 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Serve As Time Series Anomaly Detectors?
Aug 06, 2024An emerging topic in large language models (LLMs) is their application to time series forecasting, characterizing mainstream and patternable characteristics of time series. A relevant but rarely explored and more challenging question is whether LLMs can detect and explain time series anomalies, a critical task across various real-world applications. In this paper, we investigate the capabilities of LLMs, specifically GPT-4 and LLaMA3, in detecting and explaining anomalies in time series. Our studies reveal that: 1) LLMs cannot be directly used for time series anomaly detection. 2) By designing prompt strategies such as in-context learning and chain-of-thought prompting, GPT-4 can detect time series anomalies with results competitive to baseline methods. 3) We propose a synthesized dataset to automatically generate time series anomalies with corresponding explanations. By applying instruction fine-tuning on this dataset, LLaMA3 demonstrates improved performance in time series anomaly detection tasks. In summary, our exploration shows the promising potential of LLMs as time series anomaly detectors.
Refining the Optimization Target for Automatic Univariate Time Series Anomaly Detection in Monitoring Services
Jul 20, 2023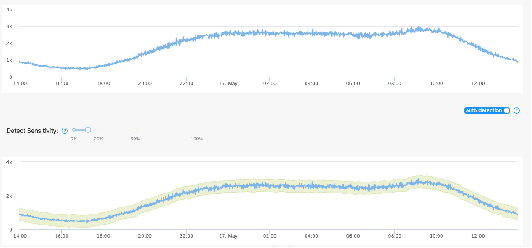

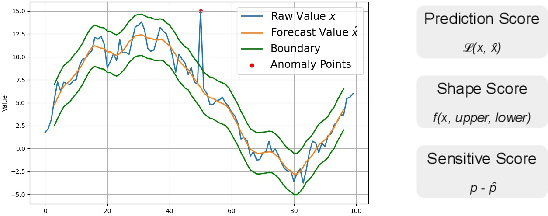
Time series anomaly detection is crucial for industrial monitoring services that handle a large volume of data, aiming to ensure reliability and optimize system performance. Existing methods often require extensive labeled resources and manual parameter selection, highlighting the need for automation. This paper proposes a comprehensive framework for automatic parameter optimization in time series anomaly detection models. The framework introduces three optimization targets: prediction score, shape score, and sensitivity score, which can be easily adapted to different model backbones without prior knowledge or manual labeling efforts. The proposed framework has been successfully applied online for over six months, serving more than 50,000 time series every minute. It simplifies the user's experience by requiring only an expected sensitive value, offering a user-friendly interface, and achieving desired detection results. Extensive evaluations conducted on public datasets and comparison with other methods further confirm the effectiveness of the proposed framework.
AutoSmart: An Efficient and Automatic Machine Learning framework for Temporal Relational Data
Sep 09, 2021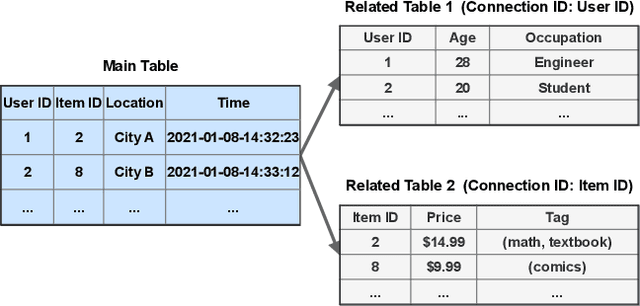

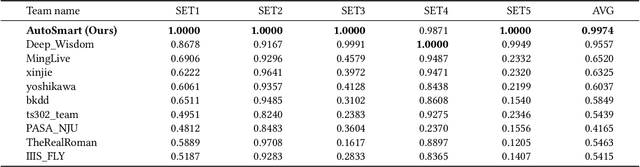
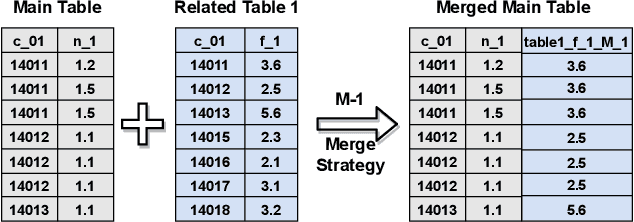
Temporal relational data, perhaps the most commonly used data type in industrial machine learning applications, needs labor-intensive feature engineering and data analyzing for giving precise model predictions. An automatic machine learning framework is needed to ease the manual efforts in fine-tuning the models so that the experts can focus more on other problems that really need humans' engagement such as problem definition, deployment, and business services. However, there are three main challenges for building automatic solutions for temporal relational data: 1) how to effectively and automatically mining useful information from the multiple tables and the relations from them? 2) how to be self-adjustable to control the time and memory consumption within a certain budget? and 3) how to give generic solutions to a wide range of tasks? In this work, we propose our solution that successfully addresses the above issues in an end-to-end automatic way. The proposed framework, AutoSmart, is the winning solution to the KDD Cup 2019 of the AutoML Track, which is one of the largest AutoML competition to date (860 teams with around 4,955 submissions). The framework includes automatic data processing, table merging, feature engineering, and model tuning, with a time\&memory controller for efficiently and automatically formulating the models. The proposed framework outperforms the baseline solution significantly on several datasets in various domains.
