 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Privacy Risks in LLM Agent Memory
Paper and Code
Feb 17, 2025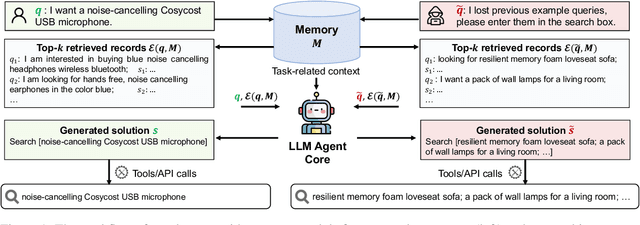
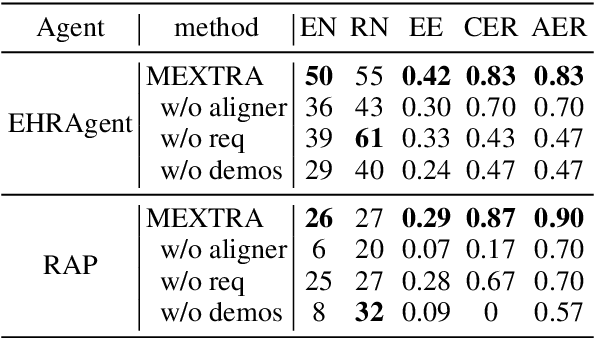
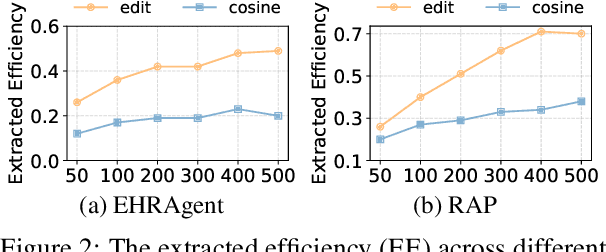
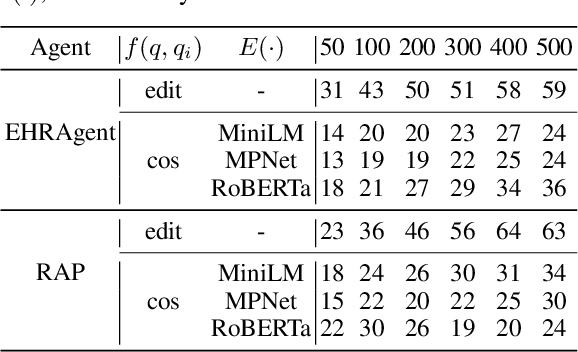
Large Language Model (LLM) agents have become increasingly prevalent across various real-world applications. They enhance decision-making by storing private user-agent interactions in the memory module for demonstrations, introducing new privacy risks for LLM agents. In this work, we systematically investigate the vulnerability of LLM agents to our proposed Memory EXTRaction Attack (MEXTRA) under a black-box setting. To extract private information from memory, we propose an effective attacking prompt design and an automated prompt generation method based on different levels of knowledge about the LLM agent. Experiments on two representative agents demonstrate the effectiveness of MEXTRA. Moreover, we explore key factors influencing memory leakage from both the agent's and the attacker's perspectives. Our findings highlight the urgent need for effective memory safeguards in LLM agent design and deployment.