 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Heterogeneous Data with Coordinated Agent Flows for Social Media Analysis
Oct 30, 2025Social media platforms generate massive volumes of heterogeneous data, capturing user behaviors, textual content, temporal dynamics, and network structures. Analyzing such data is crucial for understanding phenomena such as opinion dynamics, community formation, and information diffusion. However, discovering insights from this complex landscape is exploratory, conceptually challenging, and requires expertise in social media mining and visualization. Existing automated approaches, though increasingly leveraging large language models (LLMs), remain largely confined to structured tabular data and cannot adequately address the heterogeneity of social media analysis. We present SIA (Social Insight Agents), an LLM agent system that links heterogeneous multi-modal data -- including raw inputs (e.g., text, network, and behavioral data), intermediate outputs, mined analytical results, and visualization artifacts -- through coordinated agent flows. Guided by a bottom-up taxonomy that connects insight types with suitable mining and visualization techniques, SIA enables agents to plan and execute coherent analysis strategies. To ensure multi-modal integration, it incorporates a data coordinator that unifies tabular, textual, and network data into a consistent flow. Its interactive interface provides a transparent workflow where users can trace, validate, and refine the agent's reasoning, supporting both adaptability and trustworthiness. Through expert-centered case studies and quantitative evaluation, we show that SIA effectively discovers diverse and meaningful insights from social media while supporting human-agent collaboration in complex analytical tasks.
Recalibrating the Compass: Integrating Large Language Models into Classical Research Methods
May 26, 2025This paper examines how large language models (LLMs) are transforming core quantitative methods in communication research in particular, and in the social sciences more broadly-namely, content analysis, survey research, and experimental studies. Rather than replacing classical approaches, LLMs introduce new possibilities for coding and interpreting text, simulating dynamic respondents, and generating personalized and interactive stimuli. Drawing on recent interdisciplinary work, the paper highlights both the potential and limitations of LLMs as research tools, including issues of validity, bias, and interpretability. To situate these developments theoretically, the paper revisits Lasswell's foundational framework -- "Who says what, in which channel, to whom, with what effect?" -- and demonstrates how LLMs reconfigure message studies, audience analysis, and effects research by enabling interpretive variation, audience trajectory modeling, and counterfactual experimentation. Revisiting the metaphor of the methodological compass, the paper argues that classical research logics remain essential as the field integrates LLMs and generative AI. By treating LLMs not only as technical instruments but also as epistemic and cultural tools, the paper calls for thoughtful, rigorous, and imaginative use of LLMs in future communication and social science research.
Embracing Dialectic Intersubjectivity: Coordination of Different Perspectives in Content Analysis with LLM Persona Simulation
Feb 04, 2025



This study attempts to advancing content analysis methodology from consensus-oriented to coordination-oriented practices, thereby embracing diverse coding outputs and exploring the dynamics among differential perspectives. As an exploratory investigation of this approach, we evaluate six GPT-4o configurations to analyze sentiment in Fox News and MSNBC transcripts on Biden and Trump during the 2020 U.S. presidential campaign, examining patterns across these models. By assessing each model's alignment with ideological perspectives, we explore how partisan selective processing could be identified in LLM-Assisted Content Analysis (LACA). Findings reveal that partisan persona LLMs exhibit stronger ideological biases when processing politically congruent content. Additionally, intercoder reliability is higher among same-partisan personas compared to cross-partisan pairs. This approach enhances the nuanced understanding of LLM outputs and advances the integrity of AI-driven social science research, enabling simulations of real-world implications.
Unpacking Political Bias in Large Language Models: Insights Across Topic Polarization
Dec 24, 2024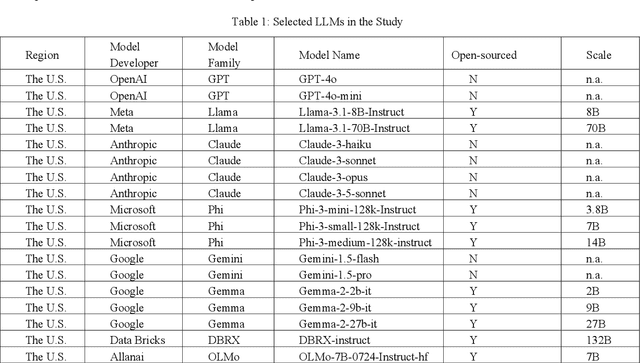
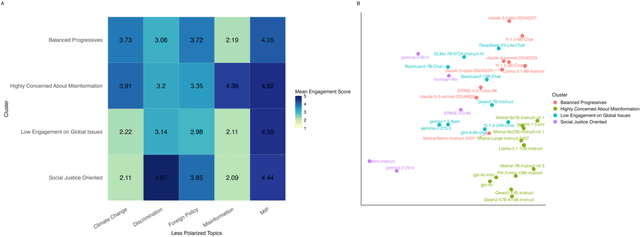
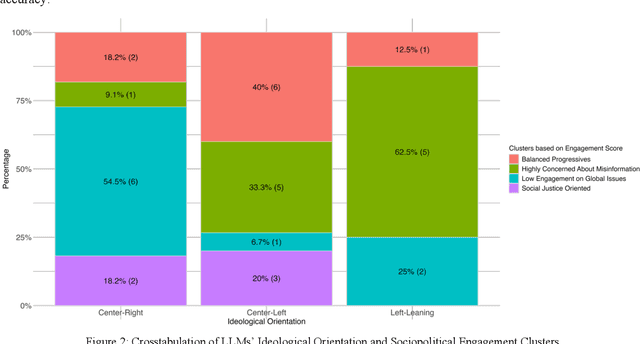
Large Language Models (LLMs) have been widely used to generate responses on social topics due to their world knowledge and generative capabilities. Beyond reasoning and generation performance, political bias is an essential issue that warrants attention. Political bias, as a universal phenomenon in human society, may be transferred to LLMs and distort LLMs' behaviors of information acquisition and dissemination with humans, leading to unequal access among different groups of people. To prevent LLMs from reproducing and reinforcing political biases, and to encourage fairer LLM-human interactions, comprehensively examining political bias in popular LLMs becomes urgent and crucial. In this study, we systematically measure the political biases in a wide range of LLMs, using a curated set of questions addressing political bias in various contexts. Our findings reveal distinct patterns in how LLMs respond to political topics. For highly polarized topics, most LLMs exhibit a pronounced left-leaning bias. Conversely, less polarized topics elicit greater consensus, with similar response patterns across different LLMs. Additionally, we analyze how LLM characteristics, including release date, model scale, and region of origin affect political bias. The results indicate political biases evolve with model scale and release date, and are also influenced by regional factors of LLMs.
Exploring Social Desirability Response Bias in Large Language Models: Evidence from GPT-4 Simulations
Oct 20, 2024Large language models (LLMs) are employed to simulate human-like responses in social surveys, yet it remains unclear if they develop biases like social desirability response (SDR) bias. To investigate this, GPT-4 was assigned personas from four societies, using data from the 2022 Gallup World Poll. These synthetic samples were then prompted with or without a commitment statement intended to induce SDR. The results were mixed. While the commitment statement increased SDR index scores, suggesting SDR bias, it reduced civic engagement scores, indicating an opposite trend. Additional findings revealed demographic associations with SDR scores and showed that the commitment statement had limited impact on GPT-4's predictive performance. The study underscores potential avenues for using LLMs to investigate biases in both humans and LLMs themselves.