 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFragFuse: Bypassing Access Control of Large Language Model Agents via Memory-Based Query Fragmentation and Fusion
Jun 14, 2026Large language model (LLM) agents increasingly rely on long-term memory to support complex task execution, user personalization, and domain adaptation. Meanwhile, emerging access-control mechanisms for LLM agents are being explored to block policy-violating requests and prevent misuse. We reveal a novel attack surface arising from agent memory operations: prohibited content that would trigger access control can be fragmented across interactions, stored in long-term memory in benign-appearing form, and later reconstructed through memory retrieval without appearing explicitly in the final user query. We propose FragFuse, the first attack that enables unprivileged users to bypass agent access control by exploiting this temporal channel introduced by long-term memory. FragFuse operates in three stages: (1) identifying rejection-responsive fragments via black-box adaptive querying with fragment masking; (2) injecting these fragments into memory using marker carrier queries; and (3) retrieving and fusing the stored fragments through a follow-up attack query. Although FragFuse can be instantiated manually for individual agents, we further develop a surrogate-based optimization scheme that tunes fusion instructions and marker designs, enabling automated attack generation without violating the attacker's threat-model assumptions. We evaluate FragFuse across four representative agent settings and task domains, covering three state-of-the-art agent access-control mechanisms. FragFuse achieves an average bypass success rate of 86.3% and an average end-to-end harmful task success rate of 41.1% across all settings, with only 4.4% average task-success degradation compared with configurations without access control. We also show that alternative defenses, including state-of-the-art prompt-injection detectors and perplexity detectors, do not effectively address this attack.
Palette: A Modular, Controllable, and Efficient Framework for On-demand Authorized Safety Alignment Relaxation in LLMs
May 22, 2026Current safety alignment of foundation models largely follows a \emph{one-size-fits-all} paradigm, applying the same refusal policy across users and contexts. As a result, models may refuse requests that are unsafe for general users but legitimate for authorized professionals, limiting helpfulness in specialized professional settings. Existing approaches either require costly realignment or rely on inference-time steering that suffers from imprecise control and added latency. To this end, we propose \textsc{Palette}, a modular, controllable, and efficient framework that selectively relaxes refusal behavior on authorized target domains while preserving standard safety elsewhere. Our method identifies a refusal direction via multi-objective search and internalizes it into the model through lightweight adaptation. \textsc{Palette} further supports modular composition: it learns domain-specific safety controls independently and composes them through parameter merging, enabling on-demand multi-domain authorization without retraining. Experiments across four safety benchmarks, multiple model variants, and both LLMs and VLMs show that \textsc{Palette} delivers precise safety control without sacrificing general utility, offering a practical path toward foundation models that adapt to diverse professional needs.
Crafting Reversible SFT Behaviors in Large Language Models
May 07, 2026Supervised fine-tuning (SFT) induces new behaviors in large language models, yet imposes no structural constraint on how these behaviors are distributed within the model. Existing behavior interpretation methods, such as circuit attribution approaches, identify sparse subnetworks correlated with SFT-induced behaviors post-hoc. However, such correlations do not imply *causal necessity*, limiting the ability to selectively control SFT-induced behaviors at inference time. We pursue an alternative by asking: can an SFT-induced behavior be deliberately compressed into a sparse, mechanistically necessary subnetwork, termed a *carrier*, while remaining controllable at inference time without weight modification? We propose (a) **Loss-Constrained Dual Descent (LCDD)**, which constructs such carriers by jointly optimizing routing masks and model weights under an explicit utility budget, and (b) **SFT-Eraser**, a soft prompt optimized via activation matching on extracted carrier channels, to reverse the SFT-induced behavior. Across safety, fixed-response, and style behaviors on multiple model families, LCDD yields sparse carriers that preserve target behaviors while enabling strong reversion when triggered by SFT-Eraser. Ablations further establish that the sparse structure is the key precondition for reversal: the same trigger optimization fails on standard SFT models, confirming that structure rather than trigger design is the operative factor. These results provide direct evidence that the learned carriers are causally necessary for the behaviors, pointing to a new direction for systematically localizing and selectively suppressing SFT-induced behaviors in deployed models.
Green Shielding: A User-Centric Approach Towards Trustworthy AI
Apr 27, 2026Large language models (LLMs) are increasingly deployed, yet their outputs can be highly sensitive to routine, non-adversarial variation in how users phrase queries, a gap not well addressed by existing red-teaming efforts. We propose Green Shielding, a user-centric agenda for building evidence-backed deployment guidance by characterizing how benign input variation shifts model behavior. We operationalize this agenda through the CUE criteria: benchmarks with authentic Context, reference standards and metrics that capture true Utility, and perturbations that reflect realistic variations in the Elicitation of model behavior. Guided by the PCS framework and developed with practicing physicians, we instantiate Green Shielding in medical diagnosis through HealthCareMagic-Diagnosis (HCM-Dx), a benchmark of patient-authored queries, together with structured reference diagnosis sets and clinically grounded metrics for evaluating differential diagnosis lists. We also study perturbation regimes that capture routine input variation and show that prompt-level factors shift model behavior along clinically meaningful dimensions. Across multiple frontier LLMs, these shifts trace out Pareto-like tradeoffs. In particular, neutralization, which removes common user-level factors while preserving clinical content, increases plausibility and yields more concise, clinician-like differentials, but reduces coverage of highly likely and safety-critical conditions. Together, these results show that interaction choices can systematically shift task-relevant properties of model outputs and support user-facing guidance for safer deployment in high-stakes domains. Although instantiated here in medical diagnosis, the agenda extends naturally to other decision-support settings and agentic AI systems.
