 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience Augmented Policy Optimization for LLM Reasoning
Jun 29, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is a powerful paradigm for improving the reasoning capabilities of large language models (LLMs). However, existing RLVR methods typically rely on on-policy optimization from scratch, resulting in high sampling costs and inefficient utilization of accumulated experience. As model capabilities and policy behaviors evolve during training, recent attempts to reuse experience via fixed reasoning trajectories further suffer from policy mismatch. Motivated by these limitations, we argue that experience in RLVR should not be reused as fixed reasoning trajectories, but instead expressed in a policy-adaptive manner. In this work, we propose Experience-Augmented Policy Optimization (EAPO), which leverages a prior RL-optimized policy as an action-level experience prior and selectively injects experience at critical decision points during rollout. To ensure stable and unbiased learning from experience-augmented rollouts, EAPO further incorporates an adapted importance sampling scheme. Experiments on using Qwen-2.5-math 7b and Qwen-3-8B on five different benchmarks demonstrate that EAPO consistently improves reasoning performance over state-of-the-art RLVR methods.
R^2-Mem: Reflective Experience for Memory Search
May 13, 2026Deep search has recently emerged as a promising paradigm for enabling agents to retrieve fine-grained historical information without heavy memory pre-managed. However, existing deep search agents for memory system repeat past error behaviors because they fail to learn from the prior high- and low-quality search trajectories. To address this limitation, we propose R^2-Mem, a reflective experience framework for memory search systems. In the offline stage, a Rubric-guided Evaluator scores low- and high-quality steps in historical trajectories, and a self-Reflection Learner distills the corresponding abstract experience. During the online inference, the retrieved experience will guide future search actions to avoid repeated mistakes and maintain high-quality behaviors. Extensive experiments demonstrate that R^2-Mem consistently improves both effectiveness and efficiency over strong baselines, improving F1 scores by up to 22.6%, while reducing token consumption by 12.9% and search iterations by 20.2%. These results verify that R^2-Mem provides a RL-free and low-cost solution for self-improving LLM agents.
Beyond Where to Look: Trajectory-Guided Reinforcement Learning for Multimodal RLVR
Mar 27, 2026Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) for multimodal large language models (MLLMs) have mainly focused on improving final answer correctness and strengthening visual grounding. However, a critical bottleneck remains: although models can attend to relevant visual regions, they often fail to effectively incorporate visual evidence into subsequent reasoning, leading to reasoning chains that are weakly grounded in visual facts. To address this issue, we propose Trajectory-Guided Reinforcement Learning (TGRL), which guides the policy model to integrate visual evidence into fine-grained reasoning processes using expert reasoning trajectories from stronger models. We further introduce token-level reweighting and trajectory filtering to ensure stable and effective policy optimization. Extensive experiments on multiple multimodal reasoning benchmarks demonstrate that TGRL consistently improves reasoning performance and effectively bridges the gap between visual perception and logical reasoning.
Bridging Perception and Reasoning: Token Reweighting for RLVR in Multimodal LLMs
Mar 26, 2026Extending Reinforcement Learning with Verifiable Rewards (RLVR) to multimodal large language models (MLLMs) faces a fundamental challenge: their responses inherently interleave perception-related tokens, which ground visual content, with reasoning-related tokens, which construct reasoning chains. These token types instantiate distinct yet interdependent capacities -- visual grounding and symbolic reasoning -- making isolated optimization insufficient. Through token-level empirical analysis, we demonstrate that optimizing either perception- or reasoning-only tokens consistently underperforms full optimization, underscoring their inherent coupling. To address this, we propose a plug-and-play Token-Reweighting (ToR) strategy that explicitly models this interdependence by identifying critical tokens of both types and dynamically reweighting them during RLVR training. Applied on top of existing methods (e.g., GRPO and DAPO), ToR delivers consistent performance gains across multiple multi-modal reasoning benchmarks, achieving state-of-the-art performance with both accurate visual grounding and coherent reasoning.
On the Direction of RLVR Updates for LLM Reasoning: Identification and Exploitation
Mar 23, 2026Reinforcement learning with verifiable rewards (RLVR) has substantially improved the reasoning capabilities of large language models. While existing analyses identify that RLVR-induced changes are sparse, they primarily focus on the \textbf{magnitude} of these updates, largely overlooking their \textbf{direction}. In this work, we argue that the direction of updates is a more critical lens for understanding RLVR's effects, which can be captured by the signed, token-level log probability difference $Δ\log p$ between the base and final RLVR models. Through statistical analysis and token-replacement interventions, we demonstrate that $Δ\log p$ more effectively identifies sparse, yet reasoning-critical updates than magnitude-based metrics (\eg divergence or entropy). Building on this insight, we propose two practical applications: (1) a \textit{test-time extrapolation} method that amplifies the policy along the learned $Δ\log p$ direction to improve reasoning accuracy without further training; (2) a \textit{training-time reweighting} method that focuses learning on low-probability (corresponding to higher $Δ\log p$) tokens, which improves reasoning performance across models and benchmarks. Our work establishes the direction of change as a key principle for analyzing and improving RLVR.
