 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegoNN: Building Modular Encoder-Decoder Models
Jun 07, 2022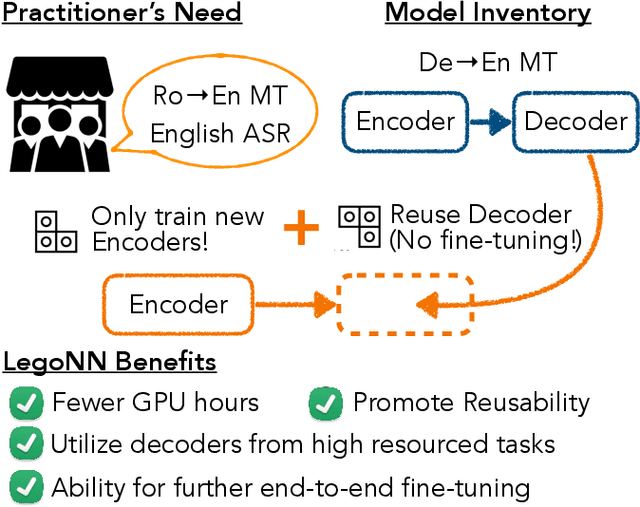
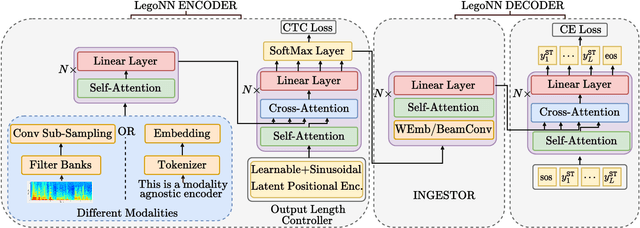
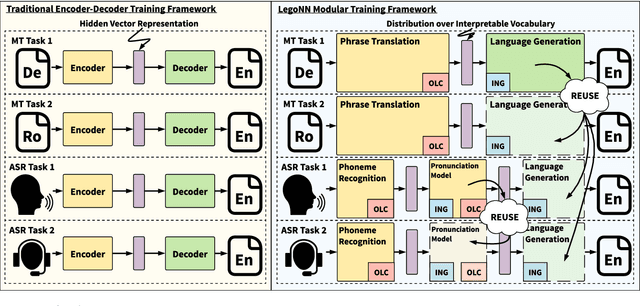
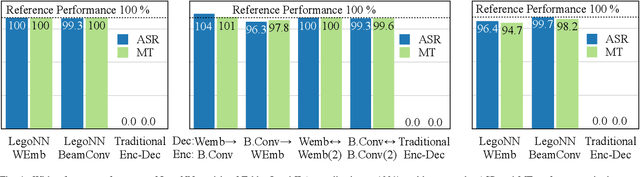
State-of-the-art encoder-decoder models (e.g. for machine translation (MT) or speech recognition (ASR)) are constructed and trained end-to-end as an atomic unit. No component of the model can be (re-)used without the others. We describe LegoNN, a procedure for building encoder-decoder architectures with decoder modules that can be reused across various MT and ASR tasks, without the need for any fine-tuning. To achieve reusability, the interface between each encoder and decoder modules is grounded to a sequence of marginal distributions over a discrete vocabulary pre-defined by the model designer. We present two approaches for ingesting these marginals; one is differentiable, allowing the flow of gradients across the entire network, and the other is gradient-isolating. To enable portability of decoder modules between MT tasks for different source languages and across other tasks like ASR, we introduce a modality agnostic encoder which consists of a length control mechanism to dynamically adapt encoders' output lengths in order to match the expected input length range of pre-trained decoders. We present several experiments to demonstrate the effectiveness of LegoNN models: a trained language generation LegoNN decoder module from German-English (De-En) MT task can be reused with no fine-tuning for the Europarl English ASR and the Romanian-English (Ro-En) MT tasks to match or beat respective baseline models. When fine-tuned towards the target task for few thousand updates, our LegoNN models improved the Ro-En MT task by 1.5 BLEU points, and achieved 12.5% relative WER reduction for the Europarl ASR task. Furthermore, to show its extensibility, we compose a LegoNN ASR model from three modules -- each has been learned within different end-to-end trained models on three different datasets -- boosting the WER reduction to 19.5%.
