 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?
Oct 13, 2021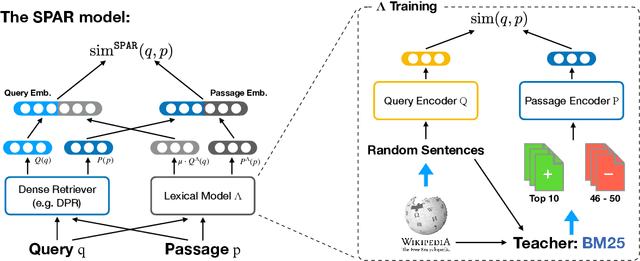
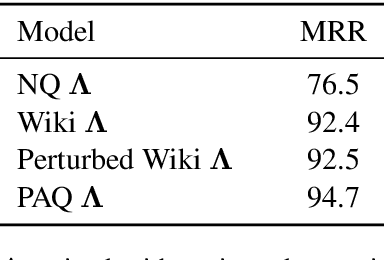
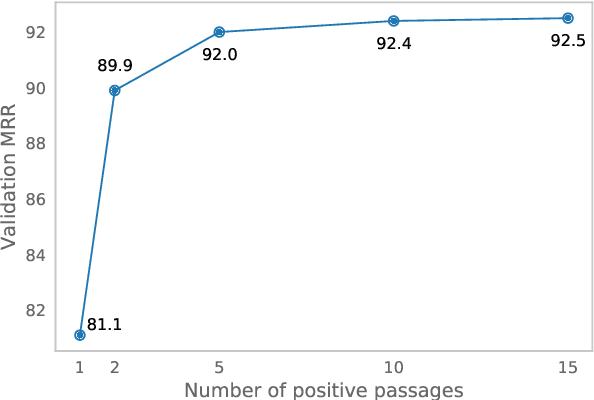
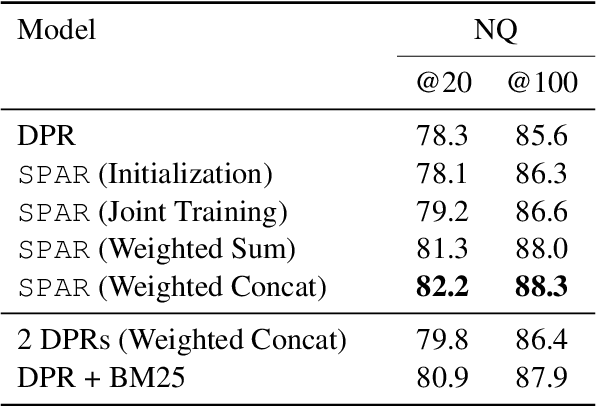
Despite their recent popularity and well known advantages, dense retrievers still lag behind sparse methods such as BM25 in their ability to reliably match salient phrases and rare entities in the query. It has been argued that this is an inherent limitation of dense models. We disprove this claim by introducing the Salient Phrase Aware Retriever (SPAR), a dense retriever with the lexical matching capacity of a sparse model. In particular, we show that a dense retriever {\Lambda} can be trained to imitate a sparse one, and SPAR is built by augmenting a standard dense retriever with {\Lambda}. When evaluated on five open-domain question answering datasets and the MS MARCO passage retrieval task, SPAR sets a new state of the art for dense and sparse retrievers and can match or exceed the performance of more complicated dense-sparse hybrid systems.
