 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Transformer for Scalable Inference in Open-domain Question Answering
Aug 05, 2021
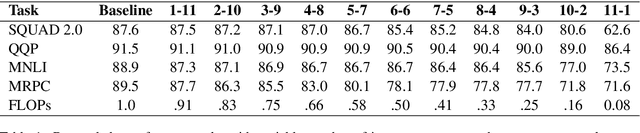
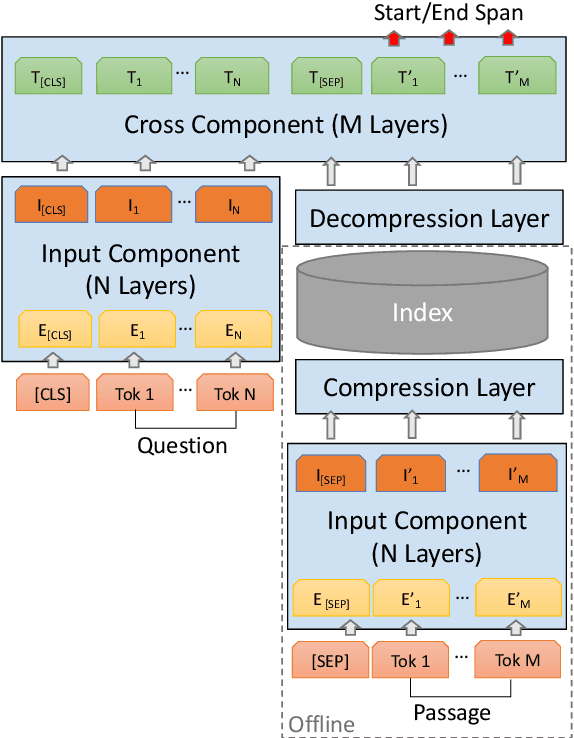
Large transformer models, such as BERT, achieve state-of-the-art results in machine reading comprehension (MRC) for open-domain question answering (QA). However, transformers have a high computational cost for inference which makes them hard to apply to online QA systems for applications like voice assistants. To reduce computational cost and latency, we propose decoupling the transformer MRC model into input-component and cross-component. The decoupling allows for part of the representation computation to be performed offline and cached for online use. To retain the decoupled transformer accuracy, we devised a knowledge distillation objective from a standard transformer model. Moreover, we introduce learned representation compression layers which help reduce by four times the storage requirement for the cache. In experiments on the SQUAD 2.0 dataset, a decoupled transformer reduces the computational cost and latency of open-domain MRC by 30-40% with only 1.2 points worse F1-score compared to a standard transformer.
Robustly Optimized and Distilled Training for Natural Language Understanding
Mar 16, 2021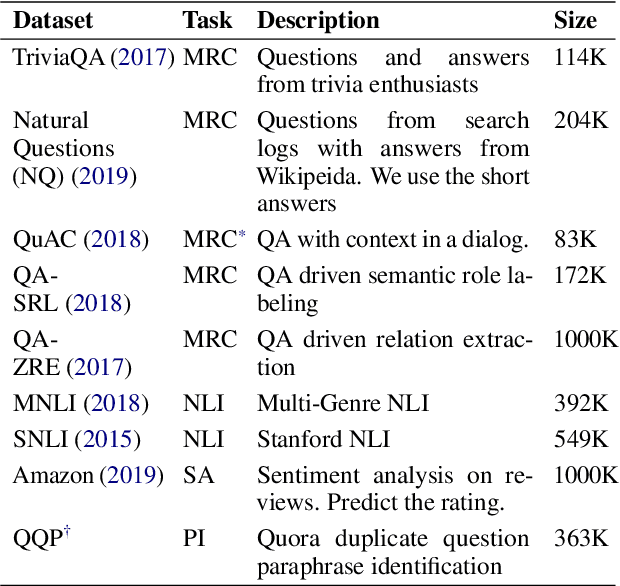
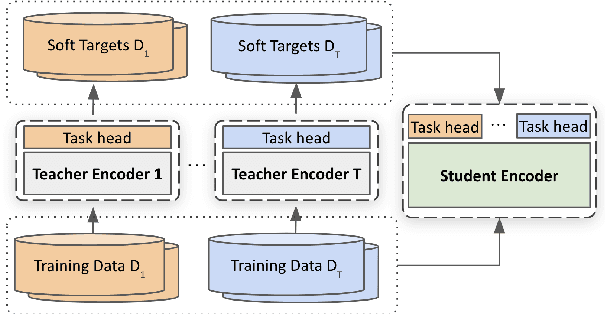
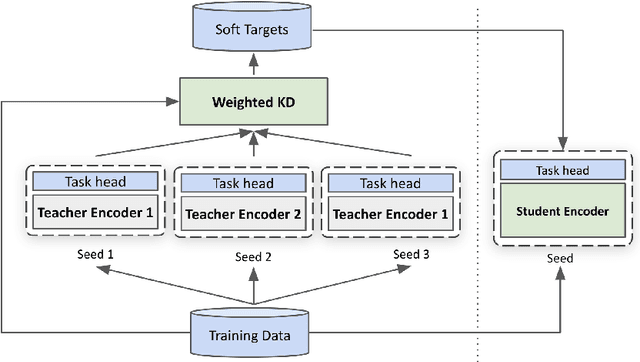
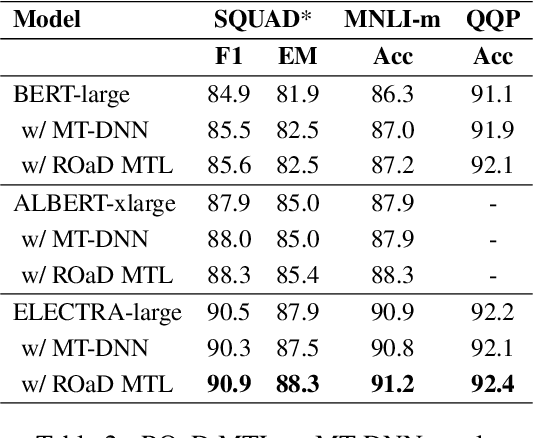
In this paper, we explore multi-task learning (MTL) as a second pretraining step to learn enhanced universal language representation for transformer language models. We use the MTL enhanced representation across several natural language understanding tasks to improve performance and generalization. Moreover, we incorporate knowledge distillation (KD) in MTL to further boost performance and devise a KD variant that learns effectively from multiple teachers. By combining MTL and KD, we propose Robustly Optimized and Distilled (ROaD) modeling framework. We use ROaD together with the ELECTRA model to obtain state-of-the-art results for machine reading comprehension and natural language inference.