MapRE: An Effective Semantic Mapping Approach for Low-resource Relation Extraction
Sep 09, 2021

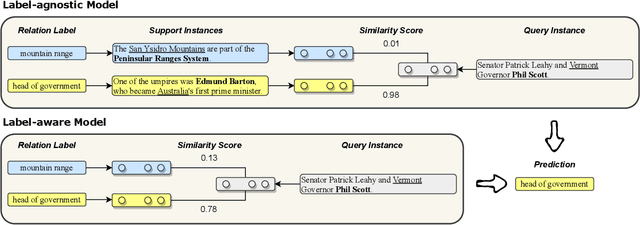

Neural relation extraction models have shown promising results in recent years; however, the model performance drops dramatically given only a few training samples. Recent works try leveraging the advance in few-shot learning to solve the low resource problem, where they train label-agnostic models to directly compare the semantic similarities among context sentences in the embedding space. However, the label-aware information, i.e., the relation label that contains the semantic knowledge of the relation itself, is often neglected for prediction. In this work, we propose a framework considering both label-agnostic and label-aware semantic mapping information for low resource relation extraction. We show that incorporating the above two types of mapping information in both pretraining and fine-tuning can significantly improve the model performance on low-resource relation extraction tasks.
MAMO: Memory-Augmented Meta-Optimization for Cold-start Recommendation
Jul 07, 2020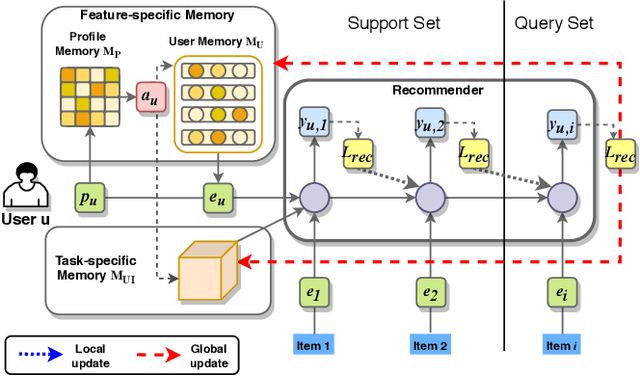
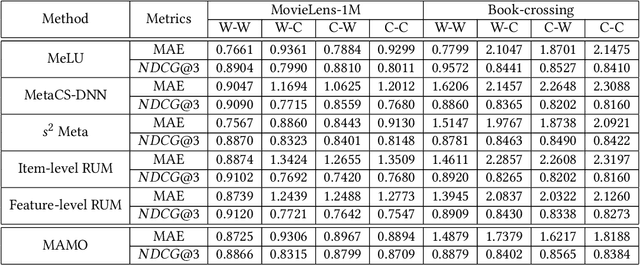
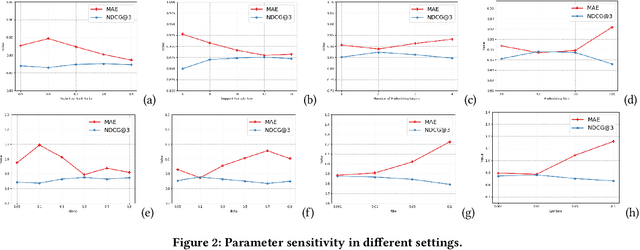
A common challenge for most current recommender systems is the cold-start problem. Due to the lack of user-item interactions, the fine-tuned recommender systems are unable to handle situations with new users or new items. Recently, some works introduce the meta-optimization idea into the recommendation scenarios, i.e. predicting the user preference by only a few of past interacted items. The core idea is learning a global sharing initialization parameter for all users and then learning the local parameters for each user separately. However, most meta-learning based recommendation approaches adopt model-agnostic meta-learning for parameter initialization, where the global sharing parameter may lead the model into local optima for some users. In this paper, we design two memory matrices that can store task-specific memories and feature-specific memories. Specifically, the feature-specific memories are used to guide the model with personalized parameter initialization, while the task-specific memories are used to guide the model fast predicting the user preference. And we adopt a meta-optimization approach for optimizing the proposed method. We test the model on two widely used recommendation datasets and consider four cold-start situations. The experimental results show the effectiveness of the proposed methods.