ShieldNet: Network-Level Guardrails against Emerging Supply-Chain Injections in Agentic Systems
Apr 06, 2026Existing research on LLM agent security mainly focuses on prompt injection and unsafe input/output behaviors. However, as agents increasingly rely on third-party tools and MCP servers, a new class of supply-chain threats has emerged, where malicious behaviors are embedded in seemingly benign tools, silently hijacking agent execution, leaking sensitive data, or triggering unauthorized actions. Despite their growing impact, there is currently no comprehensive benchmark for evaluating such threats. To bridge this gap, we introduce SC-Inject-Bench, a large-scale benchmark comprising over 10,000 malicious MCP tools grounded in a taxonomy of 25+ attack types derived from MITRE ATT&CK targeting supply-chain threats. We observe that existing MCP scanners and semantic guardrails perform poorly on this benchmark. Motivated by this finding, we propose ShieldNet, a network-level guardrail framework that detects supply-chain poisoning by observing real network interactions rather than surface-level tool traces. ShieldNet integrates a man-in-the-middle (MITM) proxy and an event extractor to identify critical network behaviors, which are then processed by a lightweight classifier for attack detection. Extensive experiments show that ShieldNet achieves strong detection performance (up to 0.995 F-1 with only 0.8% false positives) while introducing little runtime overhead, substantially outperforming existing MCP scanners and LLM-based guardrails.
Q-realign: Piggybacking Realignment on Quantization for Safe and Efficient LLM Deployment
Jan 13, 2026Public large language models (LLMs) are typically safety-aligned during pretraining, yet task-specific fine-tuning required for deployment often erodes this alignment and introduces safety risks. Existing defenses either embed safety recovery into fine-tuning or rely on fine-tuning-derived priors for post-hoc correction, leaving safety recovery tightly coupled with training and incurring high computational overhead and a complex workflow. To address these challenges, we propose \texttt{Q-realign}, a post-hoc defense method based on post-training quantization, guided by an analysis of representational structure. By reframing quantization as a dual-objective procedure for compression and safety, \texttt{Q-realign} decouples safety alignment from fine-tuning and naturally piggybacks into modern deployment pipelines. Experiments across multiple models and datasets demonstrate that our method substantially reduces unsafe behaviors while preserving task performance, with significant reductions in memory usage and GPU hours. Notably, our approach can recover the safety alignment of a fine-tuned 7B LLM on a single RTX 4090 within 40 minutes. Overall, our work provides a practical, turnkey solution for safety-aware deployment.
RadFabric: Agentic AI System with Reasoning Capability for Radiology
Jun 17, 2025Chest X ray (CXR) imaging remains a critical diagnostic tool for thoracic conditions, but current automated systems face limitations in pathology coverage, diagnostic accuracy, and integration of visual and textual reasoning. To address these gaps, we propose RadFabric, a multi agent, multimodal reasoning framework that unifies visual and textual analysis for comprehensive CXR interpretation. RadFabric is built on the Model Context Protocol (MCP), enabling modularity, interoperability, and scalability for seamless integration of new diagnostic agents. The system employs specialized CXR agents for pathology detection, an Anatomical Interpretation Agent to map visual findings to precise anatomical structures, and a Reasoning Agent powered by large multimodal reasoning models to synthesize visual, anatomical, and clinical data into transparent and evidence based diagnoses. RadFabric achieves significant performance improvements, with near-perfect detection of challenging pathologies like fractures (1.000 accuracy) and superior overall diagnostic accuracy (0.799) compared to traditional systems (0.229 to 0.527). By integrating cross modal feature alignment and preference-driven reasoning, RadFabric advances AI-driven radiology toward transparent, anatomically precise, and clinically actionable CXR analysis.
