 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHappyDB: A Corpus of 100,000 Crowdsourced Happy Moments
Jan 25, 2018
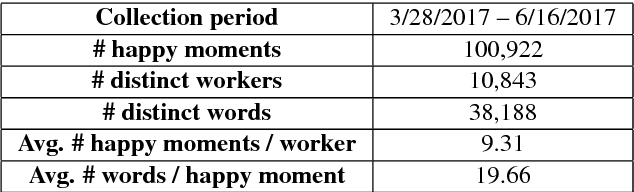
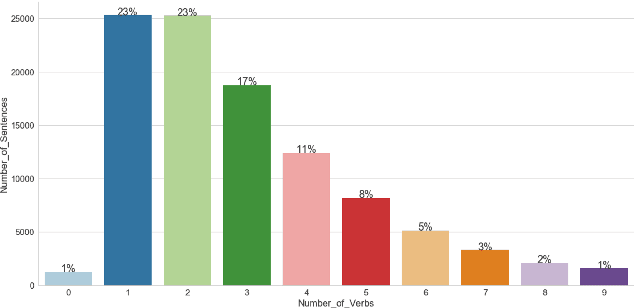
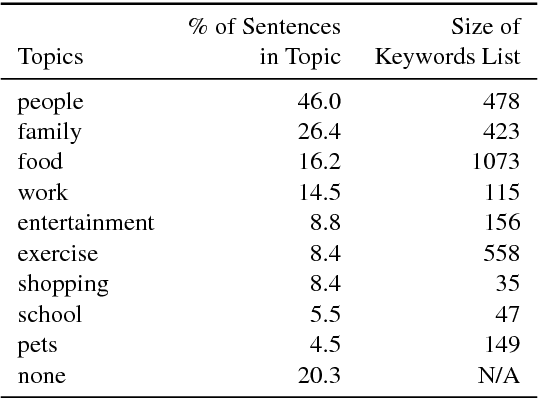
The science of happiness is an area of positive psychology concerned with understanding what behaviors make people happy in a sustainable fashion. Recently, there has been interest in developing technologies that help incorporate the findings of the science of happiness into users' daily lives by steering them towards behaviors that increase happiness. With the goal of building technology that can understand how people express their happy moments in text, we crowd-sourced HappyDB, a corpus of 100,000 happy moments that we make publicly available. This paper describes HappyDB and its properties, and outlines several important NLP problems that can be studied with the help of the corpus. We also apply several state-of-the-art analysis techniques to analyze HappyDB. Our results demonstrate the need for deeper NLP techniques to be developed which makes HappyDB an exciting resource for follow-on research.
A Lightweight Front-end Tool for Interactive Entity Population
Aug 01, 2017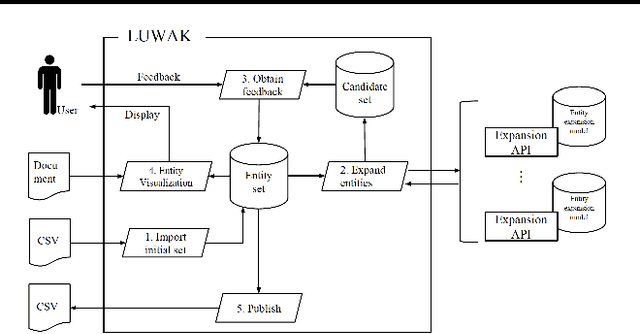
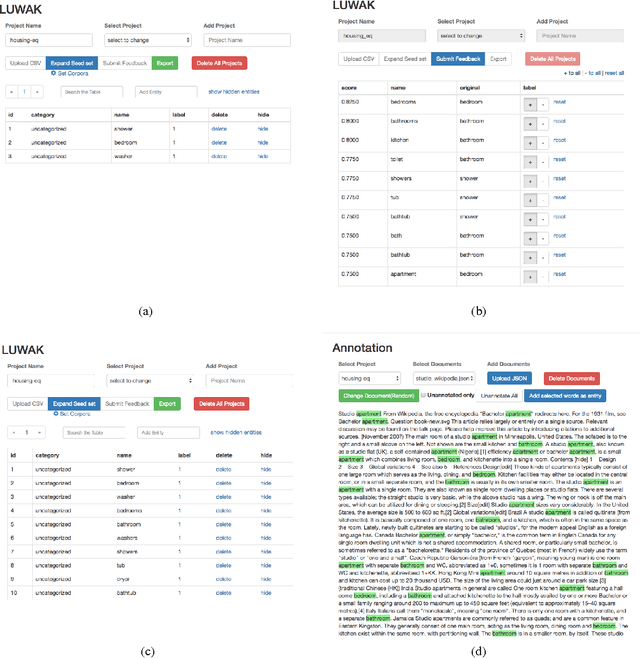
Entity population, a task of collecting entities that belong to a particular category, has attracted attention from vertical domains. There is still a high demand for creating entity dictionaries in vertical domains, which are not covered by existing knowledge bases. We develop a lightweight front-end tool for facilitating interactive entity population. We implement key components necessary for effective interactive entity population: 1) GUI-based dashboards to quickly modify an entity dictionary, and 2) entity highlighting on documents for quickly viewing the current progress. We aim to reduce user cost from beginning to end, including package installation and maintenance. The implementation enables users to use this tool on their web browsers without any additional packages --- users can focus on their missions to create entity dictionaries. Moreover, an entity expansion module is implemented as external APIs. This design makes it easy to continuously improve interactive entity population pipelines. We are making our demo publicly available (http://bit.ly/luwak-demo).