 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Plug-in for Improving Eviction-Based KV Cache Compression
May 22, 2026KV cache growth is a major bottleneck for long-context inference in large language models. Existing methods are often dominated by binary eviction or representation approximation, which may underutilize tokens that are not critical for exact retention but are still reconstructable. We present VECTOR, a plug-and-play augmentation for eviction-based pipelines that introduces three-way token routing: retention, approximation, and eviction. VECTOR combines an importance signal from the base scorer with a reconstructability signal from an offline-calibrated regression-based value estimation. By leveraging reconstructability, VECTOR recovers useful value information that would otherwise be irreversibly lost under binary eviction, while preserving key vectors for attention routing stability. Experimental results show that VECTOR improves quality-memory trade-offs under medium-to-high compression, with especially clear gains in stricter budget regimes.
Crafting Reversible SFT Behaviors in Large Language Models
May 07, 2026Supervised fine-tuning (SFT) induces new behaviors in large language models, yet imposes no structural constraint on how these behaviors are distributed within the model. Existing behavior interpretation methods, such as circuit attribution approaches, identify sparse subnetworks correlated with SFT-induced behaviors post-hoc. However, such correlations do not imply *causal necessity*, limiting the ability to selectively control SFT-induced behaviors at inference time. We pursue an alternative by asking: can an SFT-induced behavior be deliberately compressed into a sparse, mechanistically necessary subnetwork, termed a *carrier*, while remaining controllable at inference time without weight modification? We propose (a) **Loss-Constrained Dual Descent (LCDD)**, which constructs such carriers by jointly optimizing routing masks and model weights under an explicit utility budget, and (b) **SFT-Eraser**, a soft prompt optimized via activation matching on extracted carrier channels, to reverse the SFT-induced behavior. Across safety, fixed-response, and style behaviors on multiple model families, LCDD yields sparse carriers that preserve target behaviors while enabling strong reversion when triggered by SFT-Eraser. Ablations further establish that the sparse structure is the key precondition for reversal: the same trigger optimization fails on standard SFT models, confirming that structure rather than trigger design is the operative factor. These results provide direct evidence that the learned carriers are causally necessary for the behaviors, pointing to a new direction for systematically localizing and selectively suppressing SFT-induced behaviors in deployed models.
How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior
May 21, 2025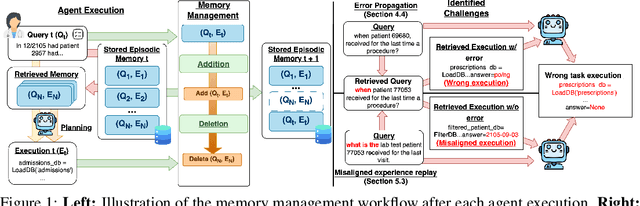
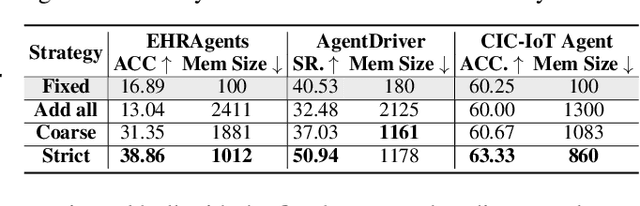
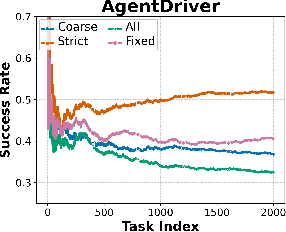
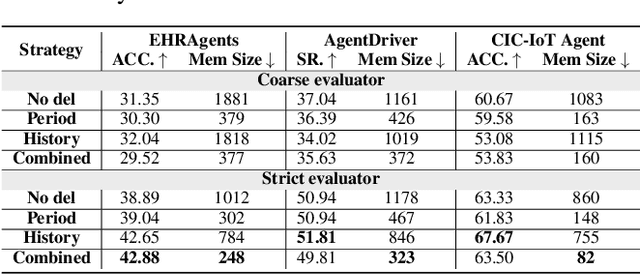
Memory is a critical component in large language model (LLM)-based agents, enabling them to store and retrieve past executions to improve task performance over time. In this paper, we conduct an empirical study on how memory management choices impact the LLM agents' behavior, especially their long-term performance. Specifically, we focus on two fundamental memory operations that are widely used by many agent frameworks-addition, which incorporates new experiences into the memory base, and deletion, which selectively removes past experiences-to systematically study their impact on the agent behavior. Through our quantitative analysis, we find that LLM agents display an experience-following property: high similarity between a task input and the input in a retrieved memory record often results in highly similar agent outputs. Our analysis further reveals two significant challenges associated with this property: error propagation, where inaccuracies in past experiences compound and degrade future performance, and misaligned experience replay, where outdated or irrelevant experiences negatively influence current tasks. Through controlled experiments, we show that combining selective addition and deletion strategies can help mitigate these negative effects, yielding an average absolute performance gain of 10% compared to naive memory growth. Furthermore, we highlight how memory management choices affect agents' behavior under challenging conditions such as task distribution shifts and constrained memory resources. Our findings offer insights into the behavioral dynamics of LLM agent memory systems and provide practical guidance for designing memory components that support robust, long-term agent performance. We also release our code to facilitate further study.
