 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"**Important** You should give me full credits!": Exploring Prompt Injection Attacks on LLM-Based Automatic Grading Systems
Jun 02, 2026The emergence of large language models (LLMs) has significantly accelerated recent research on LLM-based automatic grading (AG) systems. Benefiting from the strong instruction-following capabilities and broad prior knowledge of LLMs, educators can deploy AG systems across diverse tasks using only natural language rubrics while achieving satisfactory grading performance. Despite these advantages, new security concerns may also arise. In particular, prompt injection (PI) attacks have recently become a major threat to LLM-based applications. In the context of AG, attackers can potentially exploit PI vulnerabilities to manipulate grading systems into assigning artificially high scores regardless of the actual answer quality. Such behavior poses serious risks to the fairness, reliability, and integrity of educational assessment. In this work, we study PI attacks in AG systems, and systematically investigate the effectiveness of such attacks in educational scenarios. We further evaluate the effectiveness of existing defensive strategies against these attacks. Through comprehensive experiments under rubric-based grading settings, we demonstrate that current LLM-based AG systems remain highly vulnerable to PI attacks. We hope that our findings raise awareness of this emerging threat and motivate future research toward secure, robust, and trustworthy LLM-based educational systems.
Think-Before-Speak: From Internal Evaluation to Public Expression in Multi-Agent Social Simulation
Jun 02, 2026LLM-based multi-agent simulation offers a promising way to study social interaction, deliberation, and collective opinion dynamics. However, many existing dialogue simulation frameworks represent interaction mainly as observable turn exchange or aggregated outputs, leaving the internal evaluative processes behind silence, speaking intention, and public expression difficult to examine. We introduce TBS (Think-Before-Speak), an interval-based multi-agent simulation framework that separates agents' private reasoning from public utterance generation. At each interval, all agents update structured internal states based on the shared dialogue history and their own memory. These states include dissonance-related appraisal, perceived opinion climate, perceived isolation risk, response strategy, and willingness to speak. The orchestrator then resolves competing speaking intentions and commits one utterance to the public dialogue, allowing internal evaluation and public interaction to co-evolve over time. We evaluate TBS in simulated town hall discussions on a climate-related policy issue. Results show that TBS produces coherent internal-state traces and that these traces vary systematically across turn-allocation, silence, and memory conditions. Dissonance-related appraisal increases agents' willingness to speak, whereas silence-pressure appraisal decreases it. Once speaking intention is formed, public expression is shaped mainly by turn-allocation rules. These findings suggest that TBS supports mechanism-sensitive social simulation by making the pathway from internal evaluation to public expression observable and analyzable.
Optimizing In-Context Demonstrations for LLM-based Automated Grading
Feb 28, 2026Automated assessment of open-ended student responses is a critical capability for scaling personalized feedback in education. While large language models (LLMs) have shown promise in grading tasks via in-context learning (ICL), their reliability is heavily dependent on the selection of few-shot exemplars and the construction of high-quality rationales. Standard retrieval methods typically select examples based on semantic similarity, which often fails to capture subtle decision boundaries required for rubric adherence. Furthermore, manually crafting the expert rationales needed to guide these models can be a significant bottleneck. To address these limitations, we introduce GUIDE (Grading Using Iteratively Designed Exemplars), a framework that reframes exemplar selection and refinement in automated grading as a boundary-focused optimization problem. GUIDE operates on a continuous loop of selection and refinement, employing novel contrastive operators to identify "boundary pairs" that are semantically similar but possess different grades. We enhance exemplars by generating discriminative rationales that explicitly articulate why a response receives a specific score to the exclusion of adjacent grades. Extensive experiments across datasets in physics, chemistry, and pedagogical content knowledge demonstrate that GUIDE significantly outperforms standard retrieval baselines. By focusing the model's attention on the precise edges of rubric, our approach shows exceptionally robust gains on borderline cases and improved rubric adherence. GUIDE paves the way for trusted, scalable assessment systems that align closely with human pedagogical standards.
