 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Tight Bounds for SGD without Variance Assumption: A Computer-Aided Lyapunov Analysis
May 23, 2025The analysis of Stochastic Gradient Descent (SGD) often relies on making some assumption on the variance of the stochastic gradients, which is usually not satisfied or difficult to verify in practice. This paper contributes to a recent line of works which attempt to provide guarantees without making any variance assumption, leveraging only the (strong) convexity and smoothness of the loss functions. In this context, we prove new theoretical bounds derived from the monotonicity of a simple Lyapunov energy, improving the current state-of-the-art and extending their validity to larger step-sizes. Our theoretical analysis is backed by a Performance Estimation Problem analysis, which allows us to claim that, empirically, the bias term in our bounds is tight within our framework.
Analysis of an Idealized Stochastic Polyak Method and its Application to Black-Box Model Distillation
Apr 02, 2025
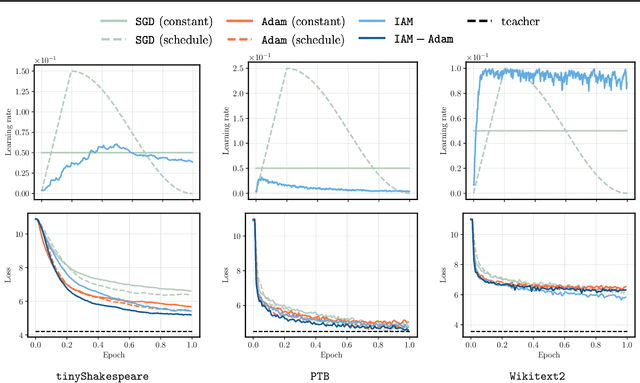

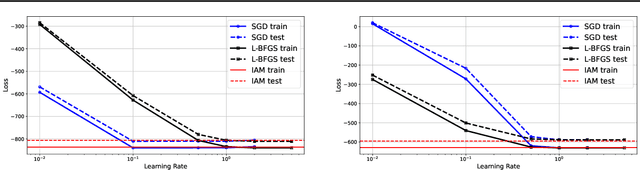
We provide a general convergence theorem of an idealized stochastic Polyak step size called SPS$^*$. Besides convexity, we only assume a local expected gradient bound, that includes locally smooth and locally Lipschitz losses as special cases. We refer to SPS$^*$ as idealized because it requires access to the loss for every training batch evaluated at a solution. It is also ideal, in that it achieves the optimal lower bound for globally Lipschitz function, and is the first Polyak step size to have an $O(1/\sqrt{t})$ anytime convergence in the smooth setting. We show how to combine SPS$^*$ with momentum to achieve the same favorable rates for the last iterate. We conclude with several experiments to validate our theory, and a more practical setting showing how we can distill a teacher GPT-2 model into a smaller student model without any hyperparameter tuning.
Multivariate Online Linear Regression for Hierarchical Forecasting
Feb 22, 2024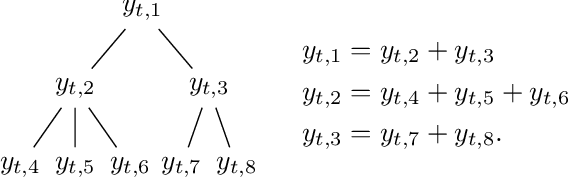

In this paper, we consider a deterministic online linear regression model where we allow the responses to be multivariate. To address this problem, we introduce MultiVAW, a method that extends the well-known Vovk-Azoury-Warmuth algorithm to the multivariate setting, and show that it also enjoys logarithmic regret in time. We apply our results to the online hierarchical forecasting problem and recover an algorithm from this literature as a special case, allowing us to relax the hypotheses usually made for its analysis.
SGD with Clipping is Secretly Estimating the Median Gradient
Feb 20, 2024



There are several applications of stochastic optimization where one can benefit from a robust estimate of the gradient. For example, domains such as distributed learning with corrupted nodes, the presence of large outliers in the training data, learning under privacy constraints, or even heavy-tailed noise due to the dynamics of the algorithm itself. Here we study SGD with robust gradient estimators based on estimating the median. We first consider computing the median gradient across samples, and show that the resulting method can converge even under heavy-tailed, state-dependent noise. We then derive iterative methods based on the stochastic proximal point method for computing the geometric median and generalizations thereof. Finally we propose an algorithm estimating the median gradient across iterations, and find that several well known methods - in particular different forms of clipping - are particular cases of this framework.
Function Value Learning: Adaptive Learning Rates Based on the Polyak Stepsize and Function Splitting in ERM
Jul 26, 2023

