 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillBrew: Multi-Objective Curation of Skill Banks for LLM Agents
May 28, 2026Retrieval-augmented LLM agents increasingly rely on curated skill banks: collections of reusable textual principles that guide decision making on complex tasks. Existing approaches typically expand these banks in an append-only fashion, continuously adding new skills without removing redundant, outdated, or harmful ones, resulting in inefficient and poorly curated repositories. In this paper, we formulate the skill bank curation as a constrained multi-objective problem: a desirable bank must be useful for the agent, diverse in its content, and provide good coverage of the query distribution. To this end, we introduce SkillBrew, a multi-objective curation framework that formalizes skill bank curation as Pareto-aware optimization under a utility constraint, and solves it via a bi-level propose-then-verify loop. We evaluate our approach on two public benchmarks. Our findings suggest that treating skill banks as objects of principled curation, rather than ever-growing append-only logs, is an important step toward building self-improving LLM agents.
UniEDU: A Unified Language and Vision Assistant for Education Applications
Mar 26, 2025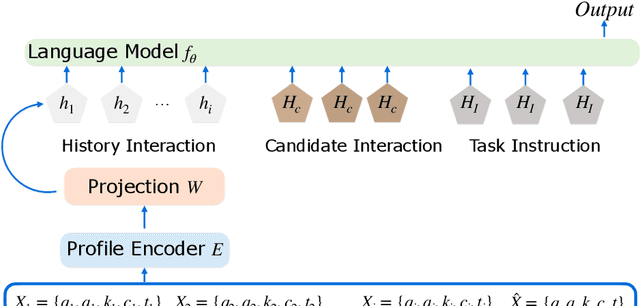
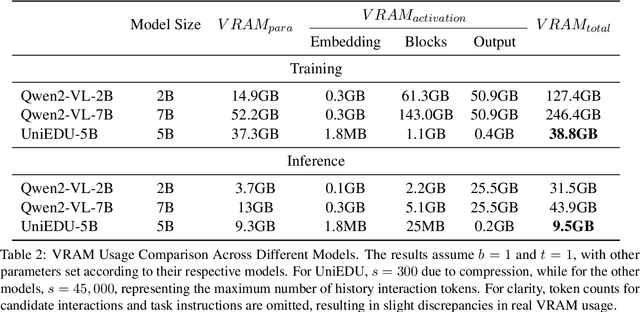
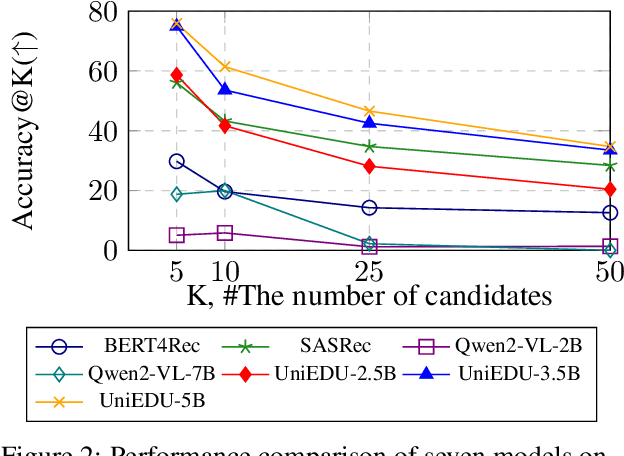
Education materials for K-12 students often consist of multiple modalities, such as text and images, posing challenges for models to fully understand nuanced information in these materials. In this paper, we propose a unified language and vision assistant UniEDU designed for various educational applications, including knowledge recommendation, knowledge tracing, time cost prediction, and user answer prediction, all within a single model. Unlike conventional task-specific models, UniEDU offers a unified solution that excels across multiple educational tasks while maintaining strong generalization capabilities. Its adaptability makes it well-suited for real-world deployment in diverse learning environments. Furthermore, UniEDU is optimized for industry-scale deployment by significantly reducing computational overhead-achieving approximately a 300\% increase in efficiency-while maintaining competitive performance with minimal degradation compared to fully fine-tuned models. This work represents a significant step toward creating versatile AI systems tailored to the evolving demands of education.
