 