 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sharpness-Aware Minimization with a Polyak-type Step size: A Theory-Grounded Scheduler
Jun 01, 2026Sharpness-Aware Minimization (SAM) has established itself as a powerful and widely adopted optimizer for training machine learning models. By explicitly minimizing the sharpness of the loss landscape, SAM often improves generalization while delivering strong empirical performance. However, SAM and its variants, like most training algorithms, are sensitive to the choice of learning rate, which is typically selected through extensive hyperparameter tuning or predefined schedulers. In this work, motivated by recent advances on the effectiveness of stochastic Polyak step sizes for Stochastic Gradient Descent (SGD), we derive Polyak schedulers tailored to SAM-style updates, yielding novel adaptive algorithms in both deterministic and stochastic settings. In the smooth setting, we prove linear convergence for strongly convex objectives and an $\mathcal{O}(1/T)$ convergence rate for convex objectives in the deterministic case. In the stochastic setting, we establish analogous convergence guarantees up to a neighborhood of the optimum. Numerical experiments demonstrate that the proposed Polyak schedulers achieve performance comparable to or better than carefully tuned SAM baselines, while substantially reducing the need for learning-rate tuning.
Certified Robustness from Approximate Gaussian Mixture Structures in Pretrained Latent Spaces
May 25, 2026Deep learning models are vulnerable to adversarial perturbations, raising important concerns for safety-critical deployment. Empirical defenses can achieve strong robustness in practice, but lack formal guarantees, motivating the need for certifiably robust classifiers. While certified methods provide formal guarantees, they often yield overly conservative bounds due to their inability to exploit structure in complex data distributions. In this work, we propose a framework for designing certifiably robust classifiers that leverages latent structure in data representations. We first analyze the Gaussian mixture setting, deriving necessary and sufficient conditions for the existence of robust classifiers and constructing a classifier with a closed-form robustness certificate and generalization guarantees. Our main contribution is to show that exact structure is not required: we prove that if a pretrained encoder maps inputs to a latent distribution that is $\varepsilon$-close (in KL divergence) to a Gaussian mixture, then certified accuracy degrades gracefully, with an explicit bound relating robustness under the true and approximate distributions. This result enables the direct use of pretrained models without requiring exact distributional assumptions. Empirically, our method achieves state-of-the-art or competitive certified accuracy on CIFAR-10 and ImageNet, while maintaining strong clean performance and low computational overhead. Overall, our work establishes approximate latent structure as a practical and principled route to certifiable robustness.
Extragradient Method for $(L_0, L_1)$-Lipschitz Root-finding Problems
Oct 25, 2025Introduced by Korpelevich in 1976, the extragradient method (EG) has become a cornerstone technique for solving min-max optimization, root-finding problems, and variational inequalities (VIs). Despite its longstanding presence and significant attention within the optimization community, most works focusing on understanding its convergence guarantees assume the strong L-Lipschitz condition. In this work, building on the proposed assumptions by Zhang et al. [2024b] for minimization and Vankov et al.[2024] for VIs, we focus on the more relaxed $\alpha$-symmetric $(L_0, L_1)$-Lipschitz condition. This condition generalizes the standard Lipschitz assumption by allowing the Lipschitz constant to scale with the operator norm, providing a more refined characterization of problem structures in modern machine learning. Under the $\alpha$-symmetric $(L_0, L_1)$-Lipschitz condition, we propose a novel step size strategy for EG to solve root-finding problems and establish sublinear convergence rates for monotone operators and linear convergence rates for strongly monotone operators. Additionally, we prove local convergence guarantees for weak Minty operators. We supplement our analysis with experiments validating our theory and demonstrating the effectiveness and robustness of the proposed step sizes for EG.