LLM Agents for Education: Advances and Applications
Mar 14, 2025Large Language Model (LLM) agents have demonstrated remarkable capabilities in automating tasks and driving innovation across diverse educational applications. In this survey, we provide a systematic review of state-of-the-art research on LLM agents in education, categorizing them into two broad classes: (1) \emph{Pedagogical Agents}, which focus on automating complex pedagogical tasks to support both teachers and students; and (2) \emph{Domain-Specific Educational Agents}, which are tailored for specialized fields such as science education, language learning, and professional development. We comprehensively examine the technological advancements underlying these LLM agents, including key datasets, benchmarks, and algorithmic frameworks that drive their effectiveness. Furthermore, we discuss critical challenges such as privacy, bias and fairness concerns, hallucination mitigation, and integration with existing educational ecosystems. This survey aims to provide a comprehensive technological overview of LLM agents for education, fostering further research and collaboration to enhance their impact for the greater good of learners and educators alike.
Position: Multimodal Large Language Models Can Significantly Advance Scientific Reasoning
Feb 05, 2025



Scientific reasoning, the process through which humans apply logic, evidence, and critical thinking to explore and interpret scientific phenomena, is essential in advancing knowledge reasoning across diverse fields. However, despite significant progress, current scientific reasoning models still struggle with generalization across domains and often fall short of multimodal perception. Multimodal Large Language Models (MLLMs), which integrate text, images, and other modalities, present an exciting opportunity to overcome these limitations and enhance scientific reasoning. Therefore, this position paper argues that MLLMs can significantly advance scientific reasoning across disciplines such as mathematics, physics, chemistry, and biology. First, we propose a four-stage research roadmap of scientific reasoning capabilities, and highlight the current state of MLLM applications in scientific reasoning, noting their ability to integrate and reason over diverse data types. Second, we summarize the key challenges that remain obstacles to achieving MLLM's full potential. To address these challenges, we propose actionable insights and suggestions for the future. Overall, our work offers a novel perspective on MLLM integration with scientific reasoning, providing the LLM community with a valuable vision for achieving Artificial General Intelligence (AGI).
ErrorRadar: Benchmarking Complex Mathematical Reasoning of Multimodal Large Language Models Via Error Detection
Oct 06, 2024


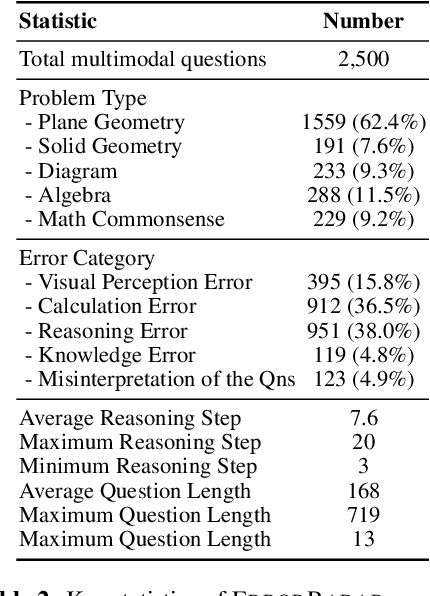
As the field of Multimodal Large Language Models (MLLMs) continues to evolve, their potential to revolutionize artificial intelligence is particularly promising, especially in addressing mathematical reasoning tasks. Current mathematical benchmarks predominantly focus on evaluating MLLMs' problem-solving ability, yet there is a crucial gap in addressing more complex scenarios such as error detection, for enhancing reasoning capability in complicated settings. To fill this gap, we formally formulate the new task: multimodal error detection, and introduce ErrorRadar, the first benchmark designed to assess MLLMs' capabilities in such a task. ErrorRadar evaluates two sub-tasks: error step identification and error categorization, providing a comprehensive framework for evaluating MLLMs' complex mathematical reasoning ability. It consists of 2,500 high-quality multimodal K-12 mathematical problems, collected from real-world student interactions in an educational organization, with rigorous annotation and rich metadata such as problem type and error category. Through extensive experiments, we evaluated both open-source and closed-source representative MLLMs, benchmarking their performance against educational expert evaluators. Results indicate significant challenges still remain, as GPT-4o with best performance is still around 10% behind human evaluation. The dataset will be available upon acceptance.
