 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Reinforcement Learning via Exploratory Task Clustering
Paper and Code
Feb 15, 2023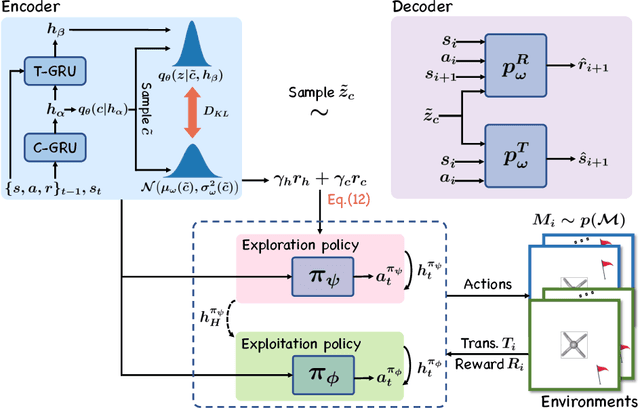
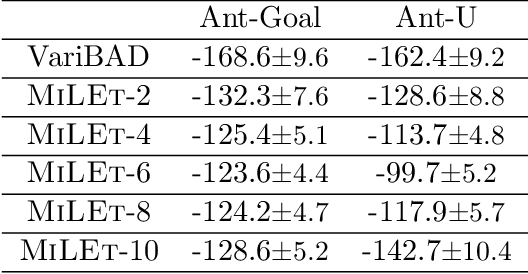
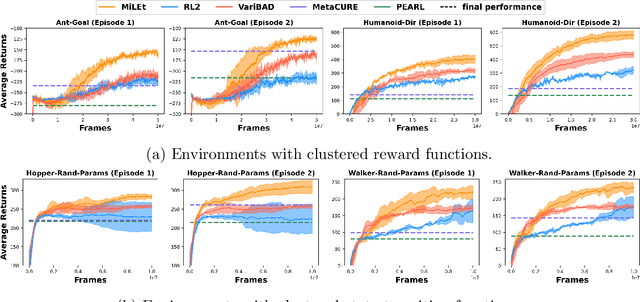
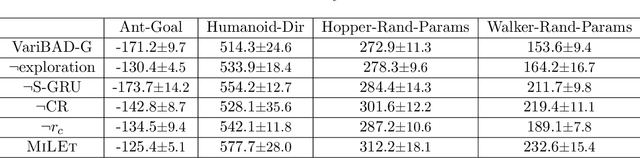
Meta-reinforcement learning (meta-RL) aims to quickly solve new tasks by leveraging knowledge from prior tasks. However, previous studies often assume a single mode homogeneous task distribution, ignoring possible structured heterogeneity among tasks. Leveraging such structures can better facilitate knowledge sharing among related tasks and thus improve sample efficiency. In this paper, we explore the structured heterogeneity among tasks via clustering to improve meta-RL. We develop a dedicated exploratory policy to discover task structures via divide-and-conquer. The knowledge of the identified clusters helps to narrow the search space of task-specific information, leading to more sample efficient policy adaptation. Experiments on various MuJoCo tasks showed the proposed method can unravel cluster structures effectively in both rewards and state dynamics, proving strong advantages against a set of state-of-the-art baselines.