Analysis of an Idealized Stochastic Polyak Method and its Application to Black-Box Model Distillation
Apr 02, 2025
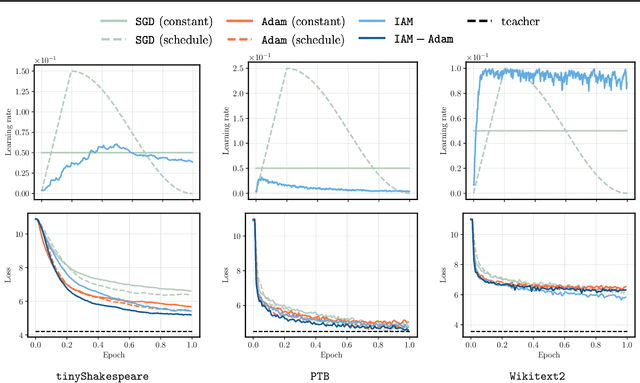

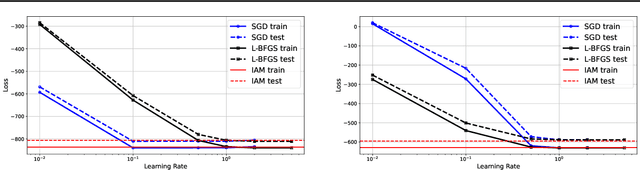
We provide a general convergence theorem of an idealized stochastic Polyak step size called SPS$^*$. Besides convexity, we only assume a local expected gradient bound, that includes locally smooth and locally Lipschitz losses as special cases. We refer to SPS$^*$ as idealized because it requires access to the loss for every training batch evaluated at a solution. It is also ideal, in that it achieves the optimal lower bound for globally Lipschitz function, and is the first Polyak step size to have an $O(1/\sqrt{t})$ anytime convergence in the smooth setting. We show how to combine SPS$^*$ with momentum to achieve the same favorable rates for the last iterate. We conclude with several experiments to validate our theory, and a more practical setting showing how we can distill a teacher GPT-2 model into a smaller student model without any hyperparameter tuning.
Sharpness-Aware Minimization: General Analysis and Improved Rates
Mar 04, 2025



Sharpness-Aware Minimization (SAM) has emerged as a powerful method for improving generalization in machine learning models by minimizing the sharpness of the loss landscape. However, despite its success, several important questions regarding the convergence properties of SAM in non-convex settings are still open, including the benefits of using normalization in the update rule, the dependence of the analysis on the restrictive bounded variance assumption, and the convergence guarantees under different sampling strategies. To address these questions, in this paper, we provide a unified analysis of SAM and its unnormalized variant (USAM) under one single flexible update rule (Unified SAM), and we present convergence results of the new algorithm under a relaxed and more natural assumption on the stochastic noise. Our analysis provides convergence guarantees for SAM under different step size selections for non-convex problems and functions that satisfy the Polyak-Lojasiewicz (PL) condition (a non-convex generalization of strongly convex functions). The proposed theory holds under the arbitrary sampling paradigm, which includes importance sampling as special case, allowing us to analyze variants of SAM that were never explicitly considered in the literature. Experiments validate the theoretical findings and further demonstrate the practical effectiveness of Unified SAM in training deep neural networks for image classification tasks.
Multiplayer Federated Learning: Reaching Equilibrium with Less Communication
Jan 14, 2025Traditional Federated Learning (FL) approaches assume collaborative clients with aligned objectives working towards a shared global model. However, in many real-world scenarios, clients act as rational players with individual objectives and strategic behaviors, a concept that existing FL frameworks are not equipped to adequately address. To bridge this gap, we introduce Multiplayer Federated Learning (MpFL), a novel framework that models the clients in the FL environment as players in a game-theoretic context, aiming to reach an equilibrium. In this scenario, each player tries to optimize their own utility function, which may not align with the collective goal. Within MpFL, we propose Per-Player Local Stochastic Gradient Descent (PEARL-SGD), an algorithm in which each player/client performs local updates independently and periodically communicates with other players. We theoretically analyze PEARL-SGD and prove that it reaches a neighborhood of equilibrium with less communication in the stochastic setup compared to its non-local counterpart. Finally, we verify our theoretical findings through numerical experiments.