AI-Driven Virtual Teacher for Enhanced Educational Efficiency: Leveraging Large Pretrain Models for Autonomous Error Analysis and Correction
Sep 14, 2024



Students frequently make mistakes while solving mathematical problems, and traditional error correction methods are both time-consuming and labor-intensive. This paper introduces an innovative \textbf{V}irtual \textbf{A}I \textbf{T}eacher system designed to autonomously analyze and correct student \textbf{E}rrors (VATE). Leveraging advanced large language models (LLMs), the system uses student drafts as a primary source for error analysis, which enhances understanding of the student's learning process. It incorporates sophisticated prompt engineering and maintains an error pool to reduce computational overhead. The AI-driven system also features a real-time dialogue component for efficient student interaction. Our approach demonstrates significant advantages over traditional and machine learning-based error correction methods, including reduced educational costs, high scalability, and superior generalizability. The system has been deployed on the Squirrel AI learning platform for elementary mathematics education, where it achieves 78.3\% accuracy in error analysis and shows a marked improvement in student learning efficiency. Satisfaction surveys indicate a strong positive reception, highlighting the system's potential to transform educational practices.
Improve Temporal Awareness of LLMs for Sequential Recommendation
May 05, 2024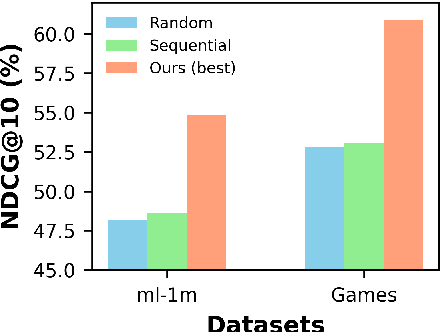
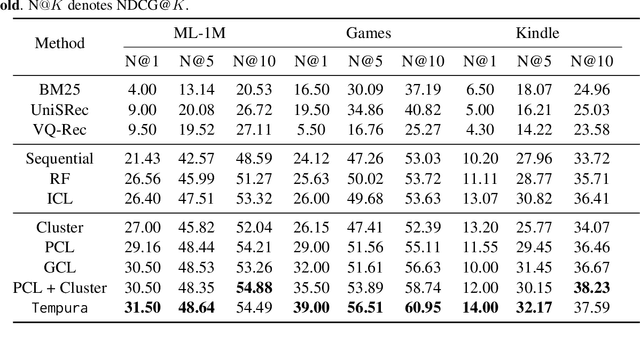
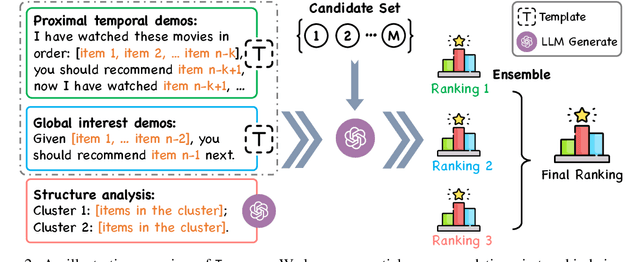
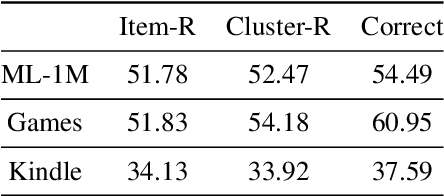
Large language models (LLMs) have demonstrated impressive zero-shot abilities in solving a wide range of general-purpose tasks. However, it is empirically found that LLMs fall short in recognizing and utilizing temporal information, rendering poor performance in tasks that require an understanding of sequential data, such as sequential recommendation. In this paper, we aim to improve temporal awareness of LLMs by designing a principled prompting framework inspired by human cognitive processes. Specifically, we propose three prompting strategies to exploit temporal information within historical interactions for LLM-based sequential recommendation. Besides, we emulate divergent thinking by aggregating LLM ranking results derived from these strategies. Evaluations on MovieLens-1M and Amazon Review datasets indicate that our proposed method significantly enhances the zero-shot capabilities of LLMs in sequential recommendation tasks.
Multi-Objective Intrinsic Reward Learning for Conversational Recommender Systems
Oct 31, 2023



Conversational Recommender Systems (CRS) actively elicit user preferences to generate adaptive recommendations. Mainstream reinforcement learning-based CRS solutions heavily rely on handcrafted reward functions, which may not be aligned with user intent in CRS tasks. Therefore, the design of task-specific rewards is critical to facilitate CRS policy learning, which remains largely under-explored in the literature. In this work, we propose a novel approach to address this challenge by learning intrinsic rewards from interactions with users. Specifically, we formulate intrinsic reward learning as a multi-objective bi-level optimization problem. The inner level optimizes the CRS policy augmented by the learned intrinsic rewards, while the outer level drives the intrinsic rewards to optimize two CRS-specific objectives: maximizing the success rate and minimizing the number of turns to reach a successful recommendation in conversations. To evaluate the effectiveness of our approach, we conduct extensive experiments on three public CRS benchmarks. The results show that our algorithm significantly improves CRS performance by exploiting informative learned intrinsic rewards.
