 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Data-Efficient Instruction Tuning for Large Language Models
Paper and Code
Oct 14, 2024
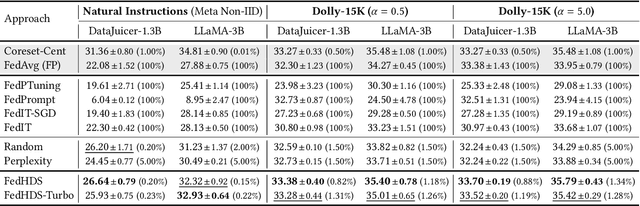


Instruction tuning helps improve pretrained large language models (LLMs) in terms of the responsiveness to human instructions, which is benefited from diversified instruction data. Federated learning extends the sources of instruction data by exploiting the diversified client-side data, making it increasingly popular for tuning LLMs. Existing approaches of federated LLM tuning typically traverse all local data during local training, bringing excessive computation overhead and posing a risk of overfitting local data. Thus, a federated data-efficient instruction tuning approach, which consumes relatively little data from the entire dataset, is needed. In response, this work introduces an approach of federated data-efficient instruction tuning for LLMs, FedHDS, which utilizes a representative subset of edge-side data, coreset, to tune the LLM. It reduces the redundancy of data samples at both intra-client and inter-client levels through a hierarchical data selection framework performed by jointly selecting a small number of representative data samples for local training without sharing the raw data. Extensive experiments conducted across six scenarios with various LLMs, datasets and data partitions demonstrate that FedHDS significantly reduces the amount of data required for fine-tuning while improving the responsiveness of the instruction-tuned LLMs to unseen tasks.