CM3: A Causal Masked Multimodal Model of the Internet
Jan 19, 2022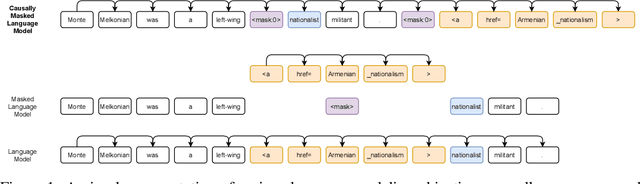
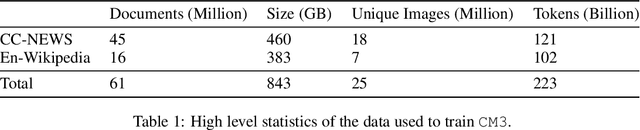
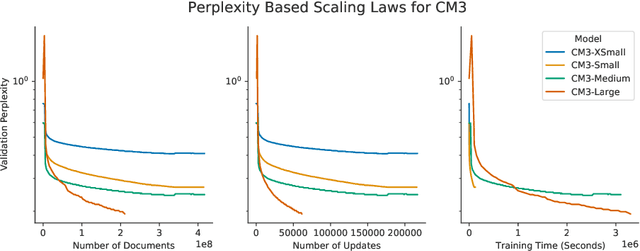
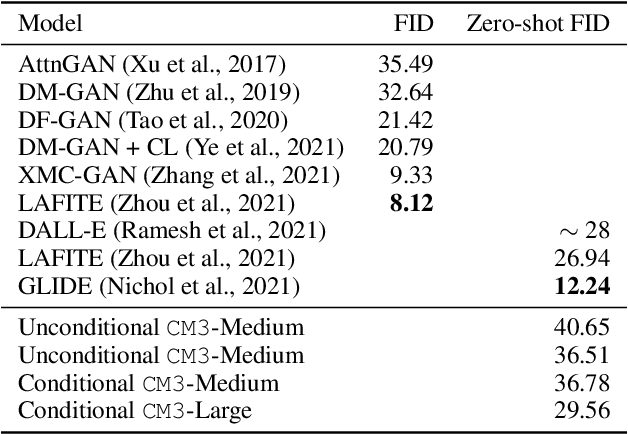
We introduce CM3, a family of causally masked generative models trained over a large corpus of structured multi-modal documents that can contain both text and image tokens. Our new causally masked approach generates tokens left to right while also masking out a small number of long token spans that are generated at the end of the string, instead of their original positions. The casual masking object provides a type of hybrid of the more common causal and masked language models, by enabling full generative modeling while also providing bidirectional context when generating the masked spans. We train causally masked language-image models on large-scale web and Wikipedia articles, where each document contains all of the text, hypertext markup, hyperlinks, and image tokens (from a VQVAE-GAN), provided in the order they appear in the original HTML source (before masking). The resulting CM3 models can generate rich structured, multi-modal outputs while conditioning on arbitrary masked document contexts, and thereby implicitly learn a wide range of text, image, and cross modal tasks. They can be prompted to recover, in a zero-shot fashion, the functionality of models such as DALL-E, GENRE, and HTLM. We set the new state-of-the-art in zero-shot summarization, entity linking, and entity disambiguation while maintaining competitive performance in the fine-tuning setting. We can generate images unconditionally, conditioned on text (like DALL-E) and do captioning all in a zero-shot setting with a single model.
