 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sample Complexity of Learning for Blind Inverse Problems
Dec 29, 2025Blind inverse problems arise in many experimental settings where the forward operator is partially or entirely unknown. In this context, methods developed for the non-blind case cannot be adapted in a straightforward manner. Recently, data-driven approaches have been proposed to address blind inverse problems, demonstrating strong empirical performance and adaptability. However, these methods often lack interpretability and are not supported by rigorous theoretical guarantees, limiting their reliability in applied domains such as imaging inverse problems. In this work, we shed light on learning in blind inverse problems within the simplified yet insightful framework of Linear Minimum Mean Square Estimators (LMMSEs). We provide an in-depth theoretical analysis, deriving closed-form expressions for optimal estimators and extending classical results. In particular, we establish equivalences with suitably chosen Tikhonov-regularized formulations, where the regularization depends explicitly on the distributions of the unknown signal, the noise, and the random forward operators. We also prove convergence results under appropriate source condition assumptions. Furthermore, we derive rigorous finite-sample error bounds that characterize the performance of learned estimators as a function of the noise level, problem conditioning, and number of available samples. These bounds explicitly quantify the impact of operator randomness and reveal the associated convergence rates as this randomness vanishes. Finally, we validate our theoretical findings through illustrative numerical experiments that confirm the predicted convergence behavior.
Deep Equilibrium models for Poisson Imaging Inverse problems via Mirror Descent
Jul 15, 2025Deep Equilibrium Models (DEQs) are implicit neural networks with fixed points, which have recently gained attention for learning image regularization functionals, particularly in settings involving Gaussian fidelities, where assumptions on the forward operator ensure contractiveness of standard (proximal) Gradient Descent operators. In this work, we extend the application of DEQs to Poisson inverse problems, where the data fidelity term is more appropriately modeled by the Kullback-Leibler divergence. To this end, we introduce a novel DEQ formulation based on Mirror Descent defined in terms of a tailored non-Euclidean geometry that naturally adapts with the structure of the data term. This enables the learning of neural regularizers within a principled training framework. We derive sufficient conditions to guarantee the convergence of the learned reconstruction scheme and propose computational strategies that enable both efficient training and fully parameter-free inference. Numerical experiments show that our method outperforms traditional model-based approaches and it is comparable to the performance of Bregman Plug-and-Play methods, while mitigating their typical drawbacks - namely, sensitivity to initialization and careful tuning of hyperparameters. The code is publicly available at https://github.com/christiandaniele/DEQ-MD.
A Structured Tour of Optimization with Finite Differences
May 26, 2025Finite-difference methods are widely used for zeroth-order optimization in settings where gradient information is unavailable or expensive to compute. These procedures mimic first-order strategies by approximating gradients through function evaluations along a set of random directions. From a theoretical perspective, recent studies indicate that imposing structure (such as orthogonality) on the chosen directions allows for the derivation of convergence rates comparable to those achieved with unstructured random directions (i.e., directions sampled independently from a distribution). Empirically, although structured directions are expected to enhance performance, they often introduce additional computational costs, which can limit their applicability in high-dimensional settings. In this work, we examine the impact of structured direction selection in finite-difference methods. We review and extend several strategies for constructing structured direction matrices and compare them with unstructured approaches in terms of computational cost, gradient approximation quality, and convergence behavior. Our evaluation spans both synthetic tasks and real-world applications such as adversarial perturbation. The results demonstrate that structured directions can be generated with computational costs comparable to unstructured ones while significantly improving gradient estimation accuracy and optimization performance.