Decoupled Transformer for Scalable Inference in Open-domain Question Answering
Aug 05, 2021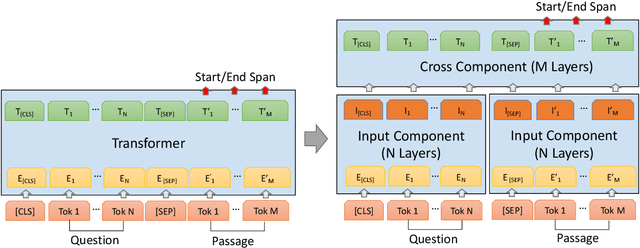
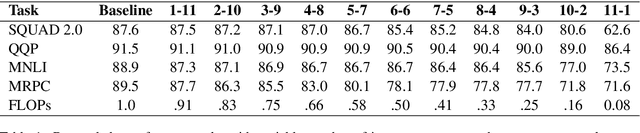
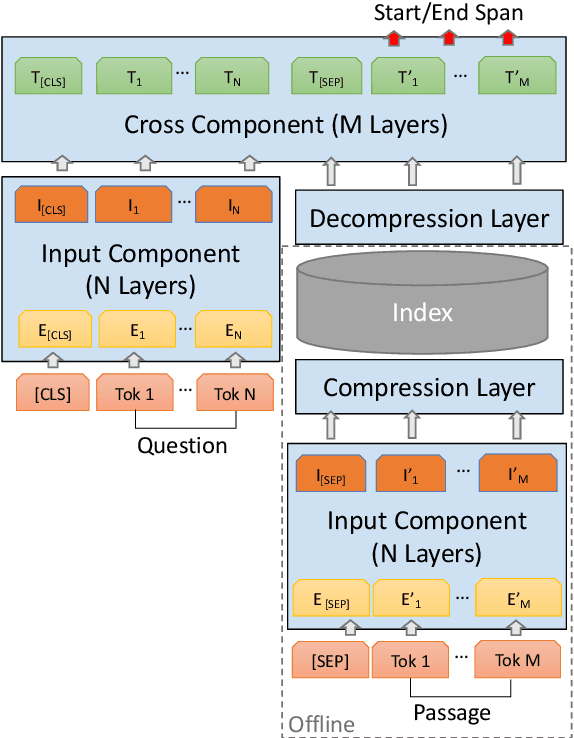
Large transformer models, such as BERT, achieve state-of-the-art results in machine reading comprehension (MRC) for open-domain question answering (QA). However, transformers have a high computational cost for inference which makes them hard to apply to online QA systems for applications like voice assistants. To reduce computational cost and latency, we propose decoupling the transformer MRC model into input-component and cross-component. The decoupling allows for part of the representation computation to be performed offline and cached for online use. To retain the decoupled transformer accuracy, we devised a knowledge distillation objective from a standard transformer model. Moreover, we introduce learned representation compression layers which help reduce by four times the storage requirement for the cache. In experiments on the SQUAD 2.0 dataset, a decoupled transformer reduces the computational cost and latency of open-domain MRC by 30-40% with only 1.2 points worse F1-score compared to a standard transformer.
Robustly Optimized and Distilled Training for Natural Language Understanding
Mar 16, 2021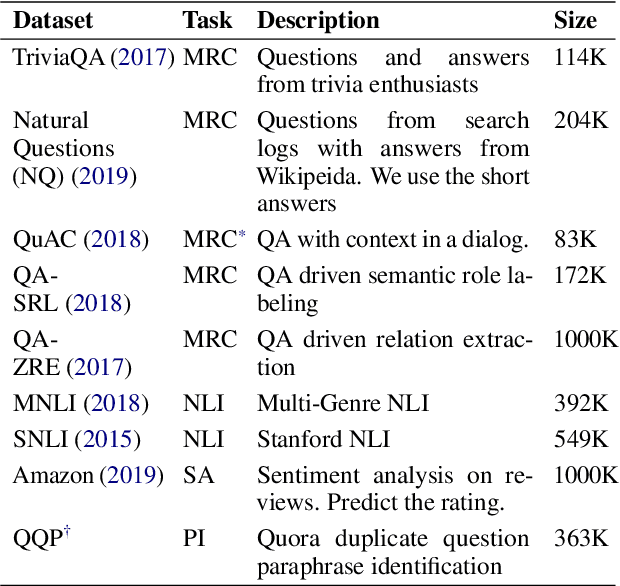
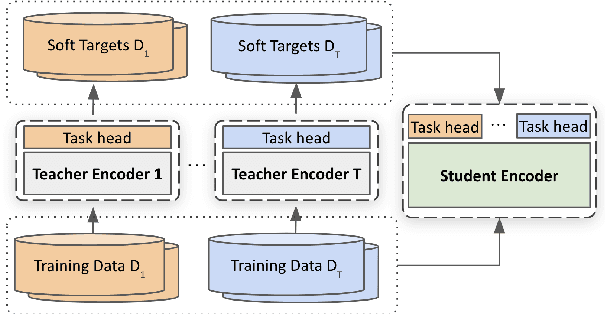
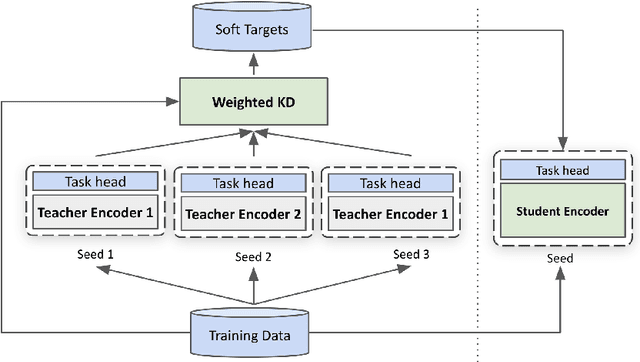
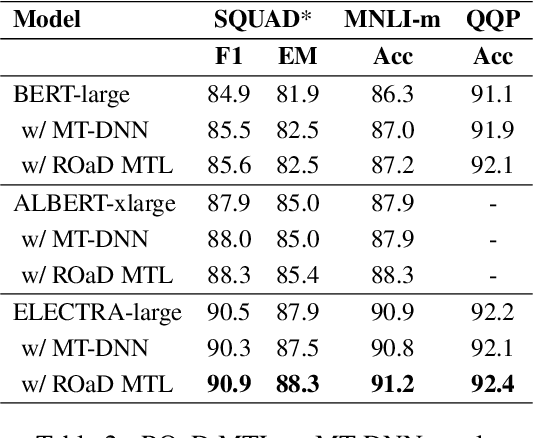
In this paper, we explore multi-task learning (MTL) as a second pretraining step to learn enhanced universal language representation for transformer language models. We use the MTL enhanced representation across several natural language understanding tasks to improve performance and generalization. Moreover, we incorporate knowledge distillation (KD) in MTL to further boost performance and devise a KD variant that learns effectively from multiple teachers. By combining MTL and KD, we propose Robustly Optimized and Distilled (ROaD) modeling framework. We use ROaD together with the ELECTRA model to obtain state-of-the-art results for machine reading comprehension and natural language inference.
