 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Transfer Reinforcement Learning: Provable Sample Efficiency from Shifted-Dynamics Data
Nov 06, 2024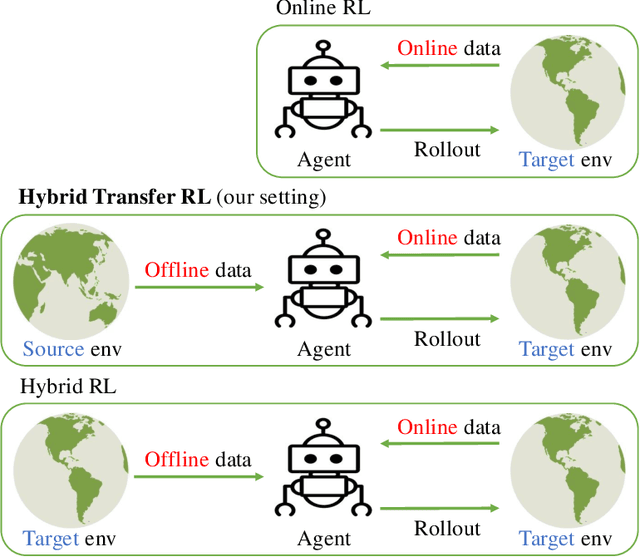
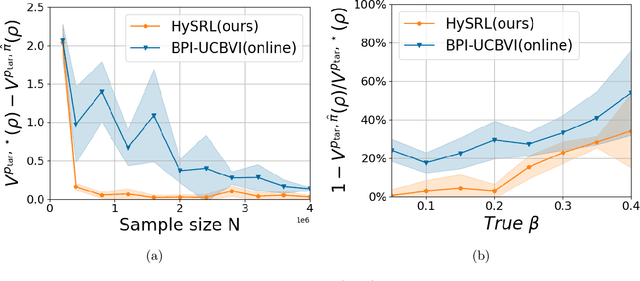
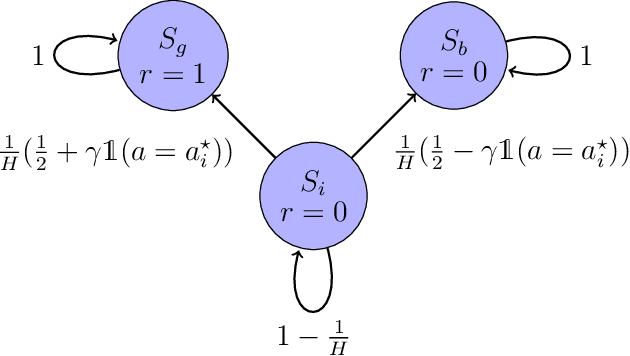
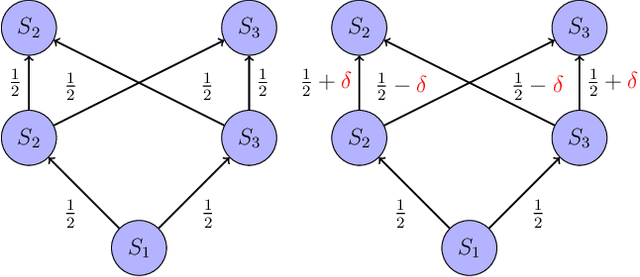
Online Reinforcement learning (RL) typically requires high-stakes online interaction data to learn a policy for a target task. This prompts interest in leveraging historical data to improve sample efficiency. The historical data may come from outdated or related source environments with different dynamics. It remains unclear how to effectively use such data in the target task to provably enhance learning and sample efficiency. To address this, we propose a hybrid transfer RL (HTRL) setting, where an agent learns in a target environment while accessing offline data from a source environment with shifted dynamics. We show that -- without information on the dynamics shift -- general shifted-dynamics data, even with subtle shifts, does not reduce sample complexity in the target environment. However, with prior information on the degree of the dynamics shift, we design HySRL, a transfer algorithm that achieves problem-dependent sample complexity and outperforms pure online RL. Finally, our experimental results demonstrate that HySRL surpasses state-of-the-art online RL baseline.