Optimization Insights into Deep Diagonal Linear Networks
Dec 21, 2024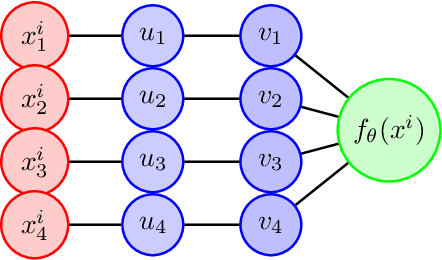
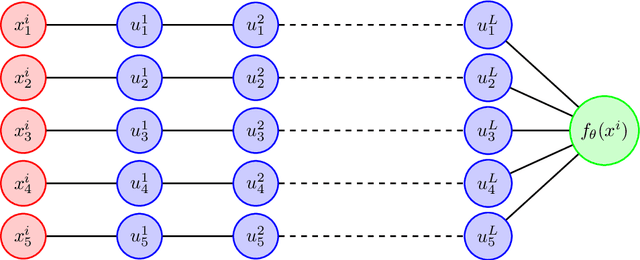
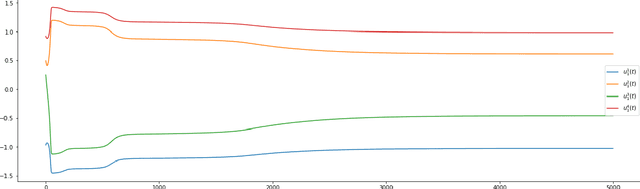
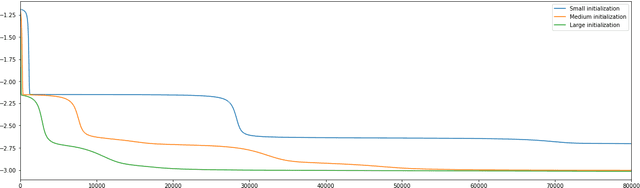
Overparameterized models trained with (stochastic) gradient descent are ubiquitous in modern machine learning. These large models achieve unprecedented performance on test data, but their theoretical understanding is still limited. In this paper, we take a step towards filling this gap by adopting an optimization perspective. More precisely, we study the implicit regularization properties of the gradient flow "algorithm" for estimating the parameters of a deep diagonal neural network. Our main contribution is showing that this gradient flow induces a mirror flow dynamic on the model, meaning that it is biased towards a specific solution of the problem depending on the initialization of the network. Along the way, we prove several properties of the trajectory.
Variance reduction techniques for stochastic proximal point algorithms
Aug 18, 2023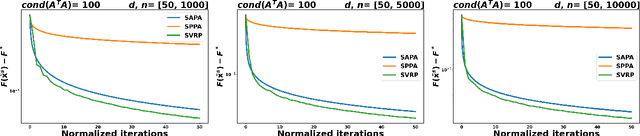
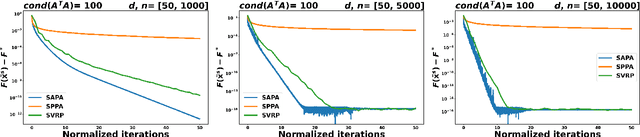
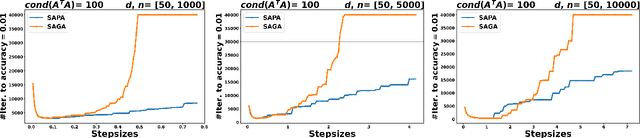
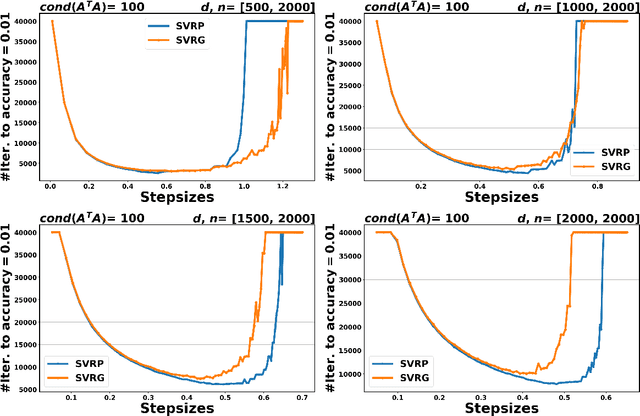
In the context of finite sums minimization, variance reduction techniques are widely used to improve the performance of state-of-the-art stochastic gradient methods. Their practical impact is clear, as well as their theoretical properties. Stochastic proximal point algorithms have been studied as an alternative to stochastic gradient algorithms since they are more stable with respect to the choice of the stepsize but a proper variance reduced version is missing. In this work, we propose the first study of variance reduction techniques for stochastic proximal point algorithms. We introduce a stochastic proximal version of SVRG, SAGA, and some of their variants for smooth and convex functions. We provide several convergence results for the iterates and the objective function values. In addition, under the Polyak-{\L}ojasiewicz (PL) condition, we obtain linear convergence rates for the iterates and the function values. Our numerical experiments demonstrate the advantages of the proximal variance reduction methods over their gradient counterparts, especially about the stability with respect to the choice of the step size.
