 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileLLM-Flash: Latency-Guided On-Device LLM Design for Industry Scale
Mar 16, 2026Real-time AI experiences call for on-device large language models (OD-LLMs) optimized for efficient deployment on resource-constrained hardware. The most useful OD-LLMs produce near-real-time responses and exhibit broad hardware compatibility, maximizing user reach. We present a methodology for designing such models using hardware-in-the-loop architecture search under mobile latency constraints. This system is amenable to industry-scale deployment: it generates models deployable without custom kernels and compatible with standard mobile runtimes like Executorch. Our methodology avoids specialized attention mechanisms and instead uses attention skipping for long-context acceleration. Our approach jointly optimizes model architecture (layers, dimensions) and attention pattern. To efficiently evaluate candidates, we treat each as a pruned version of a pretrained backbone with inherited weights, thereby achieving high accuracy with minimal continued pretraining. We leverage the low cost of latency evaluation in a staged process: learning an accurate latency model first, then searching for the Pareto-frontier across latency and quality. This yields MobileLLM-Flash, a family of foundation models (350M, 650M, 1.4B) for efficient on-device use with strong capabilities, supporting up to 8k context length. MobileLLM-Flash delivers up to 1.8x and 1.6x faster prefill and decode on mobile CPUs with comparable or superior quality. Our analysis of Pareto-frontier design choices offers actionable principles for OD-LLM design.
Empirical Gaussian Processes
Feb 12, 2026Gaussian processes (GPs) are powerful and widely used probabilistic regression models, but their effectiveness in practice is often limited by the choice of kernel function. This kernel function is typically handcrafted from a small set of standard functions, a process that requires expert knowledge, results in limited adaptivity to data, and imposes strong assumptions on the hypothesis space. We study Empirical GPs, a principled framework for constructing flexible, data-driven GP priors that overcome these limitations. Rather than relying on standard parametric kernels, we estimate the mean and covariance functions empirically from a corpus of historical observations, enabling the prior to reflect rich, non-trivial covariance structures present in the data. Theoretically, we show that the resulting model converges to the GP that is closest (in KL-divergence sense) to the real data generating process. Practically, we formulate the problem of learning the GP prior from independent datasets as likelihood estimation and derive an Expectation-Maximization algorithm with closed-form updates, allowing the model handle heterogeneous observation locations across datasets. We demonstrate that Empirical GPs achieve competitive performance on learning curve extrapolation and time series forecasting benchmarks.
BONSAI: Bayesian Optimization with Natural Simplicity and Interpretability
Feb 06, 2026Bayesian optimization (BO) is a popular technique for sample-efficient optimization of black-box functions. In many applications, the parameters being tuned come with a carefully engineered default configuration, and practitioners only want to deviate from this default when necessary. Standard BO, however, does not aim to minimize deviation from the default and, in practice, often pushes weakly relevant parameters to the boundary of the search space. This makes it difficult to distinguish between important and spurious changes and increases the burden of vetting recommendations when the optimization objective omits relevant operational considerations. We introduce BONSAI, a default-aware BO policy that prunes low-impact deviations from a default configuration while explicitly controlling the loss in acquisition value. BONSAI is compatible with a variety of acquisition functions, including expected improvement and upper confidence bound (GP-UCB). We theoretically bound the regret incurred by BONSAI, showing that, under certain conditions, it enjoys the same no-regret property as vanilla GP-UCB. Across many real-world applications, we empirically find that BONSAI substantially reduces the number of non-default parameters in recommended configurations while maintaining competitive optimization performance, with little effect on wall time.