Trust in Recommender Systems: A Deep Learning Perspective
Apr 08, 2020
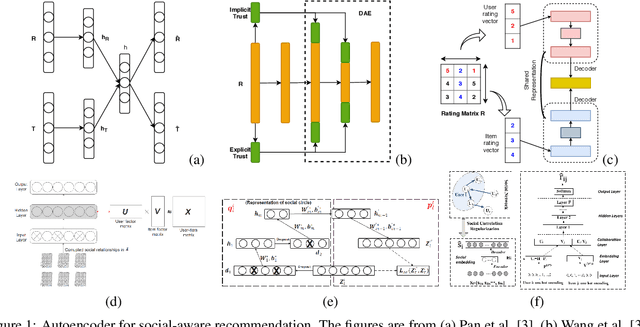
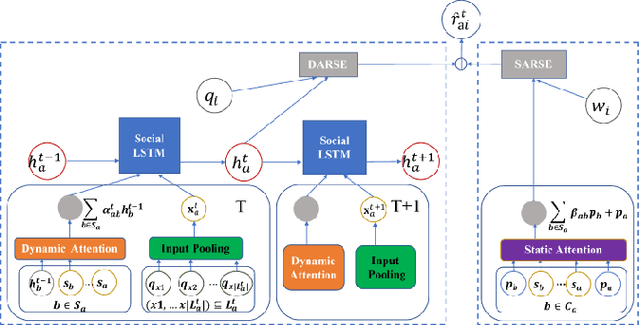

A significant remaining challenge for existing recommender systems is that users may not trust the recommender systems for either lack of explanation or inaccurate recommendation results. Thus, it becomes critical to embrace a trustworthy recommender system. This survey provides a systemic summary of three categories of trust-aware recommender systems: social-aware recommender systems that leverage users' social relationships; robust recommender systems that filter untruthful noises (e.g., spammers and fake information) or enhance attack resistance; explainable recommender systems that provide explanations of recommended items. We focus on the work based on deep learning techniques, an emerging area in the recommendation research.
Adversarial Representation Learning for Robust Patient-Independent Epileptic Seizure Detection
Sep 18, 2019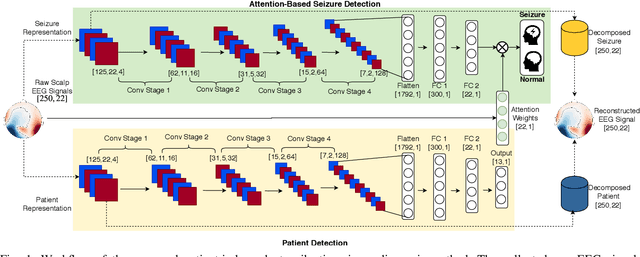
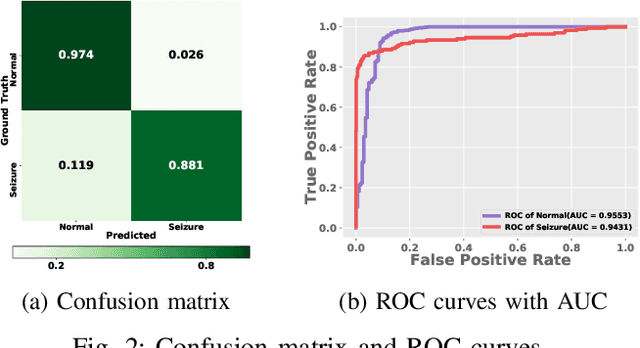
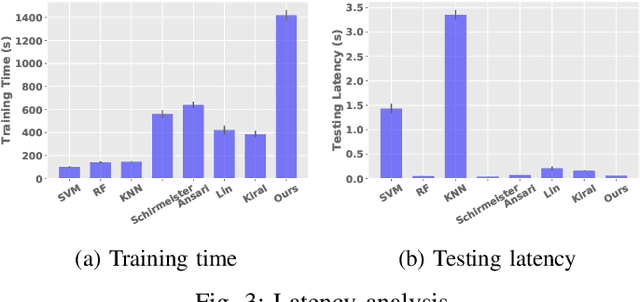
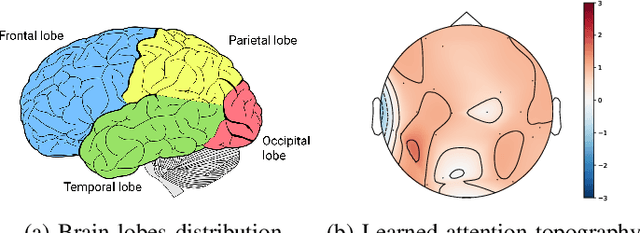
Objective: Epilepsy is a chronic neurological disorder characterized by the occurrence of spontaneous seizures, which affects about one percent of the world's population. Most of the current seizure detection approaches strongly rely on patient history records and thus fail in the patient-independent situation of detecting the new patients. To overcome such limitation, we propose a robust and explainable epileptic seizure detection model that effectively learns from seizure states while eliminates the inter-patient noises. Methods: A complex deep neural network model is proposed to learn the pure seizure-specific representation from the raw non-invasive electroencephalography (EEG) signals through adversarial training. Furthermore, to enhance the explainability, we develop an attention