 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025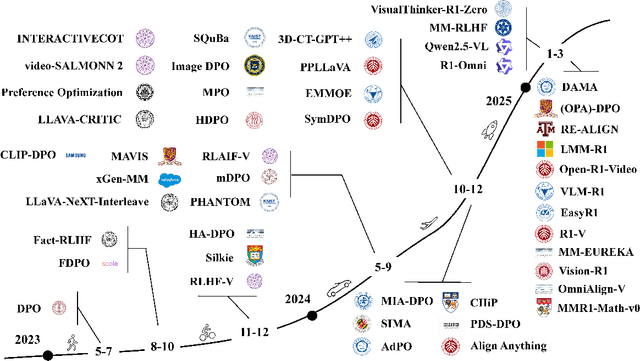
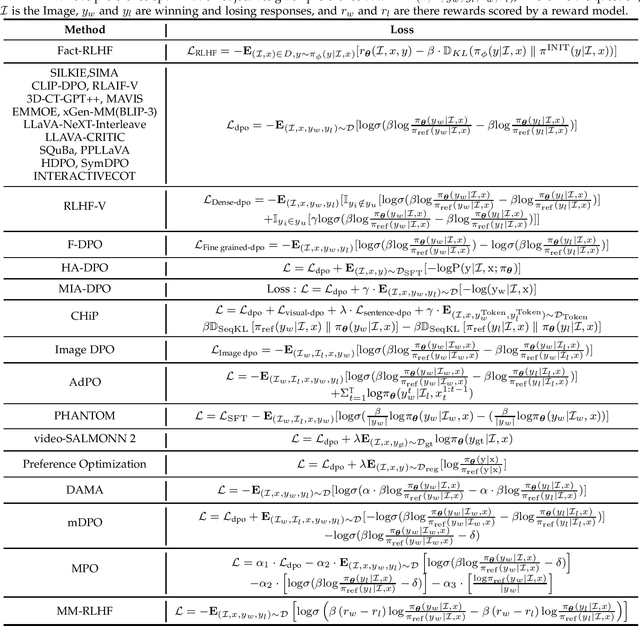
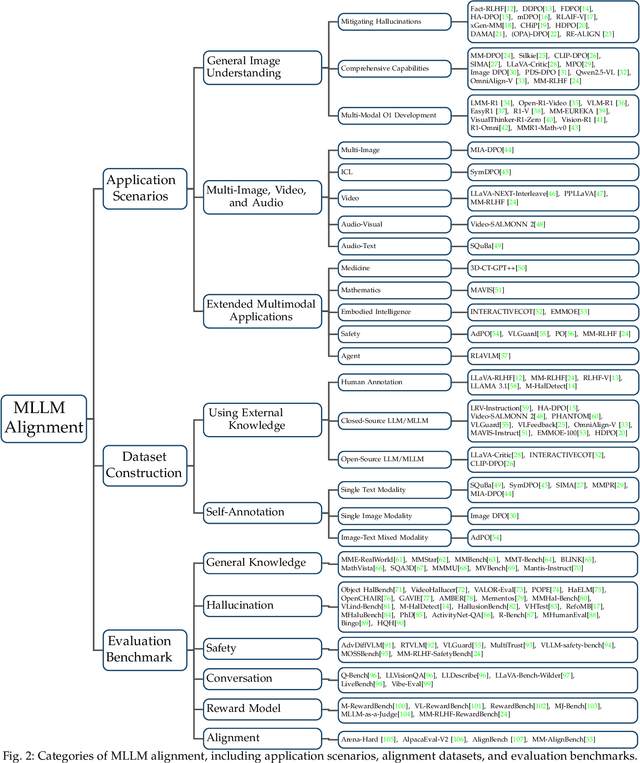
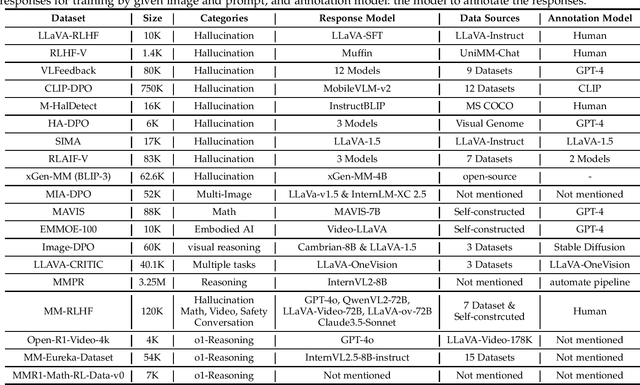
Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
From Correctness to Comprehension: AI Agents for Personalized Error Diagnosis in Education
Feb 19, 2025



