 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadFabric: Agentic AI System with Reasoning Capability for Radiology
Jun 17, 2025Chest X ray (CXR) imaging remains a critical diagnostic tool for thoracic conditions, but current automated systems face limitations in pathology coverage, diagnostic accuracy, and integration of visual and textual reasoning. To address these gaps, we propose RadFabric, a multi agent, multimodal reasoning framework that unifies visual and textual analysis for comprehensive CXR interpretation. RadFabric is built on the Model Context Protocol (MCP), enabling modularity, interoperability, and scalability for seamless integration of new diagnostic agents. The system employs specialized CXR agents for pathology detection, an Anatomical Interpretation Agent to map visual findings to precise anatomical structures, and a Reasoning Agent powered by large multimodal reasoning models to synthesize visual, anatomical, and clinical data into transparent and evidence based diagnoses. RadFabric achieves significant performance improvements, with near-perfect detection of challenging pathologies like fractures (1.000 accuracy) and superior overall diagnostic accuracy (0.799) compared to traditional systems (0.229 to 0.527). By integrating cross modal feature alignment and preference-driven reasoning, RadFabric advances AI-driven radiology toward transparent, anatomically precise, and clinically actionable CXR analysis.
Developing a PET/CT Foundation Model for Cross-Modal Anatomical and Functional Imaging
Mar 04, 2025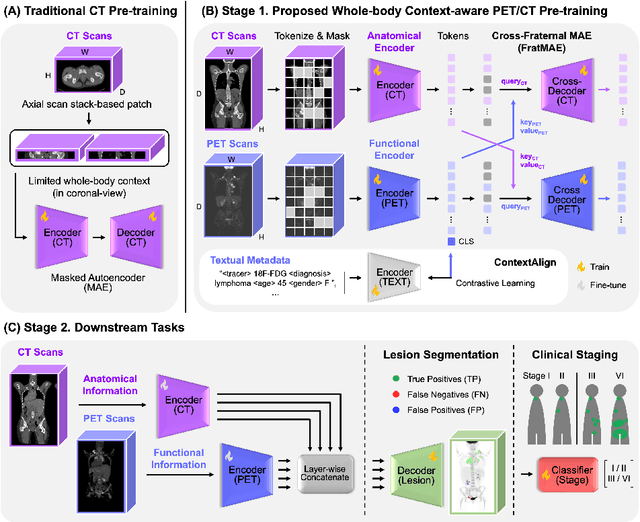


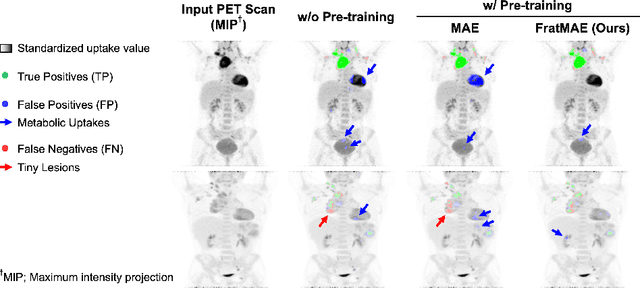
In oncology, Positron Emission Tomography-Computed Tomography (PET/CT) is widely used in cancer diagnosis, staging, and treatment monitoring, as it combines anatomical details from CT with functional metabolic activity and molecular marker expression information from PET. However, existing artificial intelligence-driven PET/CT analyses rely predominantly on task-specific models trained from scratch or on limited datasets, limiting their generalizability and robustness. To address this, we propose a foundation model approach specifically designed for multimodal PET/CT imaging. We introduce the Cross-Fraternal Twin Masked Autoencoder (FratMAE), a novel framework that effectively integrates whole-body anatomical and functional or molecular information. FratMAE employs separate Vision Transformer (ViT) encoders for PET and CT scans, along with cross-attention decoders that enable synergistic interactions between modalities during masked autoencoder training. Additionally, it incorporates textual metadata to enhance PET representation learning. By pre-training on PET/CT datasets, FratMAE captures intricate cross-modal relationships and global uptake patterns, achieving superior performance on downstream tasks and demonstrating its potential as a generalizable foundation model.
Enhancing LLMs for Impression Generation in Radiology Reports through a Multi-Agent System
Dec 06, 2024This study introduces "RadCouncil," a multi-agent Large Language Model (LLM) framework designed to enhance the generation of impressions in radiology reports from the finding section. RadCouncil comprises three specialized agents: 1) a "Retrieval" Agent that identifies and retrieves similar reports from a vector database, 2) a "Radiologist" Agent that generates impressions based on the finding section of the given report plus the exemplar reports retrieved by the Retrieval Agent, and 3) a "Reviewer" Agent that evaluates the generated impressions and provides feedback. The performance of RadCouncil was evaluated using both quantitative metrics (BLEU, ROUGE, BERTScore) and qualitative criteria assessed by GPT-4, using chest X-ray as a case study. Experiment results show improvements in RadCouncil over the single-agent approach across multiple dimensions, including diagnostic accuracy, stylistic concordance, and clarity. This study highlights the potential of utilizing multiple interacting LLM agents, each with a dedicated task, to enhance performance in specialized medical tasks and the development of more robust and adaptable healthcare AI solutions.
Eye-gaze Guided Multi-modal Alignment Framework for Radiology
Mar 19, 2024



In multi-modal frameworks, the alignment of cross-modal features presents a significant challenge. The predominant approach in multi-modal pre-training emphasizes either global or local alignment between modalities, utilizing extensive datasets. This bottom-up driven method often suffers from a lack of interpretability, a critical concern in radiology. Previous studies have integrated high-level labels in medical images or text, but these still rely on manual annotation, a costly and labor-intensive process. Our work introduces a novel approach by using eye-gaze data, collected synchronously by radiologists during diagnostic evaluations. This data, indicating radiologists' focus areas, naturally links chest X-rays to diagnostic texts. We propose the Eye-gaze Guided Multi-modal Alignment (EGMA) framework to harness eye-gaze data for better alignment of image and text features, aiming to reduce reliance on manual annotations and thus cut training costs. Our model demonstrates robust performance, outperforming other state-of-the-art methods in zero-shot classification and retrieval tasks. The incorporation of easily-obtained eye-gaze data during routine radiological diagnoses signifies a step towards minimizing manual annotation dependency. Additionally, we explore the impact of varying amounts of eye-gaze data on model performance, highlighting the feasibility and utility of integrating this auxiliary data into multi-modal pre-training.