 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Solution Divergence and Its Effect on Large Language Model Problem Solving
Sep 26, 2025Large language models (LLMs) have been widely used for problem-solving tasks. Most recent work improves their performance through supervised fine-tuning (SFT) with labeled data or reinforcement learning (RL) from task feedback. In this paper, we study a new perspective: the divergence in solutions generated by LLMs for a single problem. We show that higher solution divergence is positively related to better problem-solving abilities across various models. Based on this finding, we propose solution divergence as a novel metric that can support both SFT and RL strategies. We test this idea on three representative problem domains and find that using solution divergence consistently improves success rates. These results suggest that solution divergence is a simple but effective tool for advancing LLM training and evaluation.
LLM-based Automated Grading with Human-in-the-Loop
Apr 07, 2025The rise of artificial intelligence (AI) technologies, particularly large language models (LLMs), has brought significant advancements to the field of education. Among various applications, automatic short answer grading (ASAG), which focuses on evaluating open-ended textual responses, has seen remarkable progress with the introduction of LLMs. These models not only enhance grading performance compared to traditional ASAG approaches but also move beyond simple comparisons with predefined "golden" answers, enabling more sophisticated grading scenarios, such as rubric-based evaluation. However, existing LLM-powered methods still face challenges in achieving human-level grading performance in rubric-based assessments due to their reliance on fully automated approaches. In this work, we explore the potential of LLMs in ASAG tasks by leveraging their interactive capabilities through a human-in-the-loop (HITL) approach. Our proposed framework, GradeHITL, utilizes the generative properties of LLMs to pose questions to human experts, incorporating their insights to refine grading rubrics dynamically. This adaptive process significantly improves grading accuracy, outperforming existing methods and bringing ASAG closer to human-level evaluation.
Enhancing LLM-Based Short Answer Grading with Retrieval-Augmented Generation
Apr 07, 2025



Short answer assessment is a vital component of science education, allowing evaluation of students' complex three-dimensional understanding. Large language models (LLMs) that possess human-like ability in linguistic tasks are increasingly popular in assisting human graders to reduce their workload. However, LLMs' limitations in domain knowledge restrict their understanding in task-specific requirements and hinder their ability to achieve satisfactory performance. Retrieval-augmented generation (RAG) emerges as a promising solution by enabling LLMs to access relevant domain-specific knowledge during assessment. In this work, we propose an adaptive RAG framework for automated grading that dynamically retrieves and incorporates domain-specific knowledge based on the question and student answer context. Our approach combines semantic search and curated educational sources to retrieve valuable reference materials. Experimental results in a science education dataset demonstrate that our system achieves an improvement in grading accuracy compared to baseline LLM approaches. The findings suggest that RAG-enhanced grading systems can serve as reliable support with efficient performance gains.
Unpacking Political Bias in Large Language Models: Insights Across Topic Polarization
Dec 24, 2024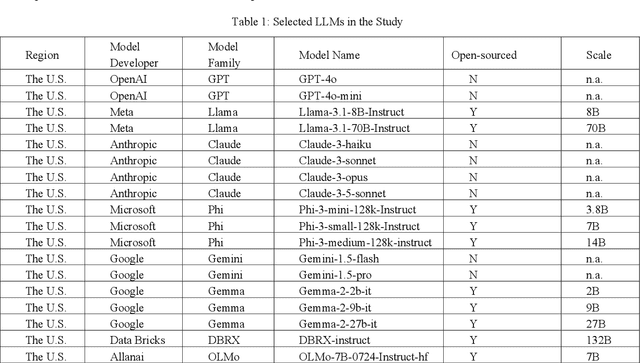
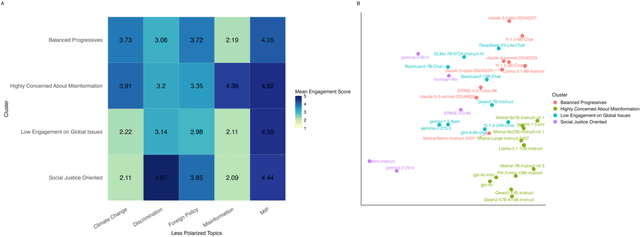
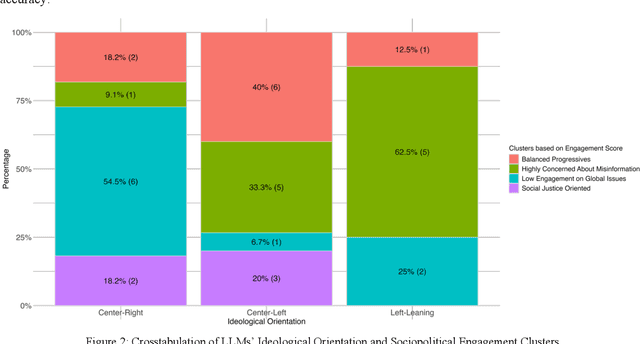
Large Language Models (LLMs) have been widely used to generate responses on social topics due to their world knowledge and generative capabilities. Beyond reasoning and generation performance, political bias is an essential issue that warrants attention. Political bias, as a universal phenomenon in human society, may be transferred to LLMs and distort LLMs' behaviors of information acquisition and dissemination with humans, leading to unequal access among different groups of people. To prevent LLMs from reproducing and reinforcing political biases, and to encourage fairer LLM-human interactions, comprehensively examining political bias in popular LLMs becomes urgent and crucial. In this study, we systematically measure the political biases in a wide range of LLMs, using a curated set of questions addressing political bias in various contexts. Our findings reveal distinct patterns in how LLMs respond to political topics. For highly polarized topics, most LLMs exhibit a pronounced left-leaning bias. Conversely, less polarized topics elicit greater consensus, with similar response patterns across different LLMs. Additionally, we analyze how LLM characteristics, including release date, model scale, and region of origin affect political bias. The results indicate political biases evolve with model scale and release date, and are also influenced by regional factors of LLMs.
Ask-Before-Detection: Identifying and Mitigating Conformity Bias in LLM-Powered Error Detector for Math Word Problem Solutions
Dec 22, 2024