Causal-HalBench: Uncovering LVLMs Object Hallucinations Through Causal Intervention
Nov 13, 2025Large Vision-Language Models (LVLMs) often suffer from object hallucination, making erroneous judgments about the presence of objects in images. We propose this primar- ily stems from spurious correlations arising when models strongly associate highly co-occurring objects during train- ing, leading to hallucinated objects influenced by visual con- text. Current benchmarks mainly focus on hallucination de- tection but lack a formal characterization and quantitative evaluation of spurious correlations in LVLMs. To address this, we introduce causal analysis into the object recognition scenario of LVLMs, establishing a Structural Causal Model (SCM). Utilizing the language of causality, we formally de- fine spurious correlations arising from co-occurrence bias. To quantify the influence induced by these spurious correla- tions, we develop Causal-HalBench, a benchmark specifically constructed with counterfactual samples and integrated with comprehensive causal metrics designed to assess model ro- bustness against spurious correlations. Concurrently, we pro- pose an extensible pipeline for the construction of these coun- terfactual samples, leveraging the capabilities of proprietary LVLMs and Text-to-Image (T2I) models for their genera- tion. Our evaluations on mainstream LVLMs using Causal- HalBench demonstrate these models exhibit susceptibility to spurious correlations, albeit to varying extents.
Quantile Advantage Estimation for Entropy-Safe Reasoning
Sep 26, 2025Reinforcement Learning with Verifiable Rewards (RLVR) strengthens LLM reasoning, but training often oscillates between {entropy collapse} and {entropy explosion}. We trace both hazards to the mean baseline used in value-free RL (e.g., GRPO and DAPO), which improperly penalizes negative-advantage samples under reward outliers. We propose {Quantile Advantage Estimation} (QAE), replacing the mean with a group-wise K-quantile baseline. QAE induces a response-level, two-regime gate: on hard queries (p <= 1 - K) it reinforces rare successes, while on easy queries (p > 1 - K) it targets remaining failures. Under first-order softmax updates, we prove {two-sided entropy safety}, giving lower and upper bounds on one-step entropy change that curb explosion and prevent collapse. Empirically, this minimal modification stabilizes entropy, sparsifies credit assignment (with tuned K, roughly 80% of responses receive zero advantage), and yields sustained pass@1 gains on Qwen3-8B/14B-Base across AIME 2024/2025 and AMC 2023. These results identify {baseline design} -- rather than token-level heuristics -- as the primary mechanism for scaling RLVR.
AdaViP: Aligning Multi-modal LLMs via Adaptive Vision-enhanced Preference Optimization
Apr 22, 2025Preference alignment through Direct Preference Optimization (DPO) has demonstrated significant effectiveness in aligning multimodal large language models (MLLMs) with human preferences. However, existing methods focus primarily on language preferences while neglecting the critical visual context. In this paper, we propose an Adaptive Vision-enhanced Preference optimization (AdaViP) that addresses these limitations through two key innovations: (1) vision-based preference pair construction, which integrates multiple visual foundation models to strategically remove key visual elements from the image, enhancing MLLMs' sensitivity to visual details; and (2) adaptive preference optimization that dynamically balances vision- and language-based preferences for more accurate alignment. Extensive evaluations across different benchmarks demonstrate our effectiveness. Notably, our AdaViP-7B achieves 93.7% and 96.4% reductions in response-level and mentioned-level hallucination respectively on the Object HalBench, significantly outperforming current state-of-the-art methods.
Aligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025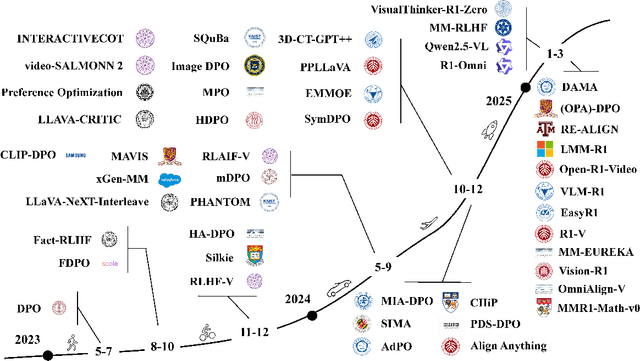
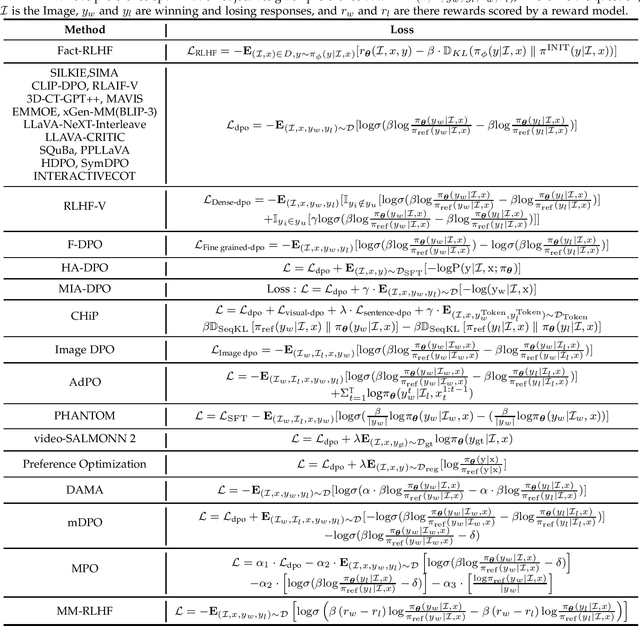
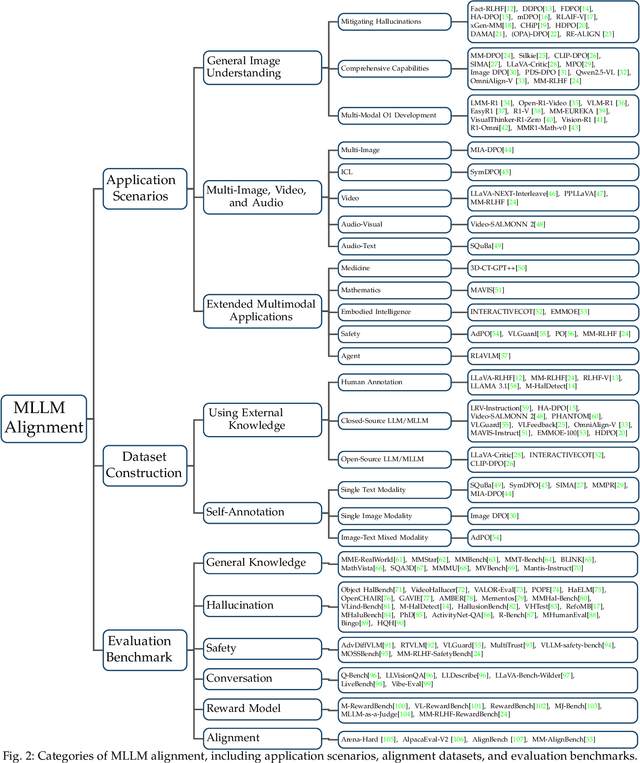
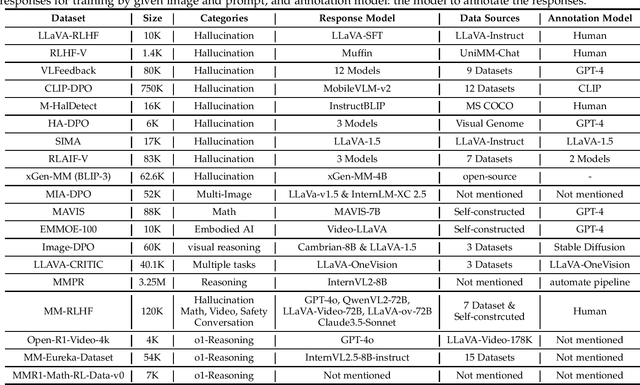
Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
RePO: ReLU-based Preference Optimization
Mar 10, 2025Aligning large language models (LLMs) with human preferences is critical for real-world deployment, yet existing methods like RLHF face computational and stability challenges. While DPO establishes an offline paradigm with single hyperparameter $\beta$, subsequent methods like SimPO reintroduce complexity through dual parameters ($\beta$, $\gamma$). We propose {ReLU-based Preference Optimization (RePO)}, a streamlined algorithm that eliminates $\beta$ via two advances: (1) retaining SimPO's reference-free margins but removing $\beta$ through gradient analysis, and (2) adopting a ReLU-based max-margin loss that naturally filters trivial pairs. Theoretically, RePO is characterized as SimPO's limiting case ($\beta \to \infty$), where the logistic weighting collapses to binary thresholding, forming a convex envelope of the 0-1 loss. Empirical results on AlpacaEval 2 and Arena-Hard show that RePO outperforms DPO and SimPO across multiple base models, requiring only one hyperparameter to tune.