Scalable Gaussian Processes with Latent Kronecker Structure
Jun 07, 2025
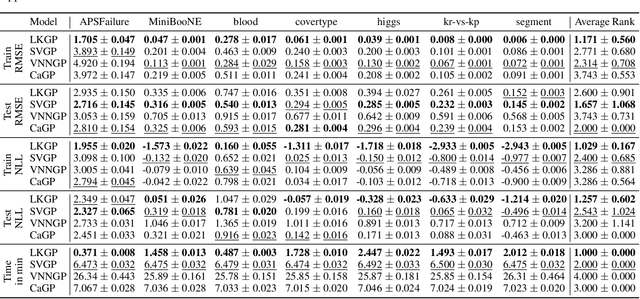
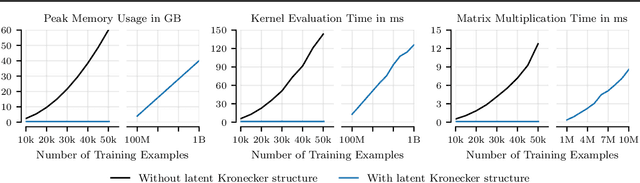
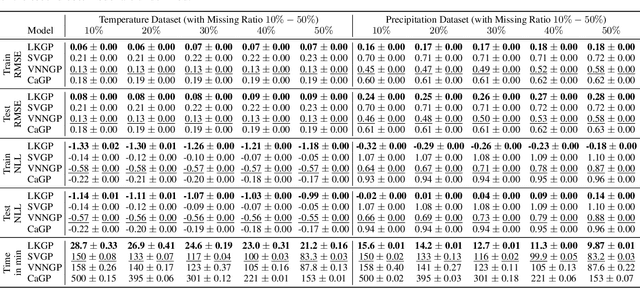
Applying Gaussian processes (GPs) to very large datasets remains a challenge due to limited computational scalability. Matrix structures, such as the Kronecker product, can accelerate operations significantly, but their application commonly entails approximations or unrealistic assumptions. In particular, the most common path to creating a Kronecker-structured kernel matrix is by evaluating a product kernel on gridded inputs that can be expressed as a Cartesian product. However, this structure is lost if any observation is missing, breaking the Cartesian product structure, which frequently occurs in real-world data such as time series. To address this limitation, we propose leveraging latent Kronecker structure, by expressing the kernel matrix of observed values as the projection of a latent Kronecker product. In combination with iterative linear system solvers and pathwise conditioning, our method facilitates inference of exact GPs while requiring substantially fewer computational resources than standard iterative methods. We demonstrate that our method outperforms state-of-the-art sparse and variational GPs on real-world datasets with up to five million examples, including robotics, automated machine learning, and climate applications.
Robust Gaussian Processes via Relevance Pursuit
Oct 31, 2024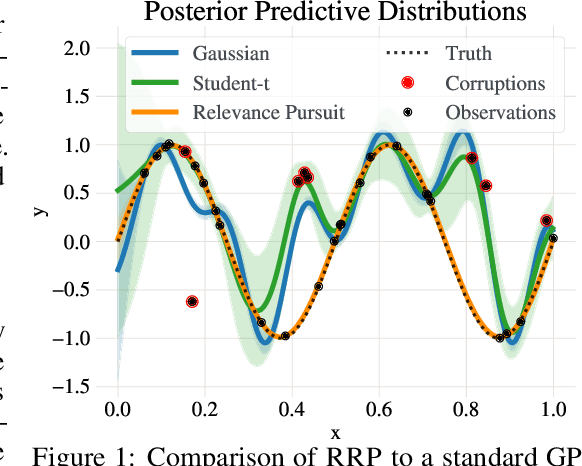
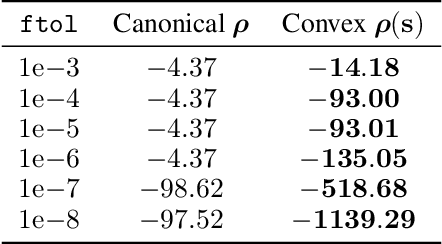
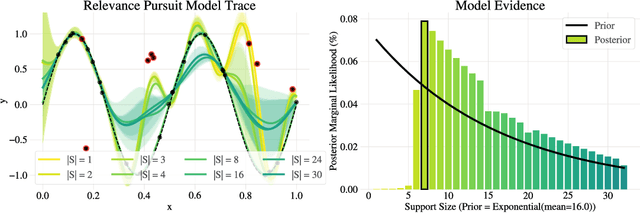
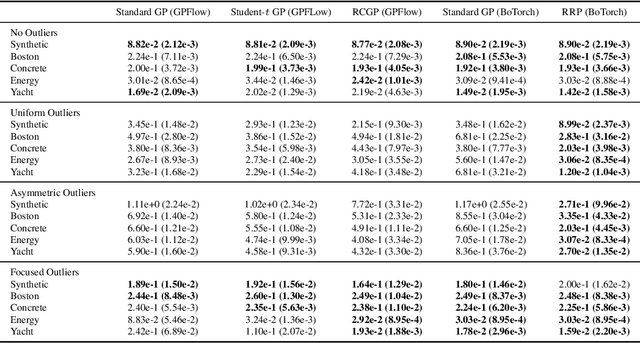
Gaussian processes (GPs) are non-parametric probabilistic regression models that are popular due to their flexibility, data efficiency, and well-calibrated uncertainty estimates. However, standard GP models assume homoskedastic Gaussian noise, while many real-world applications are subject to non-Gaussian corruptions. Variants of GPs that are more robust to alternative noise models have been proposed, and entail significant trade-offs between accuracy and robustness, and between computational requirements and theoretical guarantees. In this work, we propose and study a GP model that achieves robustness against sparse outliers by inferring data-point-specific noise levels with a sequential selection procedure maximizing the log marginal likelihood that we refer to as relevance pursuit. We show, surprisingly, that the model can be parameterized such that the associated log marginal likelihood is strongly concave in the