Large Language Models (LLMs), such as GPT-4, have demonstrated impressive mathematical reasoning capabilities, achieving near-perfect performance on benchmarks like GSM8K. However, their application in personalized education remains limited due to an overemphasis on correctness over error diagnosis and feedback generation. Current models fail to provide meaningful insights into the causes of student mistakes, limiting their utility in educational contexts. To address these challenges, we present three key contributions. First, we introduce \textbf{MathCCS} (Mathematical Classification and Constructive Suggestions), a multi-modal benchmark designed for systematic error analysis and tailored feedback. MathCCS includes real-world problems, expert-annotated error categories, and longitudinal student data. Evaluations of state-of-the-art models, including \textit{Qwen2-VL}, \textit{LLaVA-OV}, \textit{Claude-3.5-Sonnet} and \textit{GPT-4o}, reveal that none achieved classification accuracy above 30\% or generated high-quality suggestions (average scores below 4/10), highlighting a significant gap from human-level performance. Second, we develop a sequential error analysis framework that leverages historical data to track trends and improve diagnostic precision. Finally, we propose a multi-agent collaborative framework that combines a Time Series Agent for historical analysis and an MLLM Agent for real-time refinement, enhancing error classification and feedback generation. Together, these contributions provide a robust platform for advancing personalized education, bridging the gap between current AI capabilities and the demands of real-world teaching.
Ask-Before-Detection: Identifying and Mitigating Conformity Bias in LLM-Powered Error Detector for Math Word Problem Solutions
Dec 22, 2024



The rise of large language models (LLMs) offers new opportunities for automatic error detection in education, particularly for math word problems (MWPs). While prior studies demonstrate the promise of LLMs as error detectors, they overlook the presence of multiple valid solutions for a single MWP. Our preliminary analysis reveals a significant performance gap between conventional and alternative solutions in MWPs, a phenomenon we term conformity bias in this work. To mitigate this bias, we introduce the Ask-Before-Detect (AskBD) framework, which generates adaptive reference solutions using LLMs to enhance error detection. Experiments on 200 examples of GSM8K show that AskBD effectively mitigates bias and improves performance, especially when combined with reasoning-enhancing techniques like chain-of-thought prompting.
ErrorRadar: Benchmarking Complex Mathematical Reasoning of Multimodal Large Language Models Via Error Detection
Oct 06, 2024


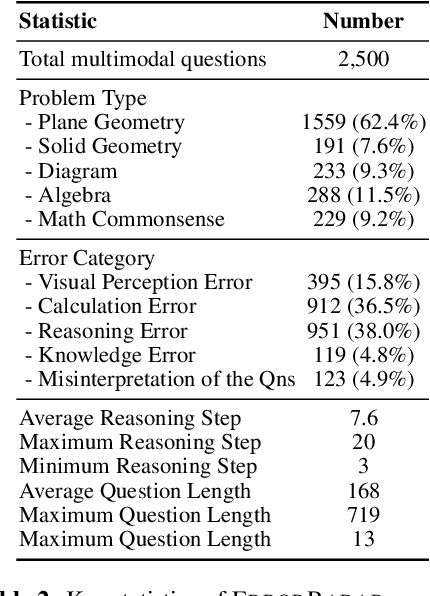
As the field of Multimodal Large Language Models (MLLMs) continues to evolve, their potential to revolutionize artificial intelligence is particularly promising, especially in addressing mathematical reasoning tasks. Current mathematical benchmarks predominantly focus on evaluating MLLMs' problem-solving ability, yet there is a crucial gap in addressing more complex scenarios such as error detection, for enhancing reasoning capability in complicated settings. To fill this gap, we formally formulate the new task: multimodal error detection, and introduce ErrorRadar, the first benchmark designed to assess MLLMs' capabilities in such a task. ErrorRadar evaluates two sub-tasks: error step identification and error categorization, providing a comprehensive framework for evaluating MLLMs' complex mathematical reasoning ability. It consists of 2,500 high-quality multimodal K-12 mathematical problems, collected from real-world student interactions in an educational organization, with rigorous annotation and rich metadata such as problem type and error category. Through extensive experiments, we evaluated both open-source and closed-source representative MLLMs, benchmarking their performance against educational expert evaluators. Results indicate significant challenges still remain, as GPT-4o with best performance is still around 10% behind human evaluation. The dataset will be available upon acceptance.
AI-Driven Virtual Teacher for Enhanced Educational Efficiency: Leveraging Large Pretrain Models for Autonomous Error Analysis and Correction
Sep 14, 2024