Stochastic Polyak Step-sizes and Momentum: Convergence Guarantees and Practical Performance
Jun 06, 2024
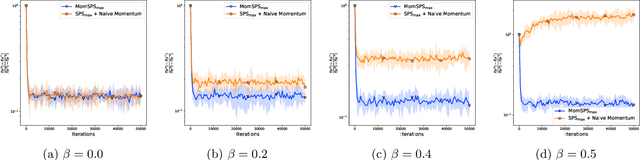
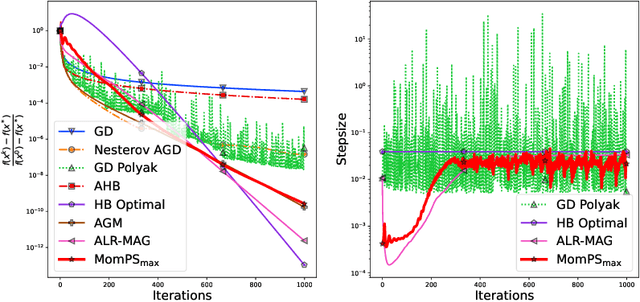

Stochastic gradient descent with momentum, also known as Stochastic Heavy Ball method (SHB), is one of the most popular algorithms for solving large-scale stochastic optimization problems in various machine learning tasks. In practical scenarios, tuning the step-size and momentum parameters of the method is a prohibitively expensive and time-consuming process. In this work, inspired by the recent advantages of stochastic Polyak step-size in the performance of stochastic gradient descent (SGD), we propose and explore new Polyak-type variants suitable for the update rule of the SHB method. In particular, using the Iterate Moving Average (IMA) viewpoint of SHB, we propose and analyze three novel step-size selections: MomSPS$_{\max}$, MomDecSPS, and MomAdaSPS. For MomSPS$_{\max}$, we provide convergence guarantees for SHB to a neighborhood of the solution for convex and smooth problems (without assuming interpolation). If interpolation is also satisfied, then using MomSPS$_{\max}$, SHB converges to the true solution at a fast rate matching the deterministic HB. The other two variants, MomDecSPS and MomAdaSPS, are the first adaptive step-sizes for SHB that guarantee convergence to the exact minimizer without prior knowledge of the problem parameters and without assuming interpolation. The convergence analysis of SHB is tight and obtains the convergence guarantees of SGD with stochastic Polyak step-sizes as a special case. We supplement our analysis with experiments that validate the theory and demonstrate the effectiveness and robustness of the new algorithms.
Dissipative Gradient Descent Ascent Method: A Control Theory Inspired Algorithm for Min-max Optimization
Mar 14, 2024Gradient Descent Ascent (GDA) methods for min-max optimization problems typically produce oscillatory behavior that can lead to instability, e.g., in bilinear settings. To address this problem, we introduce a dissipation term into the GDA updates to dampen these oscillations. The proposed Dissipative GDA (DGDA) method can be seen as performing standard GDA on a state-augmented and regularized saddle function that does not strictly introduce additional convexity/concavity. We theoretically show the linear convergence of DGDA in the bilinear and strongly convex-strongly concave settings and assess its performance by comparing DGDA with other methods such as GDA, Extra-Gradient (EG), and Optimistic GDA. Our findings demonstrate that DGDA surpasses these methods, achieving superior convergence rates. We support our claims with two numerical examples that showcase DGDA's effectiveness in solving saddle point problems.