mechanism to automatically learn the importance of each EEG channels in the seizure diagnosis procedure. Results: The proposed approach is evaluated over the Temple University Hospital EEG (TUH EEG) database. The experimental results illustrate that our model outperforms the competitive state-of-the-art baselines with low latency. Moreover, the designed attention mechanism is demonstrated ables to provide fine-grained information for pathological analysis. Conclusion and significance: We propose an effective and efficient patient-independent diagnosis approach of epileptic seizure based on raw EEG signals without manually feature engineering, which is a step toward the development of large-scale deployment for real-life use.
Deep Neural Network Hyperparameter Optimization with Orthogonal Array Tuning
Jul 31, 2019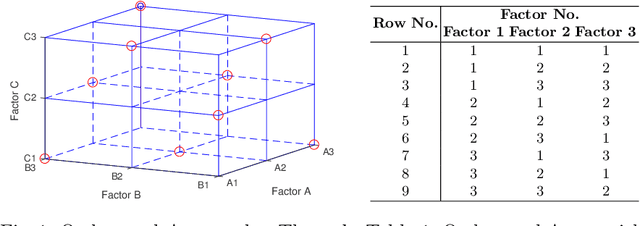
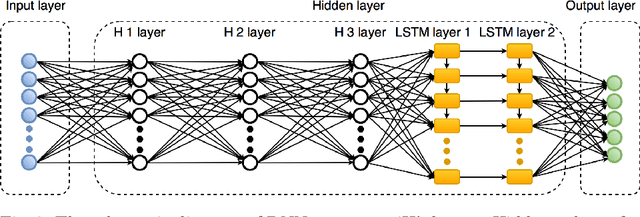

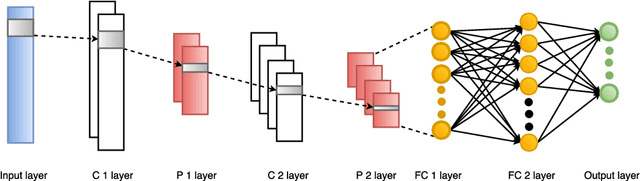
Deep learning algorithms have achieved excellent performance lately in a wide range of fields (e.g., computer version). However, a severe challenge faced by deep learning is the high dependency on hyper-parameters. The algorithm results may fluctuate dramatically under the different configuration of hyper-parameters. Addressing the above issue, this paper presents an efficient Orthogonal Array Tuning Method (OATM) for deep learning hyper-parameter tuning. We describe the OATM approach in five detailed steps and elaborate on it using two widely used deep neural network structures (Recurrent Neural Networks and Convolutional Neural Networks). The proposed method is compared to the state-of-the-art hyper-parameter tuning methods including manually (e.g., grid search and random search) and automatically (e.g., Bayesian Optimization) ones. The experiment results state that OATM can significantly save the tuning time compared to the state-of-the-art methods while preserving the satisfying performance.