The Web Is Your Oyster -- Knowledge-Intensive NLP against a Very Large Web Corpus
Dec 18, 2021
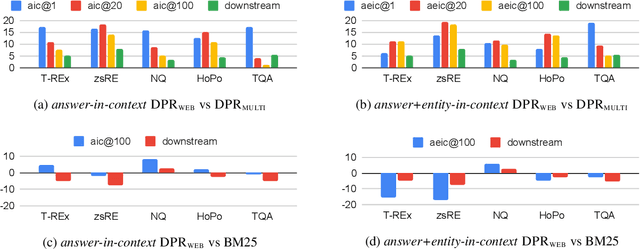
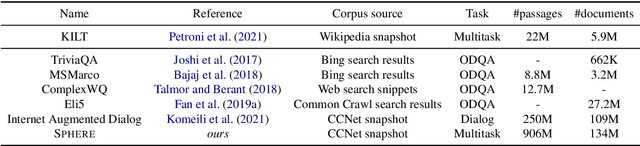
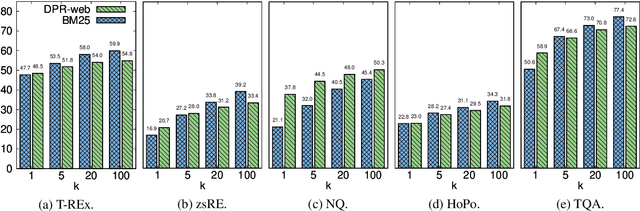
In order to address the increasing demands of real-world applications, the research for knowledge-intensive NLP (KI-NLP) should advance by capturing the challenges of a truly open-domain environment: web scale knowledge, lack of structure, inconsistent quality, and noise. To this end, we propose a new setup for evaluating existing KI-NLP tasks in which we generalize the background corpus to a universal web snapshot. We repurpose KILT, a standard KI-NLP benchmark initially developed for Wikipedia, and ask systems to use a subset of CCNet - the Sphere corpus - as a knowledge source. In contrast to Wikipedia, Sphere is orders of magnitude larger and better reflects the full diversity of knowledge on the Internet. We find that despite potential gaps of coverage, challenges of scale, lack of structure and lower quality, retrieval from Sphere enables a state-of-the-art retrieve-and-read system to match and even outperform Wikipedia-based models on several KILT tasks - even if we aggressively filter content that looks like Wikipedia. We also observe that while a single dense passage index over Wikipedia can outperform a sparse BM25 version, on Sphere this is not yet possible. To facilitate further research into this area, and minimise the community's reliance on proprietary black box search engines, we will share our indices, evaluation metrics and infrastructure.
CCQA: A New Web-Scale Question Answering Dataset for Model Pre-Training
Oct 14, 2021



With the rise of large-scale pre-trained language models, open-domain question-answering (ODQA) has become an important research topic in NLP. Based on the popular pre-training fine-tuning approach, we posit that an additional in-domain pre-training stage using a large-scale, natural, and diverse question-answering (QA) dataset can be beneficial for ODQA. Consequently, we propose a novel QA dataset based on the Common Crawl project in this paper. Using the readily available schema.org annotation, we extract around 130 million multilingual question-answer pairs, including about 60 million English data-points. With this previously unseen number of natural QA pairs, we pre-train popular language models to show the potential of large-scale in-domain pre-training for the task of question-answering. In our experiments, we find that pre-training question-answering models on our Common Crawl Question Answering dataset (CCQA) achieves promising results in zero-shot, low resource and fine-tuned settings across multiple tasks, models and benchmarks.
VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding
Oct 01, 2021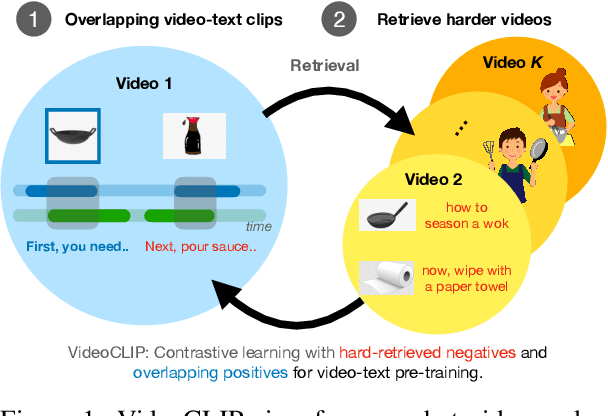
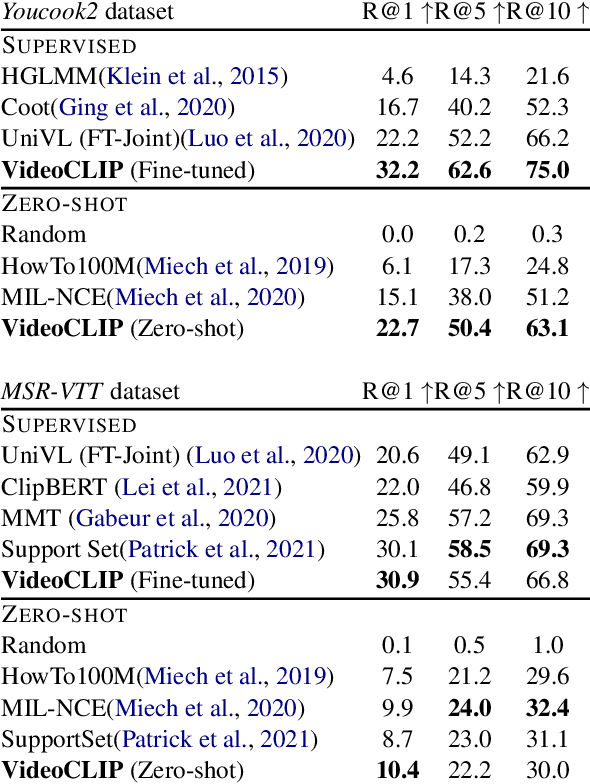
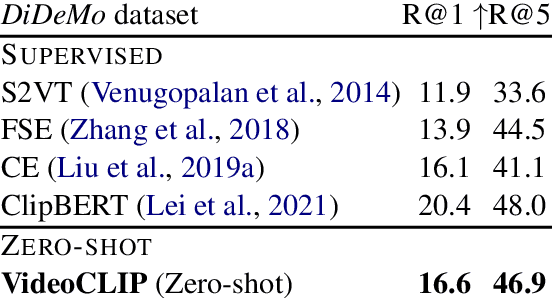
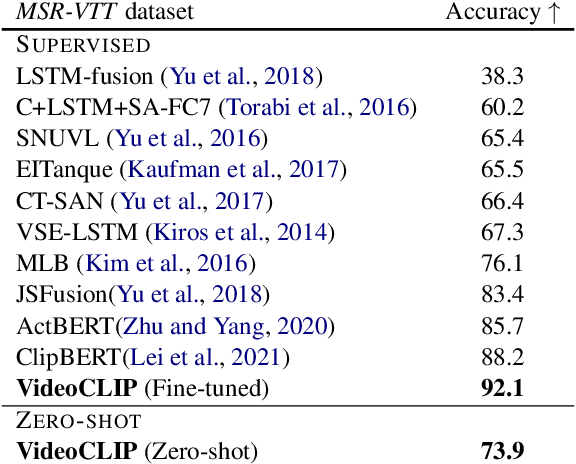
We present VideoCLIP, a contrastive approach to pre-train a unified model for zero-shot video and text understanding, without using any labels on downstream tasks. VideoCLIP trains a transformer for video and text by contrasting temporally overlapping positive video-text pairs with hard negatives from nearest neighbor retrieval. Our experiments on a diverse series of downstream tasks, including sequence-level text-video retrieval, VideoQA, token-level action localization, and action segmentation reveal state-of-the-art performance, surpassing prior work, and in some cases even outperforming supervised approaches. Code is made available at https://github.com/pytorch/fairseq/tree/main/examples/MMPT.