C-MORL: Multi-Objective Reinforcement Learning through Efficient Discovery of Pareto Front
Oct 03, 2024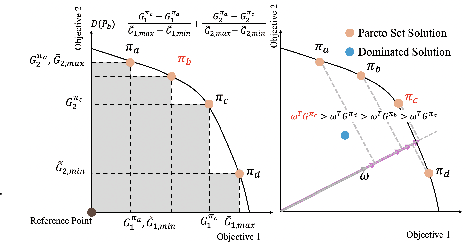
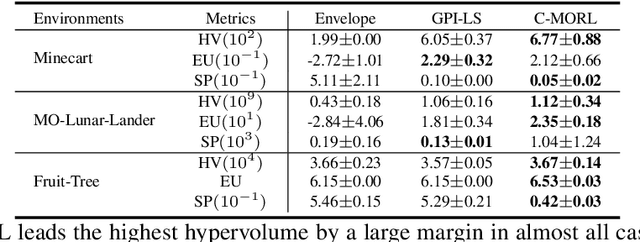
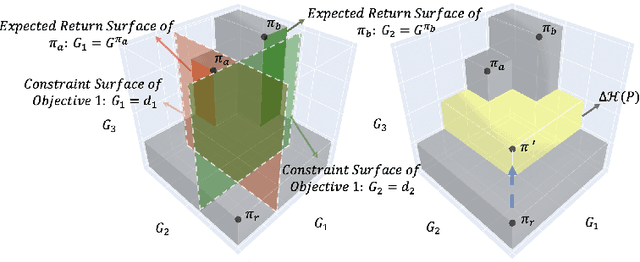
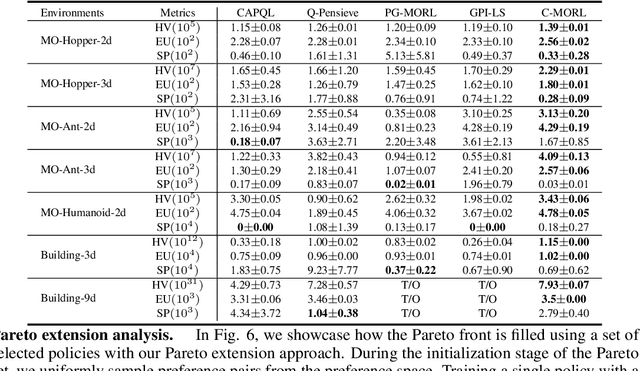
Multi-objective reinforcement learning (MORL) excels at handling rapidly changing preferences in tasks that involve multiple criteria, even for unseen preferences. However, previous dominating MORL methods typically generate a fixed policy set or preference-conditioned policy through multiple training iterations exclusively for sampled preference vectors, and cannot ensure the efficient discovery of the Pareto front. Furthermore, integrating preferences into the input of policy or value functions presents scalability challenges, in particular as the dimension of the state and preference space grow, which can complicate the learning process and hinder the algorithm's performance on more complex tasks. To address these issues, we propose a two-stage Pareto front discovery algorithm called Constrained MORL (C-MORL), which serves as a seamless bridge between constrained policy optimization and MORL. Concretely, a set of policies is trained in parallel in the initialization stage, with each optimized towards its individual preference over the multiple objectives. Then, to fill the remaining vacancies in the Pareto front, the constrained optimization steps are employed to maximize one objective while constraining the other objectives to exceed a predefined threshold. Empirically, compared to recent advancements in MORL methods, our algorithm achieves more consistent and superior performances in terms of hypervolume, expected utility, and sparsity on both discrete and continuous control tasks, especially with numerous objectives (up to nine objectives in our experiments).
Dissipative Gradient Descent Ascent Method: A Control Theory Inspired Algorithm for Min-max Optimization
Mar 14, 2024Gradient Descent Ascent (GDA) methods for min-max optimization problems typically produce oscillatory behavior that can lead to instability, e.g., in bilinear settings. To address this problem, we introduce a dissipation term into the GDA updates to dampen these oscillations. The proposed Dissipative GDA (DGDA) method can be seen as performing standard GDA on a state-augmented and regularized saddle function that does not strictly introduce additional convexity/concavity. We theoretically show the linear convergence of DGDA in the bilinear and strongly convex-strongly concave settings and assess its performance by comparing DGDA with other methods such as GDA, Extra-Gradient (EG), and Optimistic GDA. Our findings demonstrate that DGDA surpasses these methods, achieving superior convergence rates. We support our claims with two numerical examples that showcase DGDA's effectiveness in solving saddle point problems.
Constrained Reinforcement Learning via Dissipative Saddle Flow Dynamics
Dec 03, 2022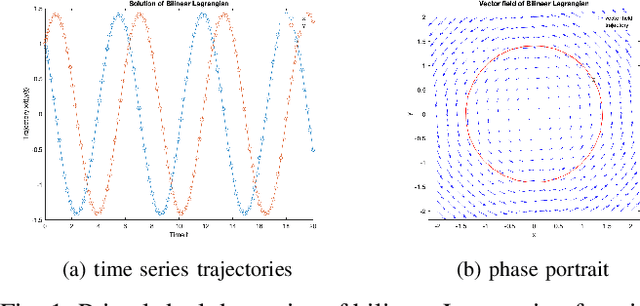
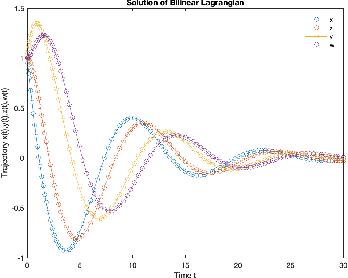
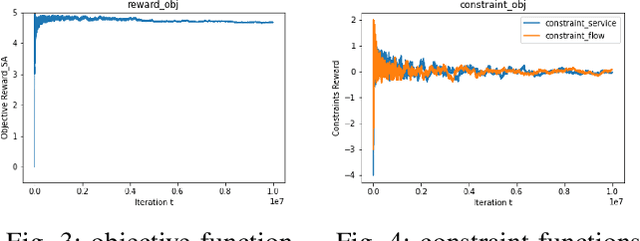
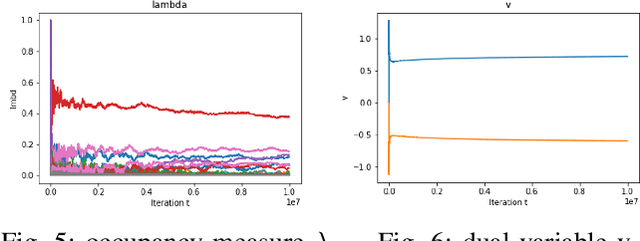
In constrained reinforcement learning (C-RL), an agent seeks to learn from the environment a policy that maximizes the expected cumulative reward while satisfying minimum requirements in secondary cumulative reward constraints. Several algorithms rooted in sampled-based primal-dual methods have been recently proposed to solve this problem in policy space. However, such methods are based on stochastic gradient descent ascent algorithms whose trajectories are connected to the optimal policy only after a mixing output stage that depends on the algorithm's history. As a result, there is a mismatch between the behavioral policy and the optimal one. In this work, we propose a novel algorithm for constrained RL that does not suffer from these limitations. Leveraging recent results on regularized saddle-flow dynamics, we develop a novel stochastic gradient descent-ascent algorithm whose trajectories converge to the optimal policy almost surely.