The rise of large language models (LLMs) offers new opportunities for automatic error detection in education, particularly for math word problems (MWPs). While prior studies demonstrate the promise of LLMs as error detectors, they overlook the presence of multiple valid solutions for a single MWP. Our preliminary analysis reveals a significant performance gap between conventional and alternative solutions in MWPs, a phenomenon we term conformity bias in this work. To mitigate this bias, we introduce the Ask-Before-Detect (AskBD) framework, which generates adaptive reference solutions using LLMs to enhance error detection. Experiments on 200 examples of GSM8K show that AskBD effectively mitigates bias and improves performance, especially when combined with reasoning-enhancing techniques like chain-of-thought prompting.
A LLM-Powered Automatic Grading Framework with Human-Level Guidelines Optimization
Oct 03, 2024



Open-ended short-answer questions (SAGs) have been widely recognized as a powerful tool for providing deeper insights into learners' responses in the context of learning analytics (LA). However, SAGs often present challenges in practice due to the high grading workload and concerns about inconsistent assessments. With recent advancements in natural language processing (NLP), automatic short-answer grading (ASAG) offers a promising solution to these challenges. Despite this, current ASAG algorithms are often limited in generalizability and tend to be tailored to specific questions. In this paper, we propose a unified multi-agent ASAG framework, GradeOpt, which leverages large language models (LLMs) as graders for SAGs. More importantly, GradeOpt incorporates two additional LLM-based agents - the reflector and the refiner - into the multi-agent system. This enables GradeOpt to automatically optimize the original grading guidelines by performing self-reflection on its errors. Through experiments on a challenging ASAG task, namely the grading of pedagogical content knowledge (PCK) and content knowledge (CK) questions, GradeOpt demonstrates superior performance in grading accuracy and behavior alignment with human graders compared to representative baselines. Finally, comprehensive ablation studies confirm the effectiveness of the individual components designed in GradeOpt.