vision-Language Models
Jun 28, 2024



Despite recent advancements in vision-language models, their performance remains suboptimal on images from non-western cultures due to underrepresentation in training datasets. Various benchmarks have been proposed to test models' cultural inclusivity, but they have limited coverage of cultures and do not adequately assess cultural diversity across universal as well as culture-specific local concepts. To address these limitations, we introduce the GlobalRG benchmark, comprising two challenging tasks: retrieval across universals and cultural visual grounding. The former task entails retrieving culturally diverse images for universal concepts from 50 countries, while the latter aims at grounding culture-specific concepts within images from 15 countries. Our evaluation across a wide range of models reveals that the performance varies significantly across cultures -- underscoring the necessity for enhancing multicultural understanding in vision-language models.
CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs' (Lack of) Multicultural Knowledge
Apr 10, 2024



Frontier large language models (LLMs) are developed by researchers and practitioners with skewed cultural backgrounds and on datasets with skewed sources. However, LLMs' (lack of) multicultural knowledge cannot be effectively assessed with current methods for developing benchmarks. Existing multicultural evaluations primarily rely on expensive and restricted human annotations or potentially outdated internet resources. Thus, they struggle to capture the intricacy, dynamics, and diversity of cultural norms. LLM-generated benchmarks are promising, yet risk propagating the same biases they are meant to measure. To synergize the creativity and expert cultural knowledge of human annotators and the scalability and standardizability of LLM-based automation, we introduce CulturalTeaming, an interactive red-teaming system that leverages human-AI collaboration to build truly challenging evaluation dataset for assessing the multicultural knowledge of LLMs, while improving annotators' capabilities and experiences. Our study reveals that CulturalTeaming's various modes of AI assistance support annotators in creating cultural questions, that modern LLMs fail at, in a gamified manner. Importantly, the increased level of AI assistance (e.g., LLM-generated revision hints) empowers users to create more difficult questions with enhanced perceived creativity of themselves, shedding light on the promises of involving heavier AI assistance in modern evaluation dataset creation procedures. Through a series of 1-hour workshop sessions, we gather CULTURALBENCH-V0.1, a compact yet high-quality evaluation dataset with users' red-teaming attempts, that different families of modern LLMs perform with accuracy ranging from 37.7% to 72.2%, revealing a notable gap in LLMs' multicultural proficiency.
Empowering Air Travelers: A Chatbot for Canadian Air Passenger Rights
Mar 19, 2024The Canadian air travel sector has seen a significant increase in flight delays, cancellations, and other issues concerning passenger rights. Recognizing this demand, we present a chatbot to assist passengers and educate them about their rights. Our system breaks a complex user input into simple queries which are used to retrieve information from a collection of documents detailing air travel regulations. The most relevant passages from these documents are presented along with links to the original documents and the generated queries, enabling users to dissect and leverage the information for their unique circumstances. The system successfully overcomes two predominant challenges: understanding complex user inputs, and delivering accurate answers, free of hallucinations, that passengers can rely on for making informed decisions. A user study comparing the chatbot to a Google search demonstrated the chatbot's usefulness and ease of use. Beyond the primary goal of providing accurate and timely information to air passengers regarding their rights, we hope that this system will also enable further research exploring the tradeoff between the user-friendly conversational interface of chatbots and the accuracy of retrieval systems.
Small But Funny: A Feedback-Driven Approach to Humor Distillation
Feb 28, 2024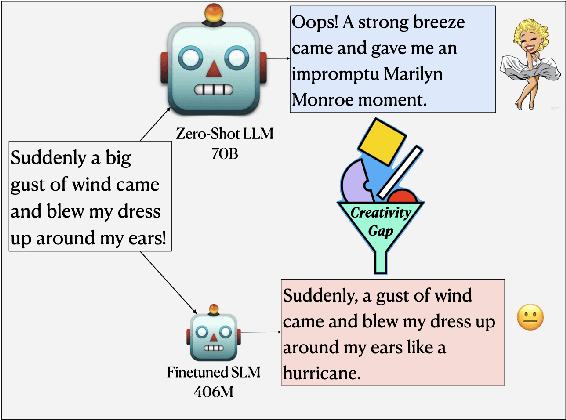