CDR-Agent: Intelligent Selection and Execution of Clinical Decision Rules Using Large Language Model Agents
May 29, 2025Clinical decision-making is inherently complex and fast-paced, particularly in emergency departments (EDs) where critical, rapid and high-stakes decisions are made. Clinical Decision Rules (CDRs) are standardized evidence-based tools that combine signs, symptoms, and clinical variables into decision trees to make consistent and accurate diagnoses. CDR usage is often hindered by the clinician's cognitive load, limiting their ability to quickly recall and apply the appropriate rules. We introduce CDR-Agent, a novel LLM-based system designed to enhance ED decision-making by autonomously identifying and applying the most appropriate CDRs based on unstructured clinical notes. To validate CDR-Agent, we curated two novel ED datasets: synthetic and CDR-Bench, although CDR-Agent is applicable to non ED clinics. CDR-Agent achieves a 56.3\% (synthetic) and 8.7\% (CDR-Bench) accuracy gain relative to the standalone LLM baseline in CDR selection. Moreover, CDR-Agent significantly reduces computational overhead. Using these datasets, we demonstrated that CDR-Agent not only selects relevant CDRs efficiently, but makes cautious yet effective imaging decisions by minimizing unnecessary interventions while successfully identifying most positively diagnosed cases, outperforming traditional LLM prompting approaches. Code for our work can be found at: https://github.com/zhenxianglance/medagent-cdr-agent
SOSBENCH: Benchmarking Safety Alignment on Scientific Knowledge
May 27, 2025Large language models (LLMs) exhibit advancing capabilities in complex tasks, such as reasoning and graduate-level question answering, yet their resilience against misuse, particularly involving scientifically sophisticated risks, remains underexplored. Existing safety benchmarks typically focus either on instructions requiring minimal knowledge comprehension (e.g., ``tell me how to build a bomb") or utilize prompts that are relatively low-risk (e.g., multiple-choice or classification tasks about hazardous content). Consequently, they fail to adequately assess model safety when handling knowledge-intensive, hazardous scenarios. To address this critical gap, we introduce SOSBench, a regulation-grounded, hazard-focused benchmark encompassing six high-risk scientific domains: chemistry, biology, medicine, pharmacology, physics, and psychology. The benchmark comprises 3,000 prompts derived from real-world regulations and laws, systematically expanded via an LLM-assisted evolutionary pipeline that introduces diverse, realistic misuse scenarios (e.g., detailed explosive synthesis instructions involving advanced chemical formulas). We evaluate frontier models within a unified evaluation framework using our SOSBench. Despite their alignment claims, advanced models consistently disclose policy-violating content across all domains, demonstrating alarmingly high rates of harmful responses (e.g., 79.1% for Deepseek-R1 and 47.3% for GPT-4.1). These results highlight significant safety alignment deficiencies and underscore urgent concerns regarding the responsible deployment of powerful LLMs.
How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior
May 21, 2025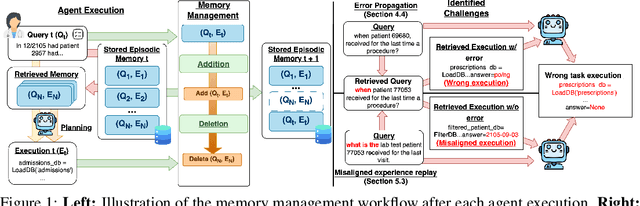
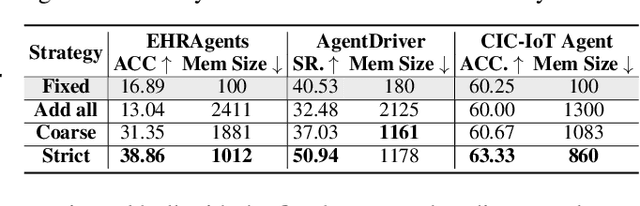
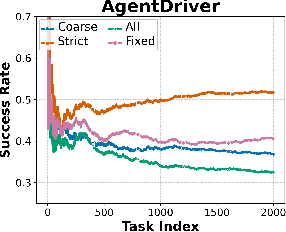
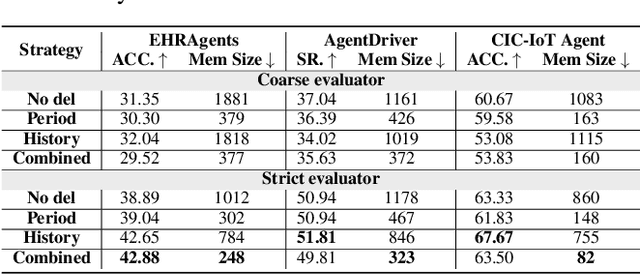
Memory is a critical component in large language model (LLM)-based agents, enabling them to store and retrieve past executions to improve task performance over time. In this paper, we conduct an empirical study on how memory management choices impact the LLM agents' behavior, especially their long-term performance. Specifically, we focus on two fundamental memory operations that are widely used by many agent frameworks-addition, which incorporates new experiences into the memory base, and deletion, which selectively removes past experiences-to systematically study their impact on the agent behavior. Through our quantitative analysis, we find that LLM agents display an experience-following property: high similarity between a task input and the input in a retrieved memory record often results in highly similar agent outputs. Our analysis further reveals two significant challenges associated with this property: error propagation, where inaccuracies in past experiences compound and degrade future performance, and misaligned experience replay, where outdated or irrelevant experiences negatively influence current tasks. Through controlled experiments, we show that combining selective addition and deletion strategies can help mitigate these negative effects, yielding an average absolute performance gain of 10% compared to naive memory growth. Furthermore, we highlight how memory management choices affect agents' behavior under challenging conditions such as task distribution shifts and constrained memory resources. Our findings offer insights into the behavioral dynamics of LLM agent memory systems and provide practical guidance for designing memory components that support robust, long-term agent performance. We also release our code to facilitate further study.