Here we develop variants of SGD (stochastic gradient descent) with an adaptive step size that make use of the sampled loss values. In particular, we focus on solving a finite sum-of-terms problem, also known as empirical risk minimization. We first detail an idealized adaptive method called $\texttt{SPS}_+$ that makes use of the sampled loss values and assumes knowledge of the sampled loss at optimality. This $\texttt{SPS}_+$ is a minor modification of the SPS (Stochastic Polyak Stepsize) method, where the step size is enforced to be positive. We then show that $\texttt{SPS}_+$ achieves the best known rates of convergence for SGD in the Lipschitz non-smooth. We then move onto to develop $\texttt{FUVAL}$, a variant of $\texttt{SPS}_+$ where the loss values at optimality are gradually learned, as opposed to being given. We give three viewpoints of $\texttt{FUVAL}$, as a projection based method, as a variant of the prox-linear method, and then as a particular online SGD method. We then present a convergence analysis of $\texttt{FUVAL}$ and experimental results. The shortcomings of our work is that the convergence analysis of $\texttt{FUVAL}$ shows no advantage over SGD. Another shortcomming is that currently only the full batch version of $\texttt{FUVAL}$ shows a minor advantages of GD (Gradient Descent) in terms of sensitivity to the step size. The stochastic version shows no clear advantage over SGD. We conjecture that large mini-batches are required to make $\texttt{FUVAL}$ competitive. Currently the new $\texttt{FUVAL}$ method studied in this paper does not offer any clear theoretical or practical advantage. We have chosen to make this draft available online nonetheless because of some of the analysis techniques we use, such as the non-smooth analysis of $\texttt{SPS}_+$, and also to show an apparently interesting approach that currently does not work.
Online Inventory Problems: Beyond the i.i.d. Setting with Online Convex Optimization
Jul 12, 2023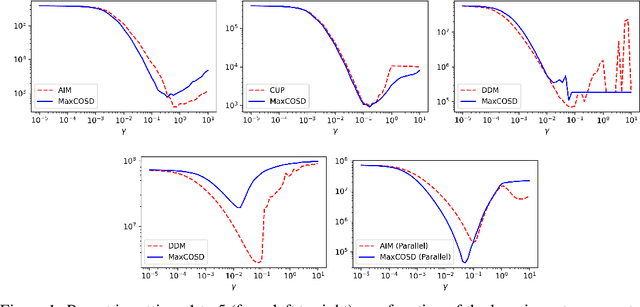
We study multi-product inventory control problems where a manager makes sequential replenishment decisions based on partial historical information in order to minimize its cumulative losses. Our motivation is to consider general demands, losses and dynamics to go beyond standard models which usually rely on newsvendor-type losses, fixed dynamics, and unrealistic i.i.d. demand assumptions. We propose MaxCOSD, an online algorithm that has provable guarantees even for problems with non-i.i.d. demands and stateful dynamics, including for instance perishability. We consider what we call non-degeneracy assumptions on the demand process, and argue that they are necessary to allow learning.
Provable convergence guarantees for black-box variational inference
Jun 04, 2023
While black-box variational inference is widely used, there is no proof that its stochastic optimization succeeds. We suggest this is due to a theoretical gap in existing stochastic optimization proofs-namely the challenge of gradient estimators with unusual noise bounds, and a composite non-smooth objective. For dense Gaussian variational families, we observe that existing gradient estimators based on reparameterization satisfy a quadratic noise bound and give novel convergence guarantees for proximal and projected stochastic gradient descent using this bound. This provides the first rigorous guarantee that black-box variational inference converges for realistic inference problems.
Convergence of the Forward-Backward Algorithm: Beyond the Worst Case with the Help of Geometry
Aug 01, 2017
We provide a comprehensive study of the convergence of forward-backward algorithm under suitable geometric conditions leading to fast rates. We present several new results and collect in a unified view a variety of results scattered in the literature, often providing simplified proofs. Novel contributions include the analysis of infinite dimensional convex minimization problems, allowing the case where minimizers might not exist. Further, we analyze the relation between different geometric conditions, and discuss novel connections with a priori conditions in linear inverse problems, including source conditions, restricted isometry properties and partial smoothness.