 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Transfer Reinforcement Learning: Provable Sample Efficiency from Shifted-Dynamics Data
Paper and Code
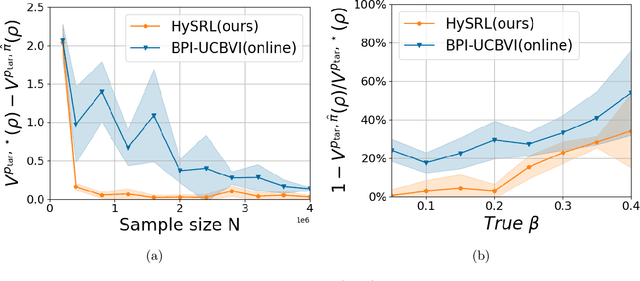
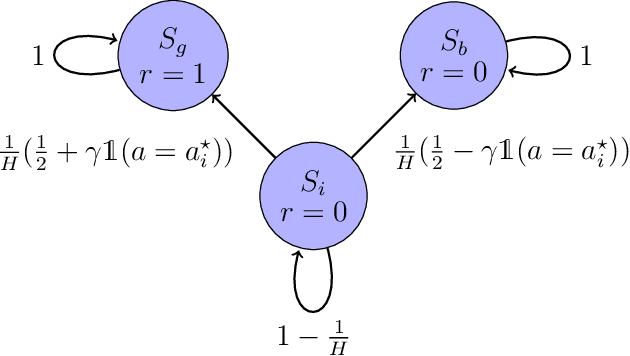
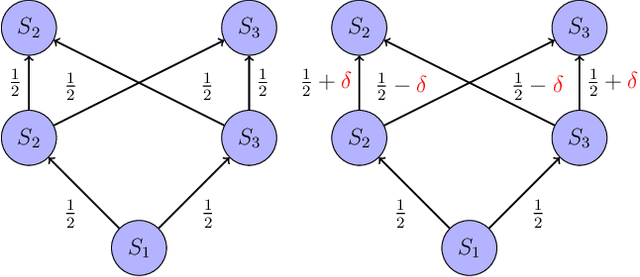
Online Reinforcement learning (RL) typically requires high-stakes online interaction data to learn a policy for a target task. This prompts interest in leveraging historical data to improve sample efficiency. The historical data may come from outdated or related source environments with different dynamics. It remains unclear how to effectively use such data in the target task to provably enhance learning and sample efficiency. To address this, we propose a hybrid transfer RL (HTRL) setting, where an agent learns in a target environment while accessing offline data from a source environment with shifted dynamics. We show that -- without information on the dynamics shift -- general shifted-dynamics data, even with subtle shifts, does not reduce sample complexity in the target environment. However, with prior information on the degree of the dynamics shift, we design HySRL, a transfer algorithm that achieves problem-dependent sample complexity and outperforms pure online RL. Finally, our experimental results demonstrate that HySRL surpasses state-of-the-art online RL baseline.