 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Alignment for Vision-Language Model Test-time Adaptation
Jan 13, 2026Vision-language models (VLMs), despite their extraordinary zero-shot capabilities, are vulnerable to distribution shifts. Test-time adaptation (TTA) emerges as a predominant strategy to adapt VLMs to unlabeled test data on the fly. However, existing TTA methods heavily rely on zero-shot predictions as pseudo-labels for self-training, which can be unreliable under distribution shifts and misguide adaptation due to two fundamental limitations. First (Modality Gap), distribution shifts induce gaps between visual and textual modalities, making cross-modal relations inaccurate. Second (Visual Nuisance), visual embeddings encode rich but task-irrelevant noise that often overwhelms task-specific semantics under distribution shifts. To address these limitations, we propose SubTTA, which aligns the semantic subspaces of both modalities to enhance zero-shot predictions to better guide the TTA process. To bridge the modality gap, SubTTA extracts the principal subspaces of both modalities and aligns the visual manifold to the textual semantic anchor by minimizing their chordal distance. To eliminate visual nuisance, SubTTA projects the aligned visual features onto the task-specific textual subspace, which filters out task-irrelevant noise by constraining visual embeddings within the valid semantic span, and standard TTA is further performed on the purified space to refine the decision boundaries. Extensive experiments on various benchmarks and VLM architectures demonstrate the effectiveness of SubTTA, yielding an average improvement of 2.24% over state-of-the-art TTA methods.
Towards Knowledge Checking in Retrieval-augmented Generation: A Representation Perspective
Nov 21, 2024Retrieval-Augmented Generation (RAG) systems have shown promise in enhancing the performance of Large Language Models (LLMs). However, these systems face challenges in effectively integrating external knowledge with the LLM's internal knowledge, often leading to issues with misleading or unhelpful information. This work aims to provide a systematic study on knowledge checking in RAG systems. We conduct a comprehensive analysis of LLM representation behaviors and demonstrate the significance of using representations in knowledge checking. Motivated by the findings, we further develop representation-based classifiers for knowledge filtering. We show substantial improvements in RAG performance, even when dealing with noisy knowledge databases. Our study provides new insights into leveraging LLM representations for enhancing the reliability and effectiveness of RAG systems.
Amazon-M2: A Multilingual Multi-locale Shopping Session Dataset for Recommendation and Text Generation
Jul 19, 2023
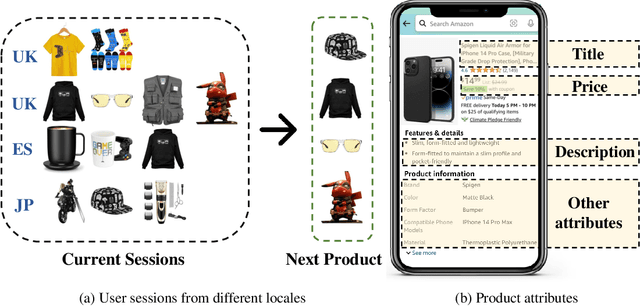
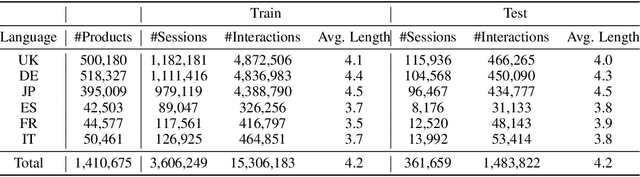
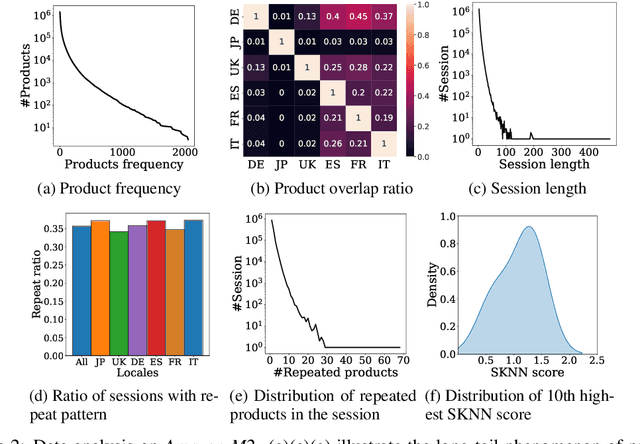
Modeling customer shopping intentions is a crucial task for e-commerce, as it directly impacts user experience and engagement. Thus, accurately understanding customer preferences is essential for providing personalized recommendations. Session-based recommendation, which utilizes customer session data to predict their next interaction, has become increasingly popular. However, existing session datasets have limitations in terms of item attributes, user diversity, and dataset scale. As a result, they cannot comprehensively capture the spectrum of user behaviors and preferences. To bridge this gap, we present the Amazon Multilingual Multi-locale Shopping Session Dataset, namely Amazon-M2. It is the first multilingual dataset consisting of millions of user sessions from six different locales, where the major languages of products are English, German, Japanese, French, Italian, and Spanish. Remarkably, the dataset can help us enhance personalization and understanding of user preferences, which can benefit various existing tasks as well as enable new tasks. To test the potential of the dataset, we introduce three tasks in this work: (1) next-product recommendation, (2) next-product recommendation with domain shifts, and (3) next-product title generation. With the above tasks, we benchmark a range of algorithms on our proposed dataset, drawing new insights for further research and practice. In addition, based on the proposed dataset and tasks, we hosted a competition in the KDD CUP 2023 and have attracted thousands of users and submissions. The winning solutions and the associated workshop can be accessed at our website https://kddcup23.github.io/.