data-point-specific noise variances, a property rarely found in either robust regression objectives or GP marginal likelihoods. This in turn implies the weak submodularity of the corresponding subset selection problem, and thereby proves approximation guarantees for the proposed algorithm. We compare the model's performance relative to other approaches on diverse regression and Bayesian optimization tasks, including the challenging but common setting of sparse corruptions of the labels within or close to the function range.
Scaling Gaussian Processes for Learning Curve Prediction via Latent Kronecker Structure
Oct 11, 2024



A key task in AutoML is to model learning curves of machine learning models jointly as a function of model hyper-parameters and training progression. While Gaussian processes (GPs) are suitable for this task, na\"ive GPs require $\mathcal{O}(n^3m^3)$ time and $\mathcal{O}(n^2 m^2)$ space for $n$ hyper-parameter configurations and $\mathcal{O}(m)$ learning curve observations per hyper-parameter. Efficient inference via Kronecker structure is typically incompatible with early-stopping due to missing learning curve values. We impose $\textit{latent Kronecker structure}$ to leverage efficient product kernels while handling missing values. In particular, we interpret the joint covariance matrix of observed values as the projection of a latent Kronecker product. Combined with iterative linear solvers and structured matrix-vector multiplication, our method only requires $\mathcal{O}(n^3 + m^3)$ time and $\mathcal{O}(n^2 + m^2)$ space. We show that our GP model can match the performance of a Transformer on a learning curve prediction task.
Accelerating Look-ahead in Bayesian Optimization: Multilevel Monte Carlo is All you Need
Feb 03, 2024We leverage multilevel Monte Carlo (MLMC) to improve the performance of multi-step look-ahead Bayesian optimization (BO) methods that involve nested expectations and maximizations. The complexity rate of naive Monte Carlo degrades for nested operations, whereas MLMC is capable of achieving the canonical Monte Carlo convergence rate for this type of problem, independently of dimension and without any smoothness assumptions. Our theoretical study focuses on the approximation improvements for one- and two-step look-ahead acquisition functions, but, as we discuss, the approach is generalizable in various ways, including beyond the context of BO. Findings are verified numerically and the benefits of MLMC for BO are illustrated on several benchmark examples. Code is available here https://github.com/Shangda-Yang/MLMCBO.