Confusion-Aware Rubric Optimization for LLM-based Automated Grading
Feb 28, 2026Accurate and unambiguous guidelines are critical for large language model (LLM) based graders, yet manually crafting these prompts is often sub-optimal as LLMs can misinterpret expert guidelines or lack necessary domain specificity. Consequently, the field has moved toward automated prompt optimization to refine grading guidelines without the burden of manual trial and error. However, existing frameworks typically aggregate independent and unstructured error samples into a single update step, resulting in "rule dilution" where conflicting constraints weaken the model's grading logic. To address these limitations, we introduce Confusion-Aware Rubric Optimization (CARO), a novel framework that enhances accuracy and computational efficiency by structurally separating error signals. CARO leverages the confusion matrix to decompose monolithic error signals into distinct modes, allowing for the diagnosis and repair of specific misclassification patterns individually. By synthesizing targeted "fixing patches" for dominant error modes and employing a diversity-aware selection mechanism, the framework prevents guidance conflict and eliminates the need for resource-heavy nested refinement loops. Empirical evaluations on teacher education and STEM datasets demonstrate that CARO significantly outperforms existing SOTA methods. These results suggest that replacing mixed-error aggregation with surgical, mode-specific repair yields robust improvements in automated assessment scalability and precision.
How Uncertain Is the Grade? A Benchmark of Uncertainty Metrics for LLM-Based Automatic Assessment
Feb 17, 2026The rapid rise of large language models (LLMs) is reshaping the landscape of automatic assessment in education. While these systems demonstrate substantial advantages in adaptability to diverse question types and flexibility in output formats, they also introduce new challenges related to output uncertainty, stemming from the inherently probabilistic nature of LLMs. Output uncertainty is an inescapable challenge in automatic assessment, as assessment results often play a critical role in informing subsequent pedagogical actions, such as providing feedback to students or guiding instructional decisions. Unreliable or poorly calibrated uncertainty estimates can lead to unstable downstream interventions, potentially disrupting students' learning processes and resulting in unintended negative consequences. To systematically understand this challenge and inform future research, we benchmark a broad range of uncertainty quantification methods in the context of LLM-based automatic assessment. Although the effectiveness of these methods has been demonstrated in many tasks across other domains, their applicability and reliability in educational settings, particularly for automatic grading, remain underexplored. Through comprehensive analyses of uncertainty behaviors across multiple assessment datasets, LLM families, and generation control settings, we characterize the uncertainty patterns exhibited by LLMs in grading scenarios. Based on these findings, we evaluate the strengths and limitations of different uncertainty metrics and analyze the influence of key factors, including model families, assessment tasks, and decoding strategies, on uncertainty estimates. Our study provides actionable insights into the characteristics of uncertainty in LLM-based automatic assessment and lays the groundwork for developing more reliable and effective uncertainty-aware grading systems in the future.
Exploring Solution Divergence and Its Effect on Large Language Model Problem Solving
Sep 26, 2025Large language models (LLMs) have been widely used for problem-solving tasks. Most recent work improves their performance through supervised fine-tuning (SFT) with labeled data or reinforcement learning (RL) from task feedback. In this paper, we study a new perspective: the divergence in solutions generated by LLMs for a single problem. We show that higher solution divergence is positively related to better problem-solving abilities across various models. Based on this finding, we propose solution divergence as a novel metric that can support both SFT and RL strategies. We test this idea on three representative problem domains and find that using solution divergence consistently improves success rates. These results suggest that solution divergence is a simple but effective tool for advancing LLM training and evaluation.
Enhancing LLM-Based Short Answer Grading with Retrieval-Augmented Generation
Apr 07, 2025



Short answer assessment is a vital component of science education, allowing evaluation of students' complex three-dimensional understanding. Large language models (LLMs) that possess human-like ability in linguistic tasks are increasingly popular in assisting human graders to reduce their workload. However, LLMs' limitations in domain knowledge restrict their understanding in task-specific requirements and hinder their ability to achieve satisfactory performance. Retrieval-augmented generation (RAG) emerges as a promising solution by enabling LLMs to access relevant domain-specific knowledge during assessment. In this work, we propose an adaptive RAG framework for automated grading that dynamically retrieves and incorporates domain-specific knowledge based on the question and student answer context. Our approach combines semantic search and curated educational sources to retrieve valuable reference materials. Experimental results in a science education dataset demonstrate that our system achieves an improvement in grading accuracy compared to baseline LLM approaches. The findings suggest that RAG-enhanced grading systems can serve as reliable support with efficient performance gains.
LLM-based Automated Grading with Human-in-the-Loop
Apr 07, 2025The rise of artificial intelligence (AI) technologies, particularly large language models (LLMs), has brought significant advancements to the field of education. Among various applications, automatic short answer grading (ASAG), which focuses on evaluating open-ended textual responses, has seen remarkable progress with the introduction of LLMs. These models not only enhance grading performance compared to traditional ASAG approaches but also move beyond simple comparisons with predefined "golden" answers, enabling more sophisticated grading scenarios, such as rubric-based evaluation. However, existing LLM-powered methods still face challenges in achieving human-level grading performance in rubric-based assessments due to their reliance on fully automated approaches. In this work, we explore the potential of LLMs in ASAG tasks by leveraging their interactive capabilities through a human-in-the-loop (HITL) approach. Our proposed framework, GradeHITL, utilizes the generative properties of LLMs to pose questions to human experts, incorporating their insights to refine grading rubrics dynamically. This adaptive process significantly improves grading accuracy, outperforming existing methods and bringing ASAG closer to human-level evaluation.
