 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACTORY: A Challenging Human-Verified Prompt Set for Long-Form Factuality
Jul 31, 2025Long-form factuality evaluation assesses the ability of models to generate accurate, comprehensive responses to short prompts. Existing benchmarks often lack human verification, leading to potential quality issues. To address this limitation, we introduce FACTORY, a large-scale, human-verified prompt set. Developed using a model-in-the-loop approach and refined by humans, FACTORY includes challenging prompts that are fact-seeking, answerable, and unambiguous. We conduct human evaluations on 6 state-of-the-art language models using FACTORY and existing datasets. Our results show that FACTORY is a challenging benchmark: approximately 40% of the claims made in the responses of SOTA models are not factual, compared to only 10% for other datasets. Our analysis identifies the strengths of FACTORY over prior benchmarks, emphasizing its reliability and the necessity for models to reason across long-tailed facts.
In-Context Pretraining: Language Modeling Beyond Document Boundaries
Oct 20, 2023



Large language models (LMs) are currently trained to predict tokens given document prefixes, enabling them to directly perform long-form generation and prompting-style tasks which can be reduced to document completion. Existing pretraining pipelines train LMs by concatenating random sets of short documents to create input contexts but the prior documents provide no signal for predicting the next document. We instead present In-Context Pretraining, a new approach where language models are pretrained on a sequence of related documents, thereby explicitly encouraging them to read and reason across document boundaries. We can do In-Context Pretraining by simply changing the document ordering so that each context contains related documents, and directly applying existing pretraining pipelines. However, this document sorting problem is challenging. There are billions of documents and we would like the sort to maximize contextual similarity for every document without repeating any data. To do this, we introduce approximate algorithms for finding related documents with efficient nearest neighbor search and constructing coherent input contexts with a graph traversal algorithm. Our experiments show In-Context Pretraining offers a simple and scalable approach to significantly enhance LMs'performance: we see notable improvements in tasks that require more complex contextual reasoning, including in-context learning (+8%), reading comprehension (+15%), faithfulness to previous contexts (+16%), long-context reasoning (+5%), and retrieval augmentation (+9%).
