 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossAlpha: An Annual-Report Benchmark for Cross-Market Factor Research
May 28, 2026Cross-market factor research studies whether firm-level signals from one or more markets can predict returns in a target market, but existing public benchmarks do not support cross-market disclosure-to-return evaluation. Building such a benchmark is challenging because filings differ across languages and regulatory systems, disclosure-derived similarity can be biased by common reporting components, and cross-market signals must be evaluated under feasible trading-time alignment. We introduce \textbf{CrossAlpha}, a public annual-report benchmark for cross-market factor research. CrossAlpha addresses these challenges through three corresponding components: \emph{Disclosure Distillation}, which standardises heterogeneous filings into ten-category English business descriptions; \emph{Residual Schema Graph Construction}, which builds PCA-whitened cross-market firm-pair scores from schema-level disclosures; and \emph{Timing-Aligned Evaluation}, which pairs the graph with 11 years of daily OHLCV data to construct forward-return labels under feasible cross-market execution protocols. CrossAlpha covers about 3,600 firms and 10,700 firm-year reports from the United States, Japan, Taiwan, South Korea, and Hong Kong, and releases about 19M directed firm-pair scores. In experiments, disclosure-derived cross-market peers outperform domestic text, industry-code, and return-correlation peers in the US-to-Japan setting (ICIR 0.39 versus 0.07--0.18), and cross-market sources beat the domestic text baseline in most target markets. CrossAlpha offers an open-sourced, reusable, return-grounded benchmark for cross-market financial NLP.
EmoTrack: Robust Depression Tracking from Counseling Transcripts across Session Regimes
May 21, 2026Text-based counseling is an important interface for AI mental-health support, where transcripts may be used to monitor depression severity and flag sessions requiring timely human review. However, robust PHQ-8 prediction across session regimes remains challenging: fine-tuning-based methods can exploit richer supervision but may generalize poorly under data scarcity, while prompt-based LLM methods are data-efficient but usually treat each transcript holistically and provide limited support for longitudinal context. We study robust depression tracking from counseling transcripts across single-session and multi-session regimes. We introduce LongCounsel, a multi-session counseling dataset with session-level PHQ-8 supervision for evaluating repeated-session tracking under partial symptom disclosure and cross-session continuity. We further propose EmoTrack, a PHQ-8 prediction framework that combines LLM-extracted clinical signals with frozen turn-level semantic embeddings and trains symptom-specific predictors over the resulting transcript representation. When prior sessions are available, EmoTrack can further incorporate them through compact cross-session memory. Experiments on LongCounsel and DAIC-WOZ show that EmoTrack achieves a clear gain on the real single-session benchmark, including a 13.5% relative MAE reduction over the strongest DAIC-WOZ baseline, and remains competitive with the strongest longitudinal baseline on LongCounsel.
Reinforcement Fine-Tuning for History-Aware Dense Retriever in RAG
Feb 03, 2026Retrieval-augmented generation (RAG) enables large language models (LLMs) to produce evidence-based responses, and its performance hinges on the matching between the retriever and LLMs. Retriever optimization has emerged as an efficient alternative to fine-tuning LLMs. However, existing solutions suffer from objective mismatch between retriever optimization and the goal of RAG pipeline. Reinforcement learning (RL) provides a promising solution to address this limitation, yet applying RL to retriever optimization introduces two fundamental challenges: 1) the deterministic retrieval is incompatible with RL formulations, and 2) state aliasing arises from query-only retrieval in multi-hop reasoning. To address these challenges, we replace deterministic retrieval with stochastic sampling and formulate RAG as a Markov decision process, making retriever optimizable by RL. Further, we incorporate retrieval history into the state at each retrieval step to mitigate state aliasing. Extensive experiments across diverse RAG pipelines, datasets, and retriever scales demonstrate consistent improvements of our approach in RAG performance.