Unpacking Political Bias in Large Language Models: Insights Across Topic Polarization
Dec 24, 2024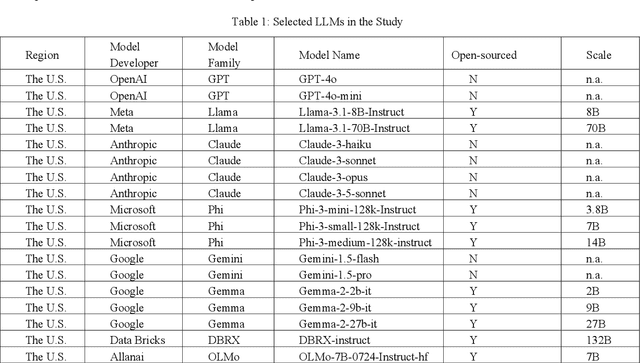
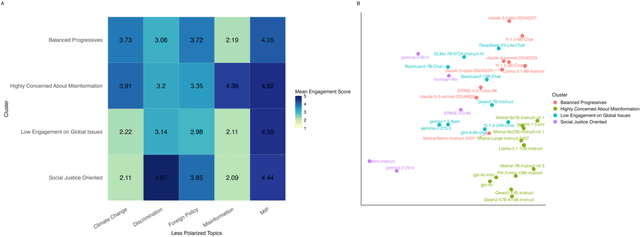
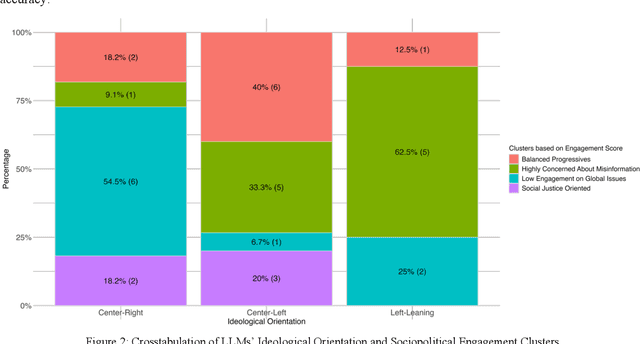
Large Language Models (LLMs) have been widely used to generate responses on social topics due to their world knowledge and generative capabilities. Beyond reasoning and generation performance, political bias is an essential issue that warrants attention. Political bias, as a universal phenomenon in human society, may be transferred to LLMs and distort LLMs' behaviors of information acquisition and dissemination with humans, leading to unequal access among different groups of people. To prevent LLMs from reproducing and reinforcing political biases, and to encourage fairer LLM-human interactions, comprehensively examining political bias in popular LLMs becomes urgent and crucial. In this study, we systematically measure the political biases in a wide range of LLMs, using a curated set of questions addressing political bias in various contexts. Our findings reveal distinct patterns in how LLMs respond to political topics. For highly polarized topics, most LLMs exhibit a pronounced left-leaning bias. Conversely, less polarized topics elicit greater consensus, with similar response patterns across different LLMs. Additionally, we analyze how LLM characteristics, including release date, model scale, and region of origin affect political bias. The results indicate political biases evolve with model scale and release date, and are also influenced by regional factors of LLMs.
Ask-Before-Detection: Identifying and Mitigating Conformity Bias in LLM-Powered Error Detector for Math Word Problem Solutions
Dec 22, 2024



The rise of large language models (LLMs) offers new opportunities for automatic error detection in education, particularly for math word problems (MWPs). While prior studies demonstrate the promise of LLMs as error detectors, they overlook the presence of multiple valid solutions for a single MWP. Our preliminary analysis reveals a significant performance gap between conventional and alternative solutions in MWPs, a phenomenon we term conformity bias in this work. To mitigate this bias, we introduce the Ask-Before-Detect (AskBD) framework, which generates adaptive reference solutions using LLMs to enhance error detection. Experiments on 200 examples of GSM8K show that AskBD effectively mitigates bias and improves performance, especially when combined with reasoning-enhancing techniques like chain-of-thought prompting.