 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttn-GS: Attention-Guided Context Compression for Efficient Personalized LLMs
Feb 08, 2026Personalizing large language models (LLMs) to individual users requires incorporating extensive interaction histories and profiles, but input token constraints make this impractical due to high inference latency and API costs. Existing approaches rely on heuristic methods such as selecting recent interactions or prompting summarization models to compress user profiles. However, these methods treat context as a monolithic whole and fail to consider how LLMs internally process and prioritize different profile components. We investigate whether LLMs' attention patterns can effectively identify important personalization signals for intelligent context compression. Through preliminary studies on representative personalization tasks, we discover that (a) LLMs' attention patterns naturally reveal important signals, and (b) fine-tuning enhances LLMs' ability to distinguish between relevant and irrelevant information. Based on these insights, we propose Attn-GS, an attention-guided context compression framework that leverages attention feedback from a marking model to mark important personalization sentences, then guides a compression model to generate task-relevant, high-quality compressed user contexts. Extensive experiments demonstrate that Attn-GS significantly outperforms various baselines across different tasks, token limits, and settings, achieving performance close to using full context while reducing token usage by 50 times.
Beyond Text: Unveiling Privacy Vulnerabilities in Multi-modal Retrieval-Augmented Generation
May 20, 2025Multimodal Retrieval-Augmented Generation (MRAG) systems enhance LMMs by integrating external multimodal databases, but introduce unexplored privacy vulnerabilities. While text-based RAG privacy risks have been studied, multimodal data presents unique challenges. We provide the first systematic analysis of MRAG privacy vulnerabilities across vision-language and speech-language modalities. Using a novel compositional structured prompt attack in a black-box setting, we demonstrate how attackers can extract private information by manipulating queries. Our experiments reveal that LMMs can both directly generate outputs resembling retrieved content and produce descriptions that indirectly expose sensitive information, highlighting the urgent need for robust privacy-preserving MRAG techniques.
Towards Context-Robust LLMs: A Gated Representation Fine-tuning Approach
Feb 22, 2025Large Language Models (LLMs) enhanced with external contexts, such as through retrieval-augmented generation (RAG), often face challenges in handling imperfect evidence. They tend to over-rely on external knowledge, making them vulnerable to misleading and unhelpful contexts. To address this, we propose the concept of context-robust LLMs, which can effectively balance internal knowledge with external context, similar to human cognitive processes. Specifically, context-robust LLMs should rely on external context only when lacking internal knowledge, identify contradictions between internal and external knowledge, and disregard unhelpful contexts. To achieve this goal, we introduce Grft, a lightweight and plug-and-play gated representation fine-tuning approach. Grft consists of two key components: a gating mechanism to detect and filter problematic inputs, and low-rank representation adapters to adjust hidden representations. By training a lightweight intervention function with only 0.0004\% of model size on fewer than 200 examples, Grft can effectively adapt LLMs towards context-robust behaviors.
Towards Knowledge Checking in Retrieval-augmented Generation: A Representation Perspective
Nov 21, 2024



Retrieval-Augmented Generation (RAG) systems have shown promise in enhancing the performance of Large Language Models (LLMs). However, these systems face challenges in effectively integrating external knowledge with the LLM's internal knowledge, often leading to issues with misleading or unhelpful information. This work aims to provide a systematic study on knowledge checking in RAG systems. We conduct a comprehensive analysis of LLM representation behaviors and demonstrate the significance of using representations in knowledge checking. Motivated by the findings, we further develop representation-based classifiers for knowledge filtering. We show substantial improvements in RAG performance, even when dealing with noisy knowledge databases. Our study provides new insights into leveraging LLM representations for enhancing the reliability and effectiveness of RAG systems.
AmazonQAC: A Large-Scale, Naturalistic Query Autocomplete Dataset
Oct 22, 2024Query Autocomplete (QAC) is a critical feature in modern search engines, facilitating user interaction by predicting search queries based on input prefixes. Despite its widespread adoption, the absence of large-scale, realistic datasets has hindered advancements in QAC system development. This paper addresses this gap by introducing AmazonQAC, a new QAC dataset sourced from Amazon Search logs, comprising 395M samples. The dataset includes actual sequences of user-typed prefixes leading to final search terms, as well as session IDs and timestamps that support modeling the context-dependent aspects of QAC. We assess Prefix Trees, semantic retrieval, and Large Language Models (LLMs) with and without finetuning. We find that finetuned LLMs perform best, particularly when incorporating contextual information. However, even our best system achieves only half of what we calculate is theoretically possible on our test data, which implies QAC is a challenging problem that is far from solved with existing systems. This contribution aims to stimulate further research on QAC systems to better serve user needs in diverse environments. We open-source this data on Hugging Face at https://huggingface.co/datasets/amazon/AmazonQAC.