HTLM: Hyper-Text Pre-Training and Prompting of Language Models
Jul 14, 2021



We introduce HTLM, a hyper-text language model trained on a large-scale web crawl. Modeling hyper-text has a number of advantages: (1) it is easily gathered at scale, (2) it provides rich document-level and end-task-adjacent supervision (e.g. class and id attributes often encode document category information), and (3) it allows for new structured prompting that follows the established semantics of HTML (e.g. to do zero-shot summarization by infilling title tags for a webpage that contains the input text). We show that pretraining with a BART-style denoising loss directly on simplified HTML provides highly effective transfer for a wide range of end tasks and supervision levels. HTLM matches or exceeds the performance of comparably sized text-only LMs for zero-shot prompting and fine-tuning for classification benchmarks, while also setting new state-of-the-art performance levels for zero-shot summarization. We also find that hyper-text prompts provide more value to HTLM, in terms of data efficiency, than plain text prompts do for existing LMs, and that HTLM is highly effective at auto-prompting itself, by simply generating the most likely hyper-text formatting for any available training data. We will release all code and models to support future HTLM research.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021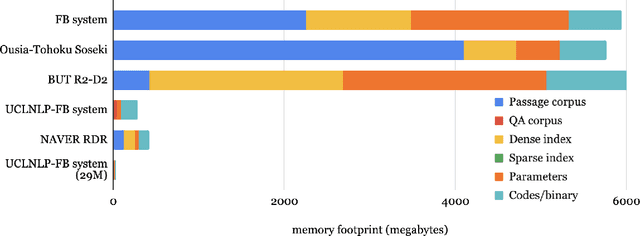
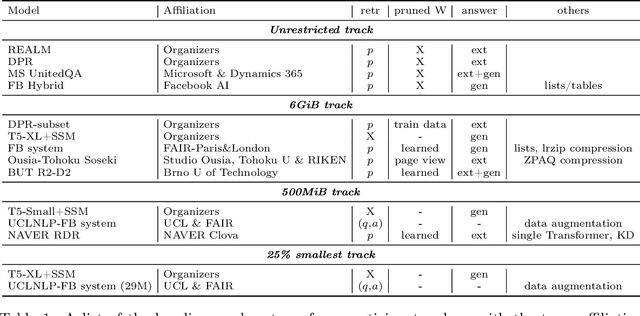
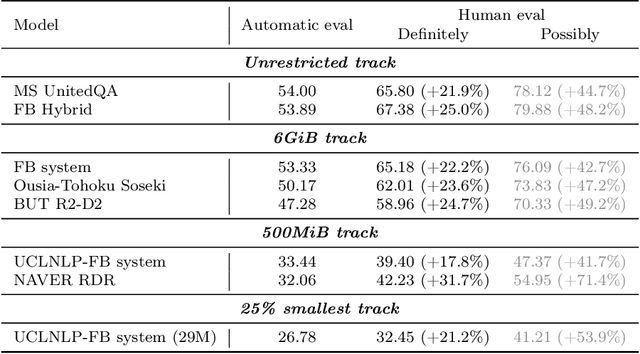
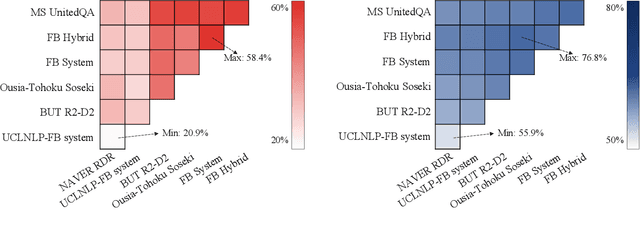
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Unified Open-Domain Question Answering with Structured and Unstructured Knowledge
Dec 29, 2020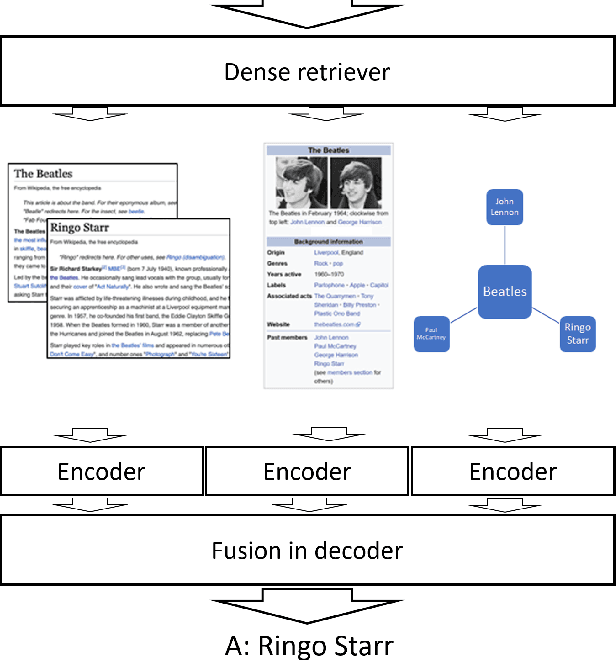

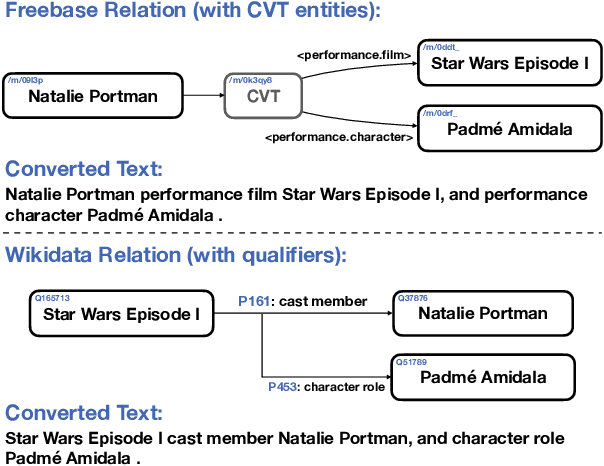
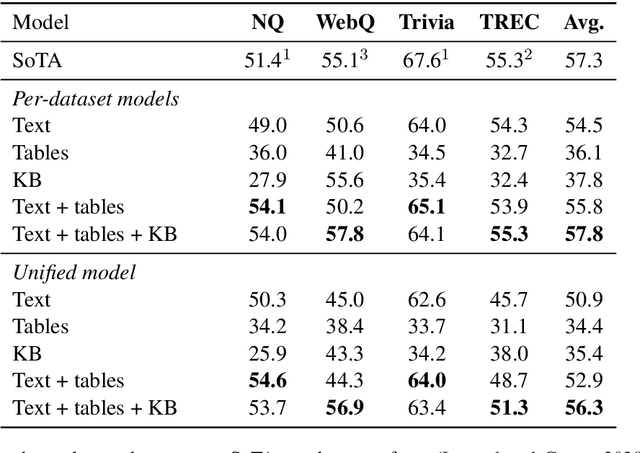
We study open-domain question answering (ODQA) with structured, unstructured and semi-structured knowledge sources, including text, tables, lists, and knowledge bases. Our approach homogenizes all sources by reducing them to text, and applies recent, powerful retriever-reader models which have so far been limited to text sources only. We show that knowledge-base QA can be greatly improved when reformulated in this way. Contrary to previous work, we find that combining sources always helps, even for datasets which target a single source by construction. As a result, our unified model produces state-of-the-art results on 3 popular ODQA benchmarks.