Conversational Answer Generation and Factuality for Reading Comprehension Question-Answering
Mar 11, 2021
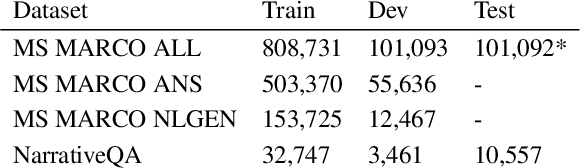
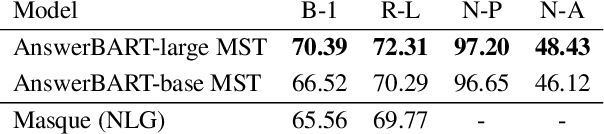
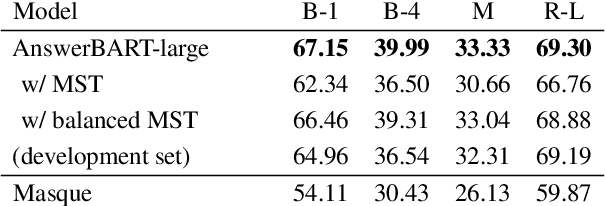
Question answering (QA) is an important use case on voice assistants. A popular approach to QA is extractive reading comprehension (RC) which finds an answer span in a text passage. However, extractive answers are often unnatural in a conversational context which results in suboptimal user experience. In this work, we investigate conversational answer generation for QA. We propose AnswerBART, an end-to-end generative RC model which combines answer generation from multiple passages with passage ranking and answerability. Moreover, a hurdle in applying generative RC are hallucinations where the answer is factually inconsistent with the passage text. We leverage recent work from summarization to evaluate factuality. Experiments show that AnswerBART significantly improves over previous best published results on MS MARCO 2.1 NLGEN by 2.5 ROUGE-L and NarrativeQA by 9.4 ROUGE-L.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021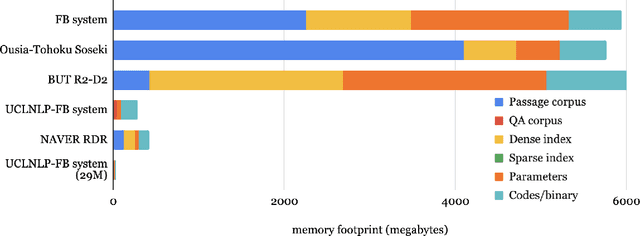