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Oct 08, 2023
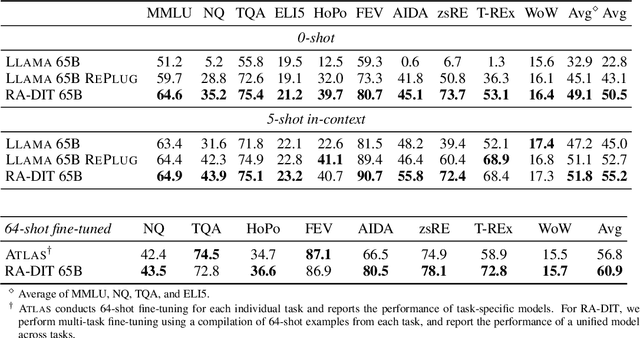
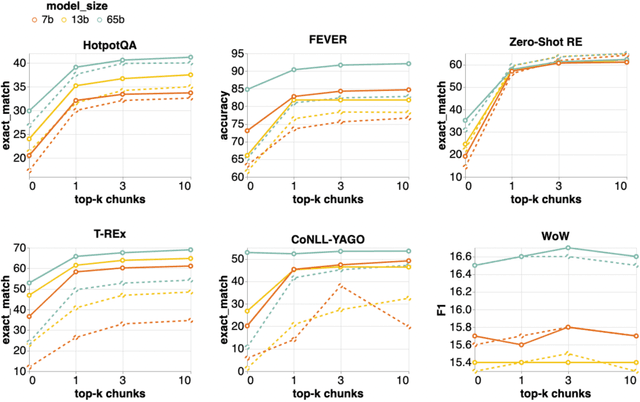
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
Reimagining Retrieval Augmented Language Models for Answering Queries
Jun 01, 2023

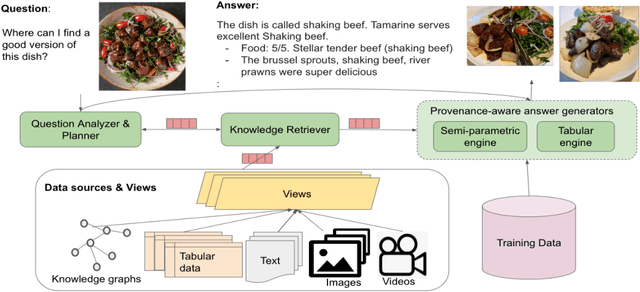
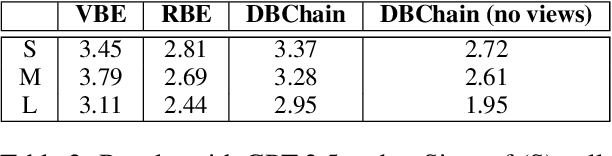
We present a reality check on large language models and inspect the promise of retrieval augmented language models in comparison. Such language models are semi-parametric, where models integrate model parameters and knowledge from external data sources to make their predictions, as opposed to the parametric nature of vanilla large language models. We give initial experimental findings that semi-parametric architectures can be enhanced with views, a query analyzer/planner, and provenance to make a significantly more powerful system for question answering in terms of accuracy and efficiency, and potentially for other NLP tasks
BiT: Robustly Binarized Multi-distilled Transformer
May 25, 2022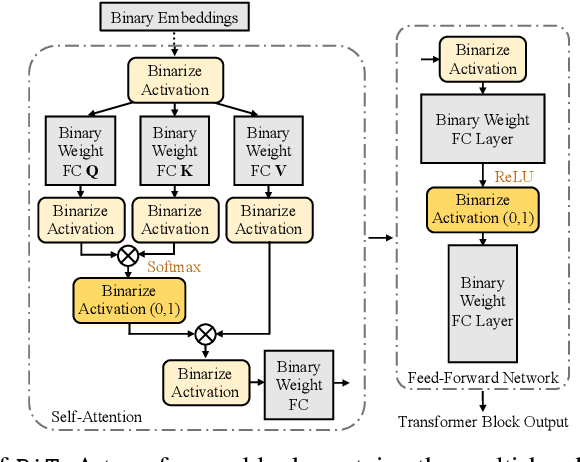
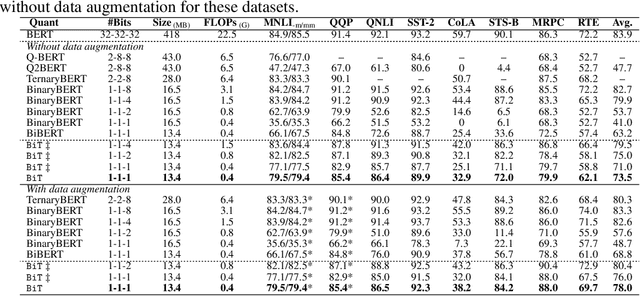

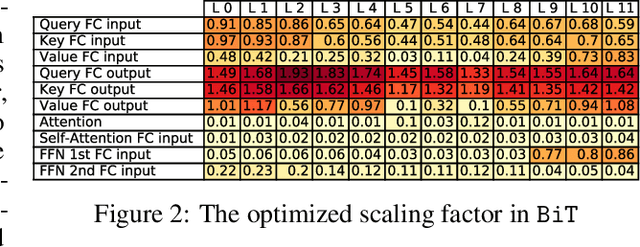
Modern pre-trained transformers have rapidly advanced the state-of-the-art in machine learning, but have also grown in parameters and computational complexity, making them increasingly difficult to deploy in resource-constrained environments. Binarization of the weights and activations of the network can significantly alleviate these issues, however is technically challenging from an optimization perspective. In this work, we identify a series of improvements which enables binary transformers at a much higher accuracy than what was possible previously. These include a two-set binarization scheme, a novel elastic binary activation function with learned parameters, and a method to quantize a network to its limit by successively distilling higher precision models into lower precision students. These approaches allow for the first time, fully binarized transformer models that are at a practical level of accuracy, approaching a full-precision BERT baseline on the GLUE language understanding benchmark within as little as 5.9%.
