 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Local Concepts to Universals: Evaluating the Multicultural Understanding of Vision-Language Models
Jun 28, 2024



Despite recent advancements in vision-language models, their performance remains suboptimal on images from non-western cultures due to underrepresentation in training datasets. Various benchmarks have been proposed to test models' cultural inclusivity, but they have limited coverage of cultures and do not adequately assess cultural diversity across universal as well as culture-specific local concepts. To address these limitations, we introduce the GlobalRG benchmark, comprising two challenging tasks: retrieval across universals and cultural visual grounding. The former task entails retrieving culturally diverse images for universal concepts from 50 countries, while the latter aims at grounding culture-specific concepts within images from 15 countries. Our evaluation across a wide range of models reveals that the performance varies significantly across cultures -- underscoring the necessity for enhancing multicultural understanding in vision-language models.
SUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Jun 07, 2024
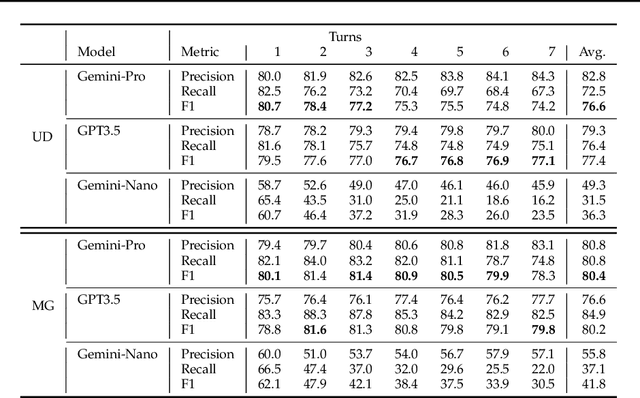
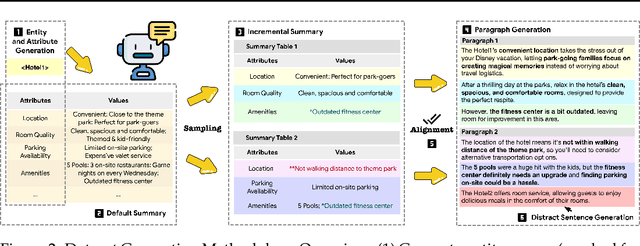
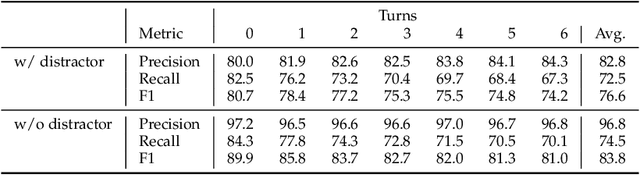
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.