Snacks: a fast large-scale kernel SVM solver
Apr 17, 2023



Kernel methods provide a powerful framework for non parametric learning. They are based on kernel functions and allow learning in a rich functional space while applying linear statistical learning tools, such as Ridge Regression or Support Vector Machines. However, standard kernel methods suffer from a quadratic time and memory complexity in the number of data points and thus have limited applications in large-scale learning. In this paper, we propose Snacks, a new large-scale solver for Kernel Support Vector Machines. Specifically, Snacks relies on a Nystr\"om approximation of the kernel matrix and an accelerated variant of the stochastic subgradient method. We demonstrate formally through a detailed empirical evaluation, that it competes with other SVM solvers on a variety of benchmark datasets.
Iterative regularization in classification via hinge loss diagonal descent
Dec 24, 2022Iterative regularization is a classic idea in regularization theory, that has recently become popular in machine learning. On the one hand, it allows to design efficient algorithms controlling at the same time numerical and statistical accuracy. On the other hand it allows to shed light on the learning curves observed while training neural networks. In this paper, we focus on iterative regularization in the context of classification. After contrasting this setting with that of regression and inverse problems, we develop an iterative regularization approach based on the use of the hinge loss function. More precisely we consider a diagonal approach for a family of algorithms for which we prove convergence as well as rates of convergence. Our approach compares favorably with other alternatives, as confirmed also in numerical simulations.
Stochastic Zeroth order Descent with Structured Directions
Jun 10, 2022
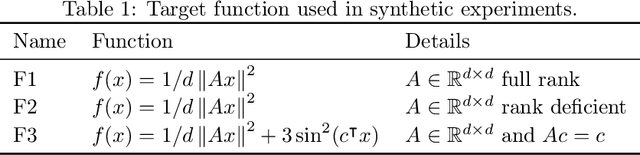

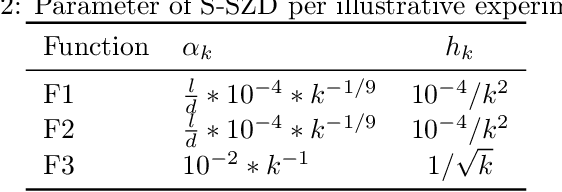
We introduce and analyze Structured Stochastic Zeroth order Descent (S-SZD), a finite difference approach which approximates a stochastic gradient on a set of $l\leq d$ orthogonal directions, where $d$ is the dimension of the ambient space. These directions are randomly chosen, and may change at each step. For smooth convex functions we prove almost sure convergence of the iterates and a convergence rate on the function values of the form $O(d/l k^{-c})$ for every $c<1/2$, which is arbitrarily close to the one of Stochastic Gradient Descent (SGD) in terms of number of iterations. Our bound also shows the benefits of using $l$ multiple directions instead of one. For non-convex functions satisfying the Polyak-{\L}ojasiewicz condition, we establish the first convergence rates for stochastic zeroth order algorithms under such an assumption. We corroborate our theoretical findings in numerical simulations where assumptions are satisfied and on the real-world problem of hyper-parameter optimization, observing that S-SZD has very good practical performances.