Dissipative Gradient Descent Ascent Method: A Control Theory Inspired Algorithm for Min-max Optimization
Mar 14, 2024Gradient Descent Ascent (GDA) methods for min-max optimization problems typically produce oscillatory behavior that can lead to instability, e.g., in bilinear settings. To address this problem, we introduce a dissipation term into the GDA updates to dampen these oscillations. The proposed Dissipative GDA (DGDA) method can be seen as performing standard GDA on a state-augmented and regularized saddle function that does not strictly introduce additional convexity/concavity. We theoretically show the linear convergence of DGDA in the bilinear and strongly convex-strongly concave settings and assess its performance by comparing DGDA with other methods such as GDA, Extra-Gradient (EG), and Optimistic GDA. Our findings demonstrate that DGDA surpasses these methods, achieving superior convergence rates. We support our claims with two numerical examples that showcase DGDA's effectiveness in solving saddle point problems.
Constrained Reinforcement Learning via Dissipative Saddle Flow Dynamics
Dec 03, 2022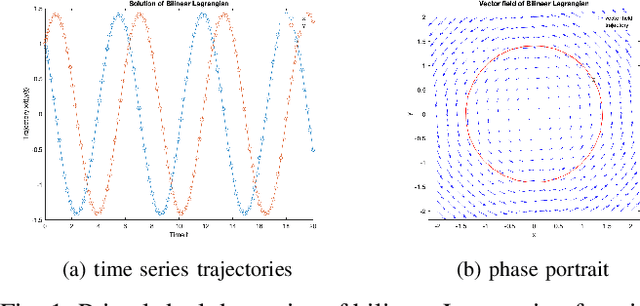
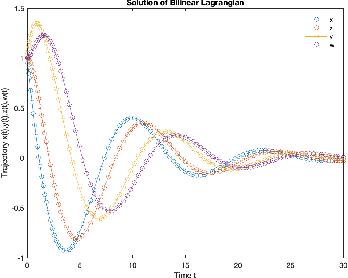
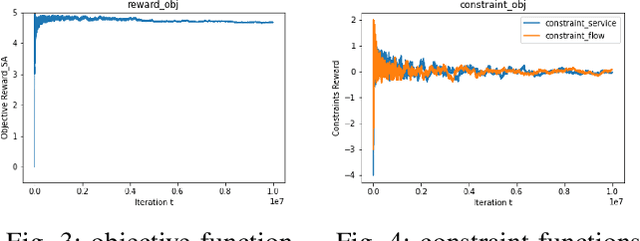
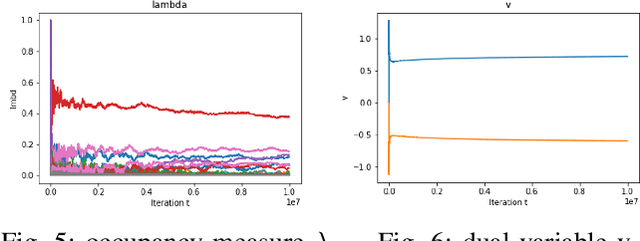
In constrained reinforcement learning (C-RL), an agent seeks to learn from the environment a policy that maximizes the expected cumulative reward while satisfying minimum requirements in secondary cumulative reward constraints. Several algorithms rooted in sampled-based primal-dual methods have been recently proposed to solve this problem in policy space. However, such methods are based on stochastic gradient descent ascent algorithms whose trajectories are connected to the optimal policy only after a mixing output stage that depends on the algorithm's history. As a result, there is a mismatch between the behavioral policy and the optimal one. In this work, we propose a novel algorithm for constrained RL that does not suffer from these limitations. Leveraging recent results on regularized saddle-flow dynamics, we develop a novel stochastic gradient descent-ascent algorithm whose trajectories converge to the optimal policy almost surely.