Joint Composite Latent Space Bayesian Optimization
Nov 03, 2023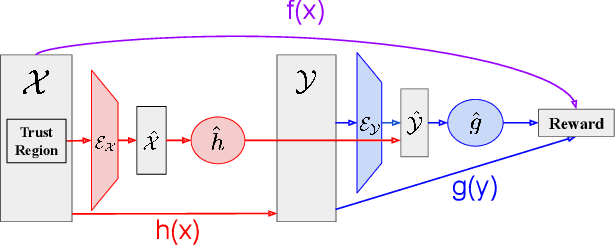
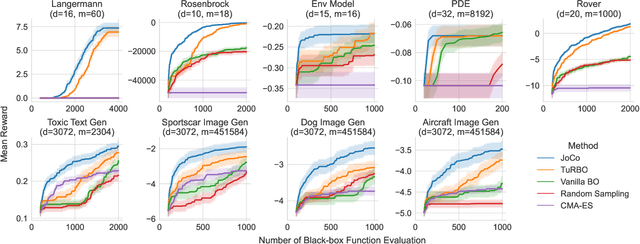


Bayesian Optimization (BO) is a technique for sample-efficient black-box optimization that employs probabilistic models to identify promising input locations for evaluation. When dealing with composite-structured functions, such as f=g o h, evaluating a specific location x yields observations of both the final outcome f(x) = g(h(x)) as well as the intermediate output(s) h(x). Previous research has shown that integrating information from these intermediate outputs can enhance BO performance substantially. However, existing methods struggle if the outputs h(x) are high-dimensional. Many relevant problems fall into this setting, including in the context of generative AI, molecular design, or robotics. To effectively tackle these challenges, we introduce Joint Composite Latent Space Bayesian Optimization (JoCo), a novel framework that jointly trains neural network encoders and probabilistic models to adaptively compress high-dimensional input and output spaces into manageable latent representations. This enables viable BO on these compressed representations, allowing JoCo to outperform other state-of-the-art methods in high-dimensional BO on a wide variety of simulated and real-world problems.
Bayesian Optimization of Function Networks with Partial Evaluations
Nov 03, 2023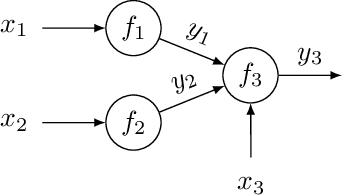
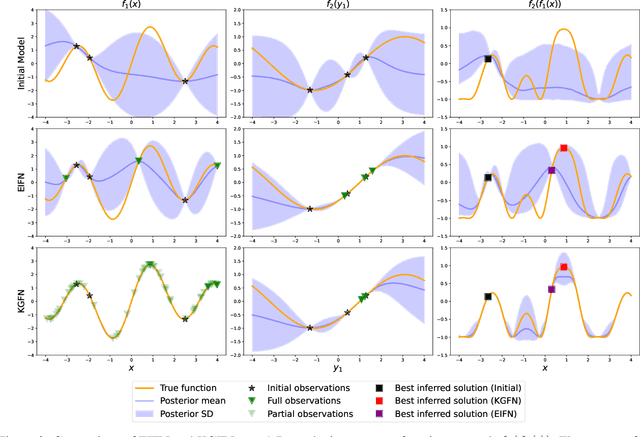

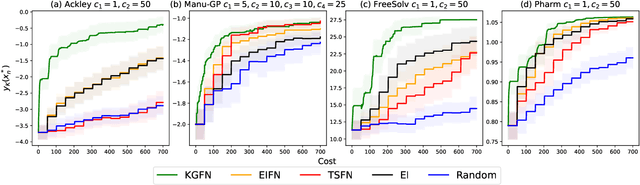
Bayesian optimization is a framework for optimizing functions that are costly or time-consuming to evaluate. Recent work has considered Bayesian optimization of function networks (BOFN), where the objective function is computed via a network of functions, each taking as input the output of previous nodes in the network and additional parameters. Exploiting this network structure has been shown to yield significant performance improvements. Existing BOFN algorithms for general-purpose networks are required to evaluate the full network at each iteration. However, many real-world applications allow evaluating nodes individually. To take advantage of this opportunity, we propose a novel knowledge gradient acquisition function for BOFN that chooses which node to evaluate as well as the inputs for that node in a cost-aware fashion. This approach can dramatically reduce query costs by allowing the evaluation of part of the network at a lower cost relative to evaluating the entire network. We provide an efficient approach to optimizing our acquisition function and show it outperforms existing BOFN methods and other benchmarks across several synthetic and real-world problems. Our acquisition function is the first to enable cost-aware optimization of a broad class of function networks.