Iterative regularization for low complexity regularizers
Feb 01, 2022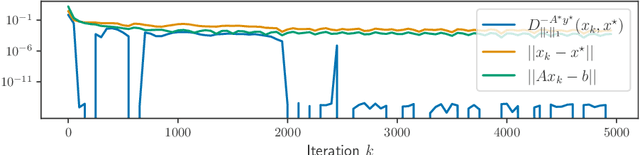
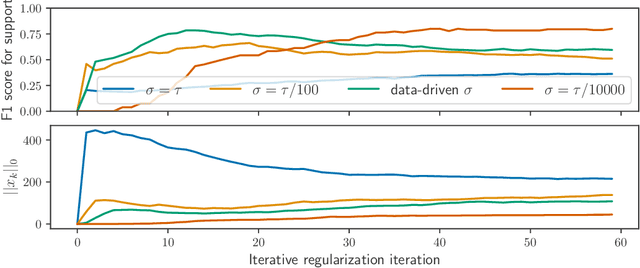
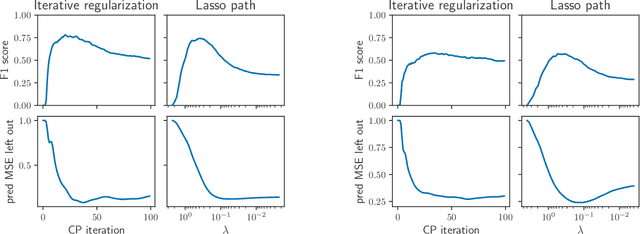
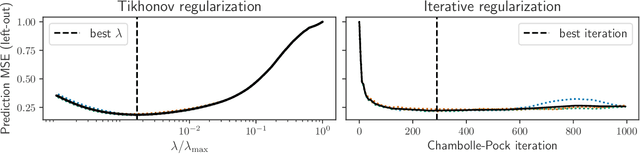
Iterative regularization exploits the implicit bias of an optimization algorithm to regularize ill-posed problems. Constructing algorithms with such built-in regularization mechanisms is a classic challenge in inverse problems but also in modern machine learning, where it provides both a new perspective on algorithms analysis, and significant speed-ups compared to explicit regularization. In this work, we propose and study the first iterative regularization procedure able to handle biases described by non smooth and non strongly convex functionals, prominent in low-complexity regularization. Our approach is based on a primal-dual algorithm of which we analyze convergence and stability properties, even in the case where the original problem is unfeasible. The general results are illustrated considering the special case of sparse recovery with the $\ell_1$ penalty. Our theoretical results are complemented by experiments showing the computational benefits of our approach.
Ada-BKB: Scalable Gaussian Process Optimization on Continuous Domain by Adaptive Discretization
Jun 16, 2021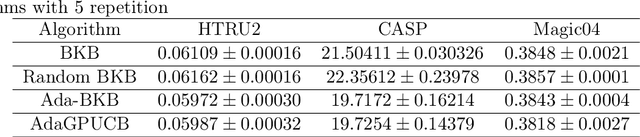



Gaussian process optimization is a successful class of algorithms (e.g. GP-UCB) to optimize a black-box function through sequential evaluations. However, when the domain of the function is continuous, Gaussian process optimization has to either rely on a fixed discretization of the space, or solve a non-convex optimization subproblem at each evaluation. The first approach can negatively affect performance, while the second one puts a heavy computational burden on the algorithm. A third option, that only recently has been theoretically studied, is to adaptively discretize the function domain. Even though this approach avoids the extra non-convex optimization costs, the overall computational complexity is still prohibitive. An algorithm such as GP-UCB has a runtime of $O(T^4)$, where $T$ is the number of iterations. In this paper, we introduce Ada-BKB (Adaptive Budgeted Kernelized Bandit), a no-regret Gaussian process optimization algorithm for functions on continuous domains, that provably runs in $O(T^2 d_\text{eff}^2)$, where $d_\text{eff}$ is the effective dimension of the explored space, and which is typically much smaller than $T$. We corroborate our findings with experiments on synthetic non-convex functions and on the real-world problem of hyper-parameter optimization.