Students frequently make mistakes while solving mathematical problems, and traditional error correction methods are both time-consuming and labor-intensive. This paper introduces an innovative \textbf{V}irtual \textbf{A}I \textbf{T}eacher system designed to autonomously analyze and correct student \textbf{E}rrors (VATE). Leveraging advanced large language models (LLMs), the system uses student drafts as a primary source for error analysis, which enhances understanding of the student's learning process. It incorporates sophisticated prompt engineering and maintains an error pool to reduce computational overhead. The AI-driven system also features a real-time dialogue component for efficient student interaction. Our approach demonstrates significant advantages over traditional and machine learning-based error correction methods, including reduced educational costs, high scalability, and superior generalizability. The system has been deployed on the Squirrel AI learning platform for elementary mathematics education, where it achieves 78.3\% accuracy in error analysis and shows a marked improvement in student learning efficiency. Satisfaction surveys indicate a strong positive reception, highlighting the system's potential to transform educational practices.
Knowledge Tagging with Large Language Model based Multi-Agent System
Sep 12, 2024



Knowledge tagging for questions is vital in modern intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations have been performed by pedagogical experts, as the task demands not only a deep semantic understanding of question stems and knowledge definitions but also a strong ability to link problem-solving logic with relevant knowledge concepts. With the advent of advanced natural language processing (NLP) algorithms, such as pre-trained language models and large language models (LLMs), pioneering studies have explored automating the knowledge tagging process using various machine learning models. In this paper, we investigate the use of a multi-agent system to address the limitations of previous algorithms, particularly in handling complex cases involving intricate knowledge definitions and strict numerical constraints. By demonstrating its superior performance on the publicly available math question knowledge tagging dataset, MathKnowCT, we highlight the significant potential of an LLM-based multi-agent system in overcoming the challenges that previous methods have encountered. Finally, through an in-depth discussion of the implications of automating knowledge tagging, we underscore the promising results of deploying LLM-based algorithms in educational contexts.
Knowledge Tagging System on Math Questions via LLMs with Flexible Demonstration Retriever
Jun 19, 2024
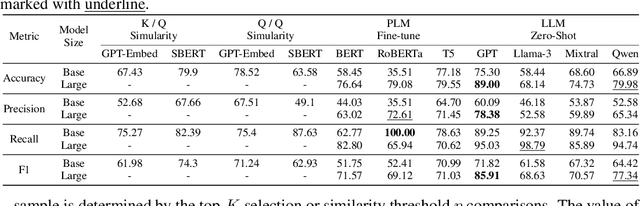


Knowledge tagging for questions plays a crucial role in contemporary intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations are always conducted by pedagogical experts, as the task requires not only a strong semantic understanding of both question stems and knowledge definitions but also deep insights into connecting question-solving logic with corresponding knowledge concepts. With the recent emergence of advanced text encoding algorithms, such as pre-trained language models, many researchers have developed automatic knowledge tagging systems based on calculating the semantic similarity between the knowledge and question embeddings. In this paper, we explore automating the task using Large Language Models (LLMs), in response to the inability of prior encoding-based methods to deal with the hard cases which involve strong domain knowledge and complicated concept definitions. By showing the strong performance of zero- and few-shot results over math questions knowledge tagging tasks, we demonstrate LLMs' great potential in conquering the challenges faced by prior methods. Furthermore, by proposing a reinforcement learning-based demonstration retriever, we successfully exploit the great potential of different-sized LLMs in achieving better performance results while keeping the in-context demonstration usage efficiency high.
Large Language Models for Education: A Survey and Outlook
Apr 01, 2024

The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.
Automate Knowledge Concept Tagging on Math Questions with LLMs
Mar 26, 2024



Knowledge concept tagging for questions plays a crucial role in contemporary intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations have been conducted manually with help from pedagogical experts, as the task requires not only a strong semantic understanding of both question stems and knowledge definitions but also deep insights into connecting question-solving logic with corresponding knowledge concepts. In this paper, we explore automating the tagging task using Large Language Models (LLMs), in response to the inability of prior manual methods to meet the rapidly growing demand for concept tagging in questions posed by advanced educational applications. Moreover, the zero/few-shot learning capability of LLMs makes them well-suited for application in educational scenarios, which often face challenges in collecting large-scale, expertise-annotated datasets. By conducting extensive experiments with a variety of representative LLMs, we demonstrate that LLMs are a promising tool for concept tagging in math questions. Furthermore, through case studies examining the results from different LLMs, we draw some empirical conclusions about the key factors for success in applying LLMs to the automatic concept tagging task.