Improving a Named Entity Recognizer Trained on Noisy Data with a Few Clean Instances
Oct 25, 2023



To achieve state-of-the-art performance, one still needs to train NER models on large-scale, high-quality annotated data, an asset that is both costly and time-intensive to accumulate. In contrast, real-world applications often resort to massive low-quality labeled data through non-expert annotators via crowdsourcing and external knowledge bases via distant supervision as a cost-effective alternative. However, these annotation methods result in noisy labels, which in turn lead to a notable decline in performance. Hence, we propose to denoise the noisy NER data with guidance from a small set of clean instances. Along with the main NER model we train a discriminator model and use its outputs to recalibrate the sample weights. The discriminator is capable of detecting both span and category errors with different discriminative prompts. Results on public crowdsourcing and distant supervision datasets show that the proposed method can consistently improve performance with a small guidance set.
Meta-Reinforcement Learning via Exploratory Task Clustering
Feb 15, 2023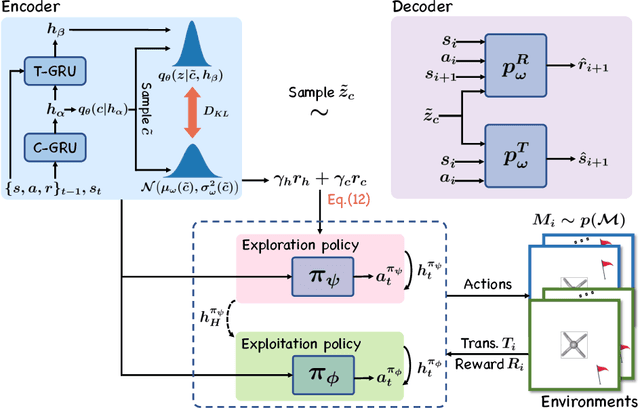
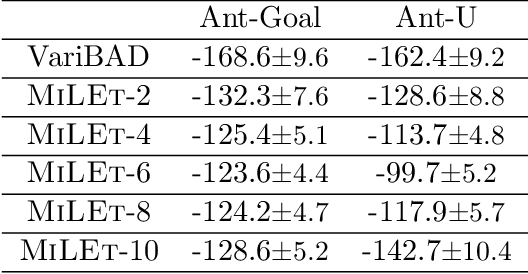
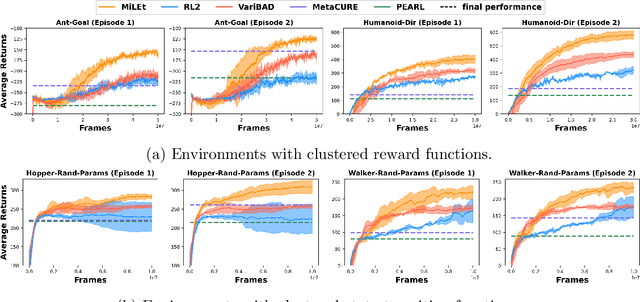
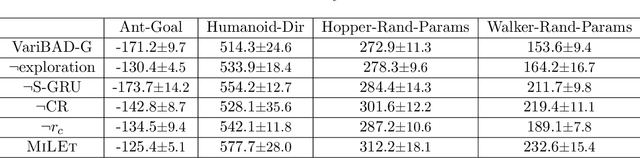
Meta-reinforcement learning (meta-RL) aims to quickly solve new tasks by leveraging knowledge from prior tasks. However, previous studies often assume a single mode homogeneous task distribution, ignoring possible structured heterogeneity among tasks. Leveraging such structures can better facilitate knowledge sharing among related tasks and thus improve sample efficiency. In this paper, we explore the structured heterogeneity among tasks via clustering to improve meta-RL. We develop a dedicated exploratory policy to discover task structures via divide-and-conquer. The knowledge of the identified clusters helps to narrow the search space of task-specific information, leading to more sample efficient policy adaptation. Experiments on various MuJoCo tasks showed the proposed method can unravel cluster structures effectively in both rewards and state dynamics, proving strong advantages against a set of state-of-the-art baselines.