 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZenith: Scaling up Ranking Models for Billion-scale Livestreaming Recommendation
Jan 29, 2026Accurately capturing feature interactions is essential in recommender systems, and recent trends show that scaling up model capacity could be a key driver for next-level predictive performance. While prior work has explored various model architectures to capture multi-granularity feature interactions, relatively little attention has been paid to efficient feature handling and scaling model capacity without incurring excessive inference latency. In this paper, we address this by presenting Zenith, a scalable and efficient ranking architecture that learns complex feature interactions with minimal runtime overhead. Zenith is designed to handle a few high-dimensional Prime Tokens with Token Fusion and Token Boost modules, which exhibits superior scaling laws compared to other state-of-the-art ranking methods, thanks to its improved token heterogeneity. Its real-world effectiveness is demonstrated by deploying the architecture to TikTok Live, a leading online livestreaming platform that attracts billions of users globally. Our A/B test shows that Zenith achieves +1.05%/-1.10% in online CTR AUC and Logloss, and realizes +9.93% gains in Quality Watch Session / User and +8.11% in Quality Watch Duration / User.
AutoSmart: An Efficient and Automatic Machine Learning framework for Temporal Relational Data
Sep 09, 2021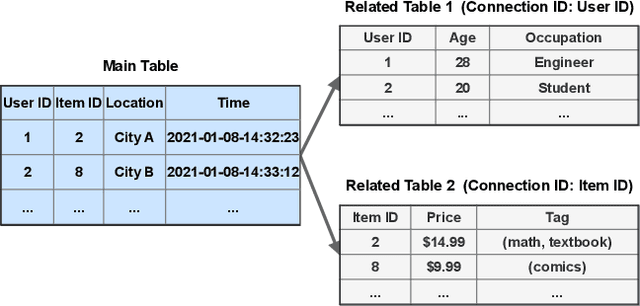

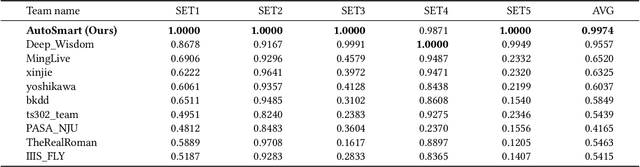
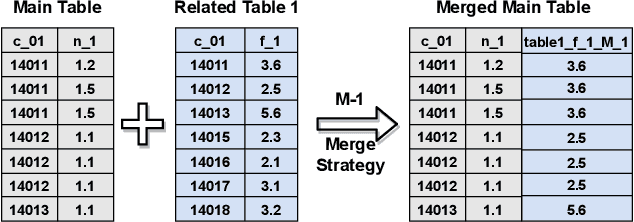
Temporal relational data, perhaps the most commonly used data type in industrial machine learning applications, needs labor-intensive feature engineering and data analyzing for giving precise model predictions. An automatic machine learning framework is needed to ease the manual efforts in fine-tuning the models so that the experts can focus more on other problems that really need humans' engagement such as problem definition, deployment, and business services. However, there are three main challenges for building automatic solutions for temporal relational data: 1) how to effectively and automatically mining useful information from the multiple tables and the relations from them? 2) how to be self-adjustable to control the time and memory consumption within a certain budget? and 3) how to give generic solutions to a wide range of tasks? In this work, we propose our solution that successfully addresses the above issues in an end-to-end automatic way. The proposed framework, AutoSmart, is the winning solution to the KDD Cup 2019 of the AutoML Track, which is one of the largest AutoML competition to date (860 teams with around 4,955 submissions). The framework includes automatic data processing, table merging, feature engineering, and model tuning, with a time\&memory controller for efficiently and automatically formulating the models. The proposed framework outperforms the baseline solution significantly on several datasets in various domains.