fairseq S2T: Fast Speech-to-Text Modeling with fairseq
Oct 11, 2020
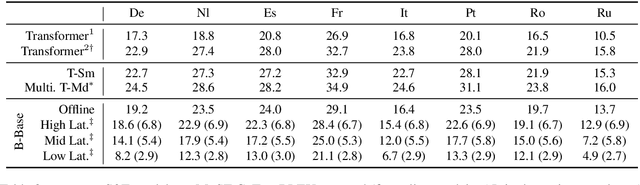

We introduce fairseq S2T, a fairseq extension for speech-to-text (S2T) modeling tasks such as end-to-end speech recognition and speech-to-text translation. It follows fairseq's careful design for scalability and extensibility. We provide end-to-end workflows from data pre-processing, model training to offline (online) inference. We implement state-of-the-art RNN-based as well as Transformer-based models and open-source detailed training recipes. Fairseq's machine translation models and language models can be seamlessly integrated into S2T workflows for multi-task learning or transfer learning. Fairseq S2T documentation and examples are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text.
Training ASR models by Generation of Contextual Information
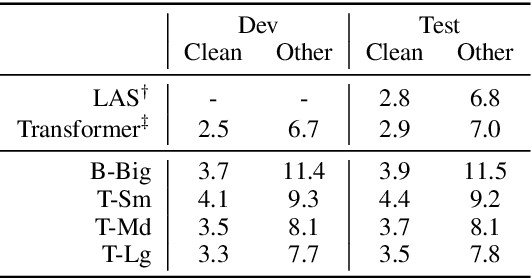
Oct 27, 2019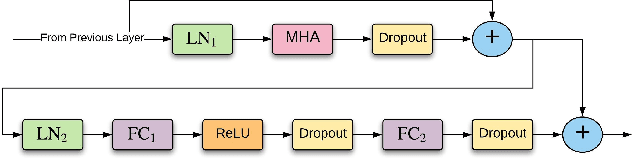
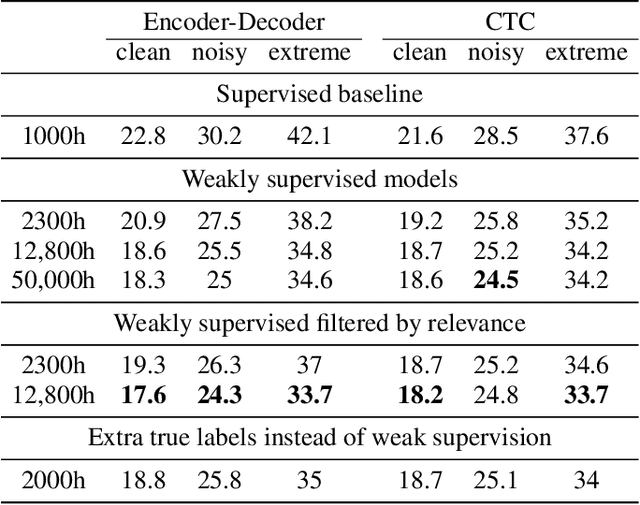
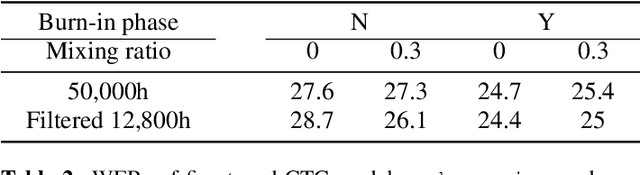

Supervised ASR models have reached unprecedented levels of accuracy, thanks in part to ever-increasing amounts of labelled training data. However, in many applications and locales, only moderate amounts of data are available, which has led to a surge in semi- and weakly-supervised learning research. In this paper, we conduct a large-scale study evaluating the effectiveness of weakly-supervised learning for speech recognition by using loosely related contextual information as a surrogate for ground-truth labels. For weakly supervised training, we use 50k hours of public English social media videos along with their respective titles and post text to train an encoder-decoder transformer model. Our best encoder-decoder models achieve an average of 20.8% WER reduction over a 1000 hours supervised baseline, and an average of 13.4% WER reduction when using only the weakly supervised encoder for CTC fine-tuning. Our results show that our setup for weak supervision improved both the encoder acoustic representations as well as the decoder language generation abilities.