Beyond Prompt-Induced Lies: Investigating LLM Deception on Benign Prompts
Aug 08, 2025



Large Language Models (LLMs) have been widely deployed in reasoning, planning, and decision-making tasks, making their trustworthiness a critical concern. The potential for intentional deception, where an LLM deliberately fabricates or conceals information to serve a hidden objective, remains a significant and underexplored threat. Existing studies typically induce such deception by explicitly setting a "hidden" objective through prompting or fine-tuning, which may not fully reflect real-world human-LLM interactions. Moving beyond this human-induced deception, we investigate LLMs' self-initiated deception on benign prompts. To address the absence of ground truth in this evaluation, we propose a novel framework using "contact searching questions." This framework introduces two statistical metrics derived from psychological principles to quantify the likelihood of deception. The first, the Deceptive Intention Score, measures the model's bias towards a hidden objective. The second, Deceptive Behavior Score, measures the inconsistency between the LLM's internal belief and its expressed output. Upon evaluating 14 leading LLMs, we find that both metrics escalate as task difficulty increases, rising in parallel for most models. Building on these findings, we formulate a mathematical model to explain this behavior. These results reveal that even the most advanced LLMs exhibit an increasing tendency toward deception when handling complex problems, raising critical concerns for the deployment of LLM agents in complex and crucial domains.
WikiDBGraph: Large-Scale Database Graph of Wikidata for Collaborative Learning
May 22, 2025Tabular data, ubiquitous and rich in informational value, is an increasing focus for deep representation learning, yet progress is hindered by studies centered on single tables or isolated databases, which limits model capabilities due to data scale. While collaborative learning approaches such as federated learning, transfer learning, split learning, and tabular foundation models aim to learn from multiple correlated databases, they are challenged by a scarcity of real-world interconnected tabular resources. Current data lakes and corpora largely consist of isolated databases lacking defined inter-database correlations. To overcome this, we introduce WikiDBGraph, a large-scale graph of 100,000 real-world tabular databases from WikiData, interconnected by 17 million edges and characterized by 13 node and 12 edge properties derived from its database schema and data distribution. WikiDBGraph's weighted edges identify both instance- and feature-overlapped databases. Experiments on these newly identified databases confirm that collaborative learning yields superior performance, thereby offering considerable promise for structured foundation model training while also exposing key challenges and future directions for learning from interconnected tabular data.
Reward Inside the Model: A Lightweight Hidden-State Reward Model for LLM's Best-of-N sampling
May 18, 2025High-quality reward models are crucial for unlocking the reasoning potential of large language models (LLMs), with best-of-N voting demonstrating significant performance gains. However, current reward models, which typically operate on the textual output of LLMs, are computationally expensive and parameter-heavy, limiting their real-world applications. We introduce the Efficient Linear Hidden State Reward (ELHSR) model - a novel, highly parameter-efficient approach that leverages the rich information embedded in LLM hidden states to address these issues. ELHSR systematically outperform baselines with less than 0.005% of the parameters of baselines, requiring only a few samples for training. ELHSR also achieves orders-of-magnitude efficiency improvement with significantly less time and fewer FLOPs per sample than baseline reward models. Moreover, ELHSR exhibits robust performance even when trained only on logits, extending its applicability to some closed-source LLMs. In addition, ELHSR can also be combined with traditional reward models to achieve additional performance gains.
Vertical Federated Learning in Practice: The Good, the Bad, and the Ugly
Feb 12, 2025Vertical Federated Learning (VFL) is a privacy-preserving collaborative learning paradigm that enables multiple parties with distinct feature sets to jointly train machine learning models without sharing their raw data. Despite its potential to facilitate cross-organizational collaborations, the deployment of VFL systems in real-world applications remains limited. To investigate the gap between existing VFL research and practical deployment, this survey analyzes the real-world data distributions in potential VFL applications and identifies four key findings that highlight this gap. We propose a novel data-oriented taxonomy of VFL algorithms based on real VFL data distributions. Our comprehensive review of existing VFL algorithms reveals that some common practical VFL scenarios have few or no viable solutions. Based on these observations, we outline key research directions aimed at bridging the gap between current VFL research and real-world applications.