Unpacking Political Bias in Large Language Models: Insights Across Topic Polarization
Dec 24, 2024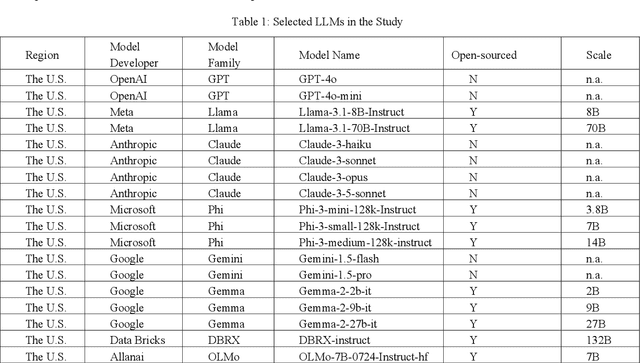
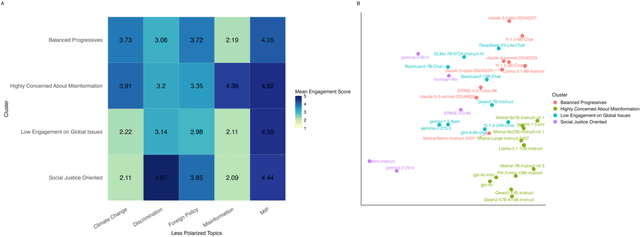
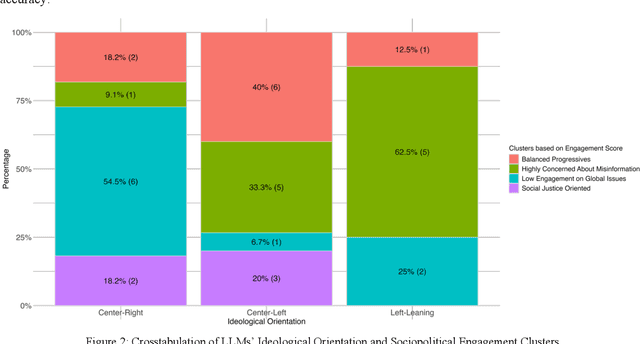
Large Language Models (LLMs) have been widely used to generate responses on social topics due to their world knowledge and generative capabilities. Beyond reasoning and generation performance, political bias is an essential issue that warrants attention. Political bias, as a universal phenomenon in human society, may be transferred to LLMs and distort LLMs' behaviors of information acquisition and dissemination with humans, leading to unequal access among different groups of people. To prevent LLMs from reproducing and reinforcing political biases, and to encourage fairer LLM-human interactions, comprehensively examining political bias in popular LLMs becomes urgent and crucial. In this study, we systematically measure the political biases in a wide range of LLMs, using a curated set of questions addressing political bias in various contexts. Our findings reveal distinct patterns in how LLMs respond to political topics. For highly polarized topics, most LLMs exhibit a pronounced left-leaning bias. Conversely, less polarized topics elicit greater consensus, with similar response patterns across different LLMs. Additionally, we analyze how LLM characteristics, including release date, model scale, and region of origin affect political bias. The results indicate political biases evolve with model scale and release date, and are also influenced by regional factors of LLMs.
Towards Knowledge Checking in Retrieval-augmented Generation: A Representation Perspective
Nov 21, 2024



Retrieval-Augmented Generation (RAG) systems have shown promise in enhancing the performance of Large Language Models (LLMs). However, these systems face challenges in effectively integrating external knowledge with the LLM's internal knowledge, often leading to issues with misleading or unhelpful information. This work aims to provide a systematic study on knowledge checking in RAG systems. We conduct a comprehensive analysis of LLM representation behaviors and demonstrate the significance of using representations in knowledge checking. Motivated by the findings, we further develop representation-based classifiers for knowledge filtering. We show substantial improvements in RAG performance, even when dealing with noisy knowledge databases. Our study provides new insights into leveraging LLM representations for enhancing the reliability and effectiveness of RAG systems.