Stochastic Extragradient with Random Reshuffling: Improved Convergence for Variational Inequalities
Mar 11, 2024



The Stochastic Extragradient (SEG) method is one of the most popular algorithms for solving finite-sum min-max optimization and variational inequality problems (VIPs) appearing in various machine learning tasks. However, existing convergence analyses of SEG focus on its with-replacement variants, while practical implementations of the method randomly reshuffle components and sequentially use them. Unlike the well-studied with-replacement variants, SEG with Random Reshuffling (SEG-RR) lacks established theoretical guarantees. In this work, we provide a convergence analysis of SEG-RR for three classes of VIPs: (i) strongly monotone, (ii) affine, and (iii) monotone. We derive conditions under which SEG-RR achieves a faster convergence rate than the uniform with-replacement sampling SEG. In the monotone setting, our analysis of SEG-RR guarantees convergence to an arbitrary accuracy without large batch sizes, a strong requirement needed in the classical with-replacement SEG. As a byproduct of our results, we provide convergence guarantees for Shuffle Once SEG (shuffles the data only at the beginning of the algorithm) and the Incremental Extragradient (does not shuffle the data). We supplement our analysis with experiments validating empirically the superior performance of SEG-RR over the classical with-replacement sampling SEG.
Remove that Square Root: A New Efficient Scale-Invariant Version of AdaGrad
Mar 05, 2024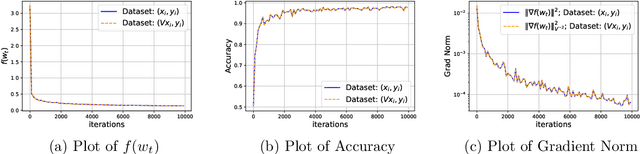
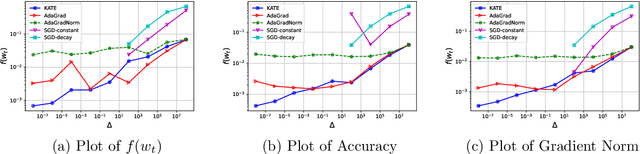
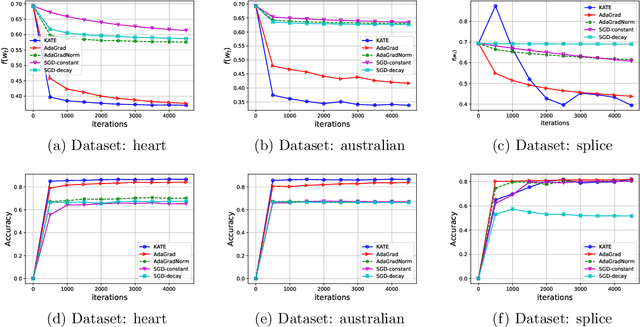
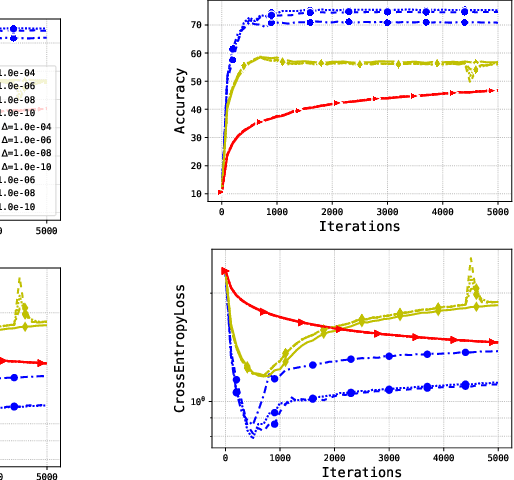
Adaptive methods are extremely popular in machine learning as they make learning rate tuning less expensive. This paper introduces a novel optimization algorithm named KATE, which presents a scale-invariant adaptation of the well-known AdaGrad algorithm. We prove the scale-invariance of KATE for the case of Generalized Linear Models. Moreover, for general smooth non-convex problems, we establish a convergence rate of $O \left(\frac{\log T}{\sqrt{T}} \right)$ for KATE, matching the best-known ones for AdaGrad and Adam. We also compare KATE to other state-of-the-art adaptive algorithms Adam and AdaGrad in numerical experiments with different problems, including complex machine learning tasks like image classification and text classification on real data. The results indicate that KATE consistently outperforms AdaGrad and matches/surpasses the performance of Adam in all considered scenarios.