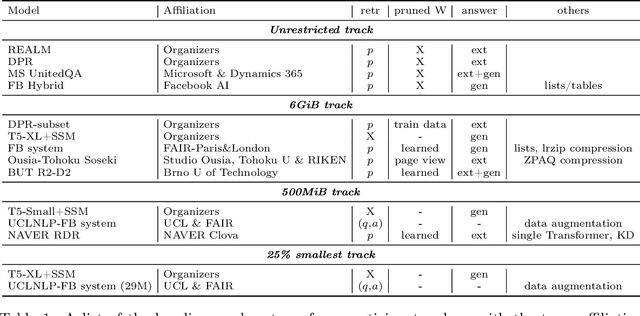
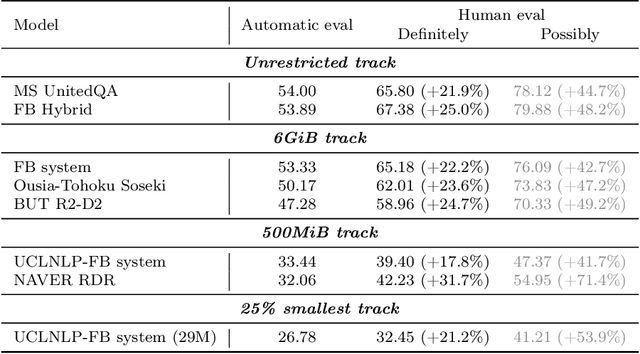
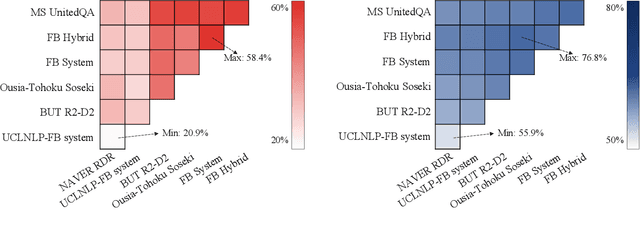
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Unified Open-Domain Question Answering with Structured and Unstructured Knowledge
Dec 29, 2020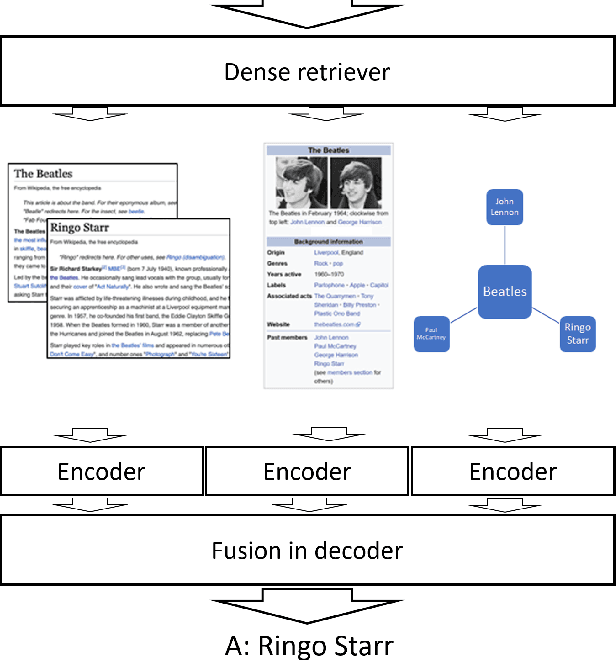

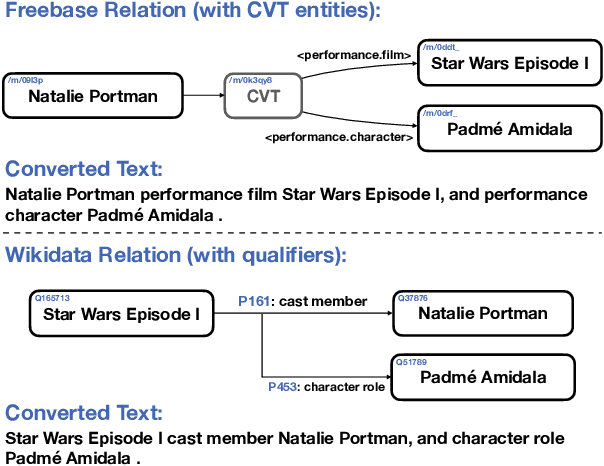
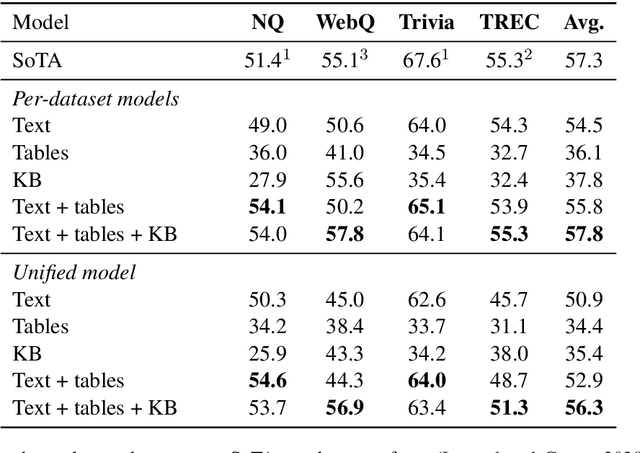
We study open-domain question answering (ODQA) with structured, unstructured and semi-structured knowledge sources, including text, tables, lists, and knowledge bases. Our approach homogenizes all sources by reducing them to text, and applies recent, powerful retriever-reader models which have so far been limited to text sources only. We show that knowledge-base QA can be greatly improved when reformulated in this way. Contrary to previous work, we find that combining sources always helps, even for datasets which target a single source by construction. As a result, our unified model produces state-of-the-art results on 3 popular ODQA benchmarks.