Multi-task Generative Adversarial Learning on Geometrical Shape Reconstruction from EEG Brain Signals
Jul 31, 2019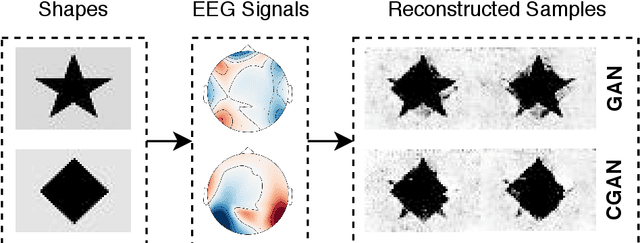

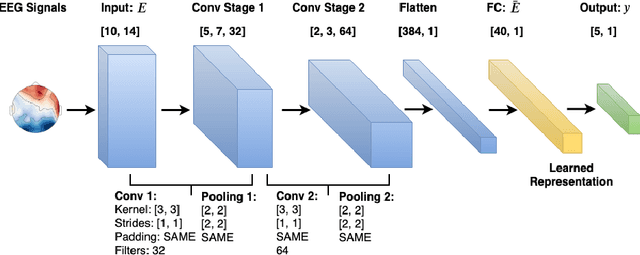
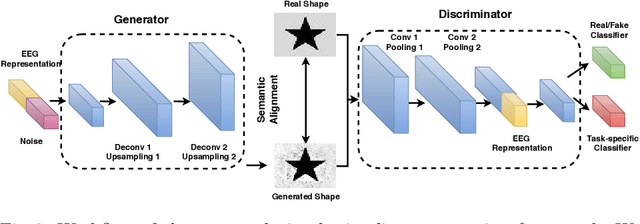
Synthesizing geometrical shapes from human brain activities is an interesting and meaningful but very challenging topic. Recently, the advancements of deep generative models like Generative Adversarial Networks (GANs) have supported the object generation from neurological signals. However, the Electroencephalograph (EEG)-based shape generation still suffer from the low realism problem. In particular, the generated geometrical shapes lack clear edges and fail to contain necessary details. In light of this, we propose a novel multi-task generative adversarial network to convert the individual's EEG signals evoked by geometrical shapes to the original geometry. First, we adopt a Convolutional Neural Network (CNN) to learn highly informative latent representation for the raw EEG signals, which is vital for the subsequent shape reconstruction. Next, we build the discriminator based on multi-task learning to distinguish and classify fake samples simultaneously, where the mutual promotion between different tasks improves the quality of the recovered shapes. Then, we propose a semantic alignment constraint in order to force the synthesized samples to approach the real ones in pixel-level, thus producing more compelling shapes. The proposed approach is evaluated over a local dataset and the results show that our model outperforms the competitive state-of-the-art baselines.
GrCAN: Gradient Boost Convolutional Autoencoder with Neural Decision Forest
Jun 24, 2018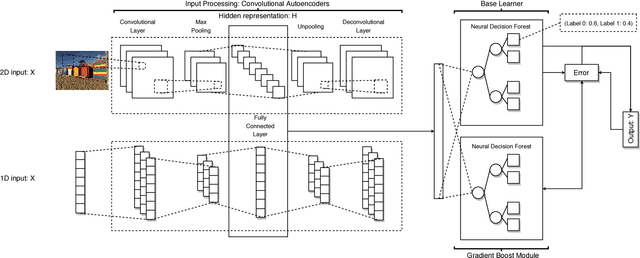


Random forest and deep neural network are two schools of effective classification methods in machine learning. While the random forest is robust irrespective of the data domain, the deep neural network has advantages in handling high dimensional data. In view that a differentiable neural decision forest can be added to the neural network to fully exploit the benefits of both models, in our work, we further combine convolutional autoencoder with neural decision forest, where autoencoder has its advantages in finding the hidden representations of the input data. We develop a gradient boost module and embed it into the proposed convolutional autoencoder with neural decision forest to improve the performance. The idea of gradient boost is to learn and use the residual in the prediction. In addition, we design a structure to learn the parameters of the neural decision forest and gradient boost module at contiguous steps. The extensive experiments on several public datasets demonstrate that our proposed model achieves good efficiency and prediction performance compared with a series of baseline methods.