Unexpected Improvements to Expected Improvement for Bayesian Optimization
Oct 31, 2023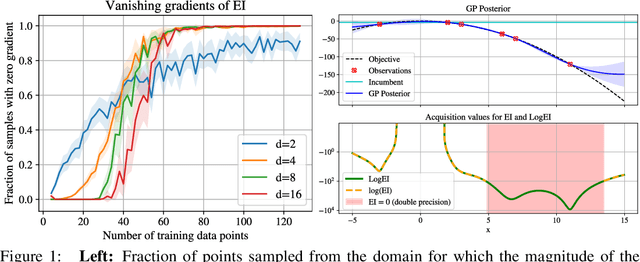

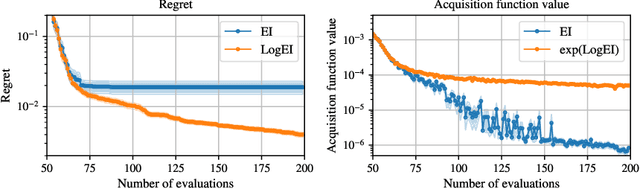
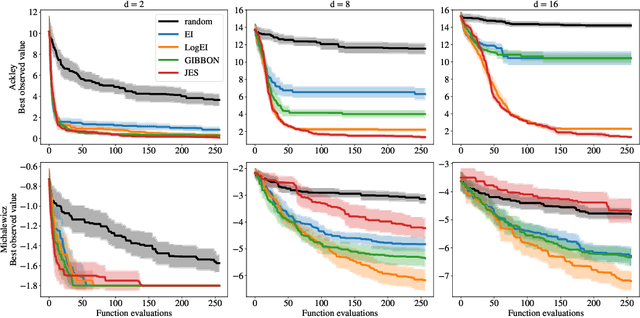
Expected Improvement (EI) is arguably the most popular acquisition function in Bayesian optimization and has found countless successful applications, but its performance is often exceeded by that of more recent methods. Notably, EI and its variants, including for the parallel and multi-objective settings, are challenging to optimize because their acquisition values vanish numerically in many regions. This difficulty generally increases as the number of observations, dimensionality of the search space, or the number of constraints grow, resulting in performance that is inconsistent across the literature and most often sub-optimal. Herein, we propose LogEI, a new family of acquisition functions whose members either have identical or approximately equal optima as their canonical counterparts, but are substantially easier to optimize numerically. We demonstrate that numerical pathologies manifest themselves in "classic" analytic EI, Expected Hypervolume Improvement (EHVI), as well as their constrained, noisy, and parallel variants, and propose corresponding reformulations that remedy these pathologies. Our empirical results show that members of the LogEI family of acquisition functions substantially improve on the optimization performance of their canonical counterparts and surprisingly, are on par with or exceed the performance of recent state-of-the-art acquisition functions, highlighting the understated role of numerical optimization in the literature.