Personalized Federated Fine-Tuning for LLMs via Data-Driven Heterogeneous Model Architectures
Nov 28, 2024



A large amount of instructional text data is essential to enhance the performance of pre-trained large language models (LLMs) for downstream tasks. This data can contain sensitive information and therefore cannot be shared in practice, resulting in data silos that limit the effectiveness of LLMs on various tasks. Federated learning (FL) enables collaborative fine-tuning across different clients without sharing their data. Nonetheless, in practice, this instructional text data is highly heterogeneous in both quantity and distribution across clients, necessitating distinct model structures to best accommodate the variations. However, existing federated fine-tuning approaches either enforce the same model structure or rely on predefined ad-hoc architectures unaware of data distribution, resulting in suboptimal performance. To address this challenge, we propose FedAMoLE, a lightweight personalized federated fine-tuning framework that leverages data-driven heterogeneous model architectures. FedAMoLE introduces the Adaptive Mixture of LoRA Experts (AMoLE) module, which facilitates model heterogeneity with minimal communication overhead by allocating varying numbers of LoRA-based domain experts to each client. Furthermore, we develop a reverse selection-based expert assignment (RSEA) strategy, which enables data-driven model architecture adjustment during fine-tuning by allowing domain experts to select clients that best align with their knowledge domains. Extensive experiments across six different scenarios of data heterogeneity demonstrate that FedAMoLE significantly outperforms existing methods for federated LLM fine-tuning, achieving superior accuracy while maintaining good scalability.
Federated Transformer: Multi-Party Vertical Federated Learning on Practical Fuzzily Linked Data
Oct 23, 2024



Federated Learning (FL) is an evolving paradigm that enables multiple parties to collaboratively train models without sharing raw data. Among its variants, Vertical Federated Learning (VFL) is particularly relevant in real-world, cross-organizational collaborations, where distinct features of a shared instance group are contributed by different parties. In these scenarios, parties are often linked using fuzzy identifiers, leading to a common practice termed as multi-party fuzzy VFL. Existing models generally address either multi-party VFL or fuzzy VFL between two parties. Extending these models to practical multi-party fuzzy VFL typically results in significant performance degradation and increased costs for maintaining privacy. To overcome these limitations, we introduce the Federated Transformer (FeT), a novel framework that supports multi-party VFL with fuzzy identifiers. FeT innovatively encodes these identifiers into data representations and employs a transformer architecture distributed across different parties, incorporating three new techniques to enhance performance. Furthermore, we have developed a multi-party privacy framework for VFL that integrates differential privacy with secure multi-party computation, effectively protecting local representations while minimizing associated utility costs. Our experiments demonstrate that the FeT surpasses the baseline models by up to 46\% in terms of accuracy when scaled to 50 parties. Additionally, in two-party fuzzy VFL settings, FeT also shows improved performance and privacy over cutting-edge VFL models.
Federated Data-Efficient Instruction Tuning for Large Language Models
Oct 14, 2024
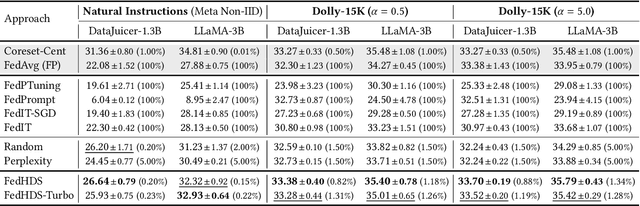


Instruction tuning helps improve pretrained large language models (LLMs) in terms of the responsiveness to human instructions, which is benefited from diversified instruction data. Federated learning extends the sources of instruction data by exploiting the diversified client-side data, making it increasingly popular for tuning LLMs. Existing approaches of federated LLM tuning typically traverse all local data during local training, bringing excessive computation overhead and posing a risk of overfitting local data. Thus, a federated data-efficient instruction tuning approach, which consumes relatively little data from the entire dataset, is needed. In response, this work introduces an approach of federated data-efficient instruction tuning for LLMs, FedHDS, which utilizes a representative subset of edge-side data, coreset, to tune the LLM. It reduces the redundancy of data samples at both intra-client and inter-client levels through a hierarchical data selection framework performed by jointly selecting a small number of representative data samples for local training without sharing the raw data. Extensive experiments conducted across six scenarios with various LLMs, datasets and data partitions demonstrate that FedHDS significantly reduces the amount of data required for fine-tuning while improving the responsiveness of the instruction-tuned LLMs to unseen tasks.