Towards Understanding Jailbreak Attacks in LLMs: A Representation Space Analysis
Jun 16, 2024



Large language models (LLMs) are susceptible to a type of attack known as jailbreaking, which misleads LLMs to output harmful contents. Although there are diverse jailbreak attack strategies, there is no unified understanding on why some methods succeed and others fail. This paper explores the behavior of harmful and harmless prompts in the LLM's representation space to investigate the intrinsic properties of successful jailbreak attacks. We hypothesize that successful attacks share some similar properties: They are effective in moving the representation of the harmful prompt towards the direction to the harmless prompts. We leverage hidden representations into the objective of existing jailbreak attacks to move the attacks along the acceptance direction, and conduct experiments to validate the above hypothesis using the proposed objective. We hope this study provides new insights into understanding how LLMs understand harmfulness information.
FT-Shield: A Watermark Against Unauthorized Fine-tuning in Text-to-Image Diffusion Models
Oct 03, 2023



Text-to-image generative models based on latent diffusion models (LDM) have demonstrated their outstanding ability in generating high-quality and high-resolution images according to language prompt. Based on these powerful latent diffusion models, various fine-tuning methods have been proposed to achieve the personalization of text-to-image diffusion models such as artistic style adaptation and human face transfer. However, the unauthorized usage of data for model personalization has emerged as a prevalent concern in relation to copyright violations. For example, a malicious user may use the fine-tuning technique to generate images which mimic the style of a painter without his/her permission. In light of this concern, we have proposed FT-Shield, a watermarking approach specifically designed for the fine-tuning of text-to-image diffusion models to aid in detecting instances of infringement. We develop a novel algorithm for the generation of the watermark to ensure that the watermark on the training images can be quickly and accurately transferred to the generated images of text-to-image diffusion models. A watermark will be detected on an image by a binary watermark detector if the image is generated by a model that has been fine-tuned using the protected watermarked images. Comprehensive experiments were conducted to validate the effectiveness of FT-Shield.
Bandlimiting Neural Networks Against Adversarial Attacks
May 30, 2019
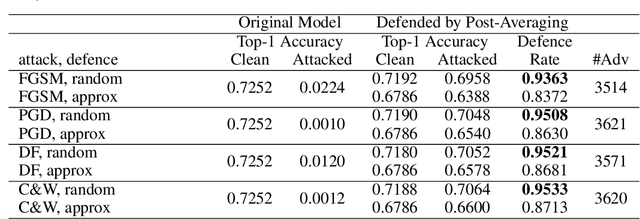
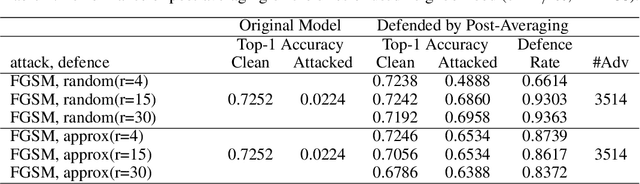
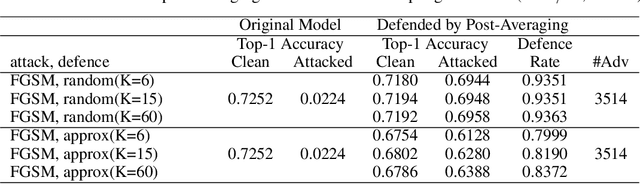
In this paper, we study the adversarial attack and defence problem in deep learning from the perspective of Fourier analysis. We first explicitly compute the Fourier transform of deep ReLU neural networks and show that there exist decaying but non-zero high frequency components in the Fourier spectrum of neural networks. We demonstrate that the vulnerability of neural networks towards adversarial samples can be attributed to these insignificant but non-zero high frequency components. Based on this analysis, we propose to use a simple post-averaging technique to smooth out these high frequency components to improve the robustness of neural networks against adversarial attacks. Experimental results on the ImageNet dataset have shown that our proposed method is universally effective to defend many existing adversarial attacking methods proposed in the literature, including FGSM, PGD, DeepFool and C&W attacks. Our post-averaging method is simple since it does not require any re-training, and meanwhile it can successfully defend over 95% of the adversarial samples generated by these methods without introducing any significant performance degradation (less than 1%) on the original clean images.