The emergence of Large Language Models (LLMs) has brought to light promising language generation capabilities, particularly in performing tasks like complex reasoning and creative writing. Consequently, distillation through imitation of teacher responses has emerged as a popular technique to transfer knowledge from LLMs to more accessible, Small Language Models (SLMs). While this works well for simpler tasks, there is a substantial performance gap on tasks requiring intricate language comprehension and creativity, such as humor generation. We hypothesize that this gap may stem from the fact that creative tasks might be hard to learn by imitation alone and explore whether an approach, involving supplementary guidance from the teacher, could yield higher performance. To address this, we study the effect of assigning a dual role to the LLM - as a "teacher" generating data, as well as a "critic" evaluating the student's performance. Our experiments on humor generation reveal that the incorporation of feedback significantly narrows the performance gap between SLMs and their larger counterparts compared to merely relying on imitation. As a result, our research highlights the potential of using feedback as an additional dimension to data when transferring complex language abilities via distillation.
CASE: Commonsense-Augmented Score with an Expanded Answer Space
Nov 03, 2023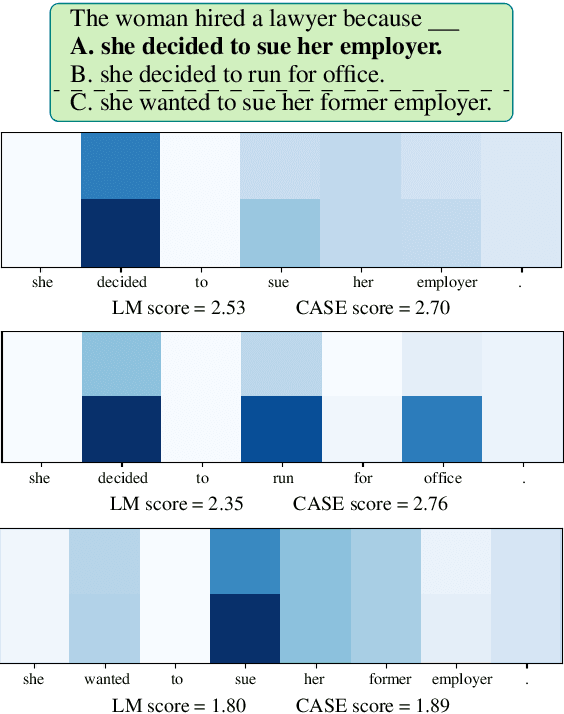
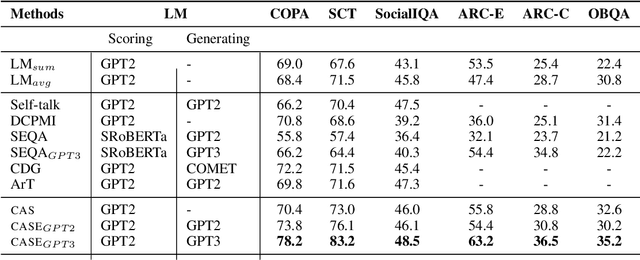
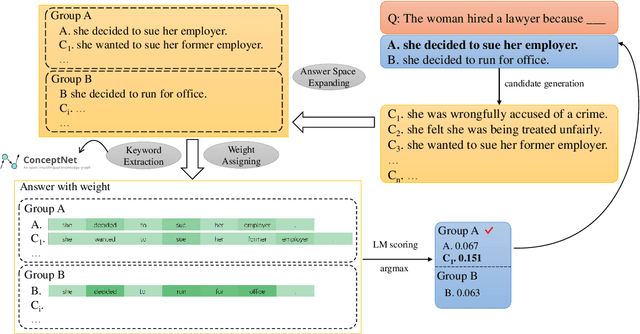
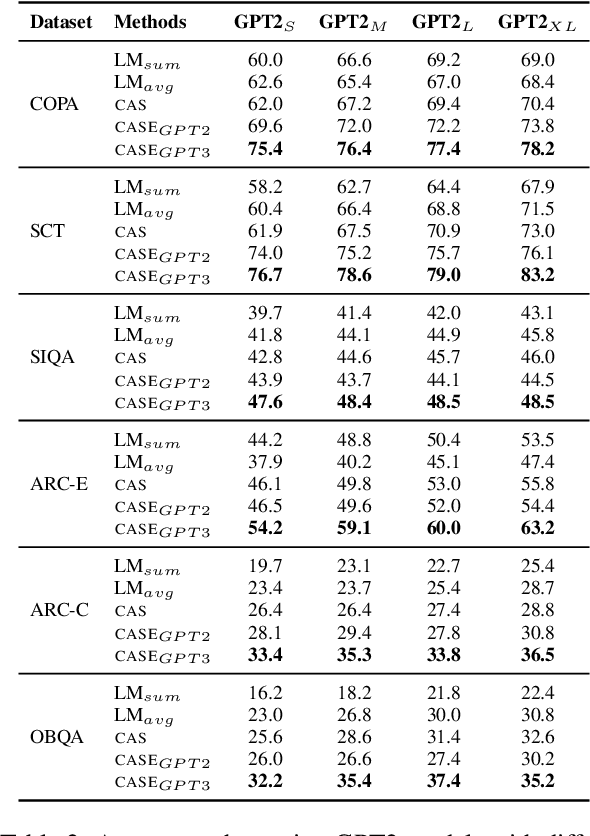
LLMs have demonstrated impressive zero-shot performance on NLP tasks thanks to the knowledge they acquired in their training. In multiple-choice QA tasks, the LM probabilities are used as an imperfect measure of the plausibility of each answer choice. One of the major limitations of the basic score is that it treats all words as equally important. We propose CASE, a Commonsense-Augmented Score with an Expanded Answer Space. CASE addresses this limitation by assigning importance weights for individual words based on their semantic relations to other words in the input. The dynamic weighting approach outperforms basic LM scores, not only because it reduces noise from unimportant words, but also because it informs the model of implicit commonsense knowledge that may be useful for answering the question. We then also follow prior work in expanding the answer space by generating lexically-divergent answers that are conceptually-similar to the choices. When combined with answer space expansion, our method outperforms strong baselines on 5 commonsense benchmarks. We further show these two approaches are complementary and may be especially beneficial when using smaller LMs.
COMET-M: Reasoning about Multiple Events in Complex Sentences
May 24, 2023Understanding the speaker's intended meaning often involves drawing commonsense inferences to reason about what is not stated explicitly. In multi-event sentences, it requires understanding the relationships between events based on contextual knowledge. We propose COMET-M (Multi-Event), an event-centric commonsense model capable of generating commonsense inferences for a target event within a complex sentence. COMET-M builds upon COMET (Bosselut et al., 2019), which excels at generating event-centric inferences for simple sentences, but struggles with the complexity of multi-event sentences prevalent in natural text. To overcome this limitation, we curate a multi-event inference dataset of 35K human-written inferences. We trained COMET-M on the human-written inferences and also created baselines using automatically labeled examples. Experimental results demonstrate the significant performance improvement of COMET-M over COMET in generating multi-event inferences. Moreover, COMET-M successfully produces distinct inferences for each target event, taking the complete context into consideration. COMET-M holds promise for downstream tasks involving natural text such as coreference resolution, dialogue, and story understanding.