Unified Open-Domain Question Answering with Structured and Unstructured Knowledge
Dec 29, 2020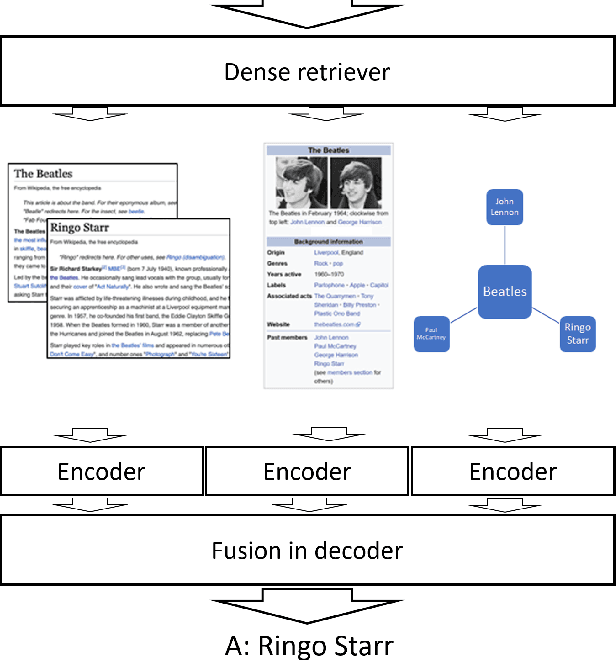

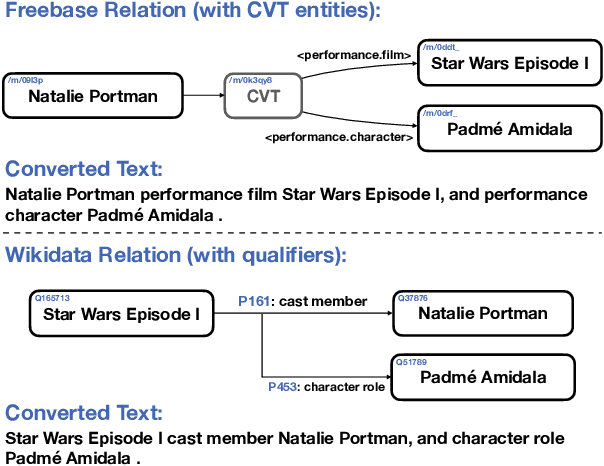
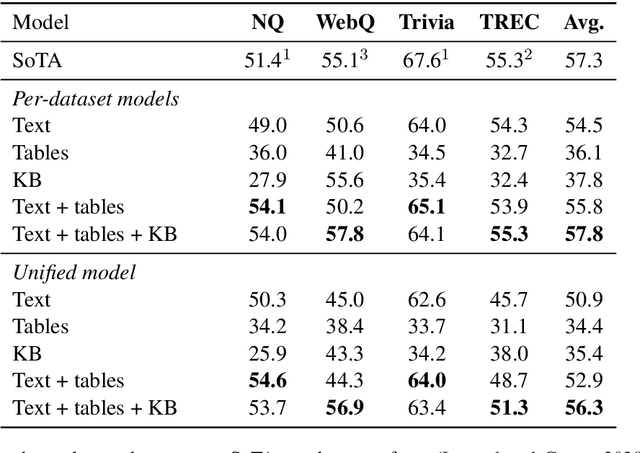
We study open-domain question answering (ODQA) with structured, unstructured and semi-structured knowledge sources, including text, tables, lists, and knowledge bases. Our approach homogenizes all sources by reducing them to text, and applies recent, powerful retriever-reader models which have so far been limited to text sources only. We show that knowledge-base QA can be greatly improved when reformulated in this way. Contrary to previous work, we find that combining sources always helps, even for datasets which target a single source by construction. As a result, our unified model produces state-of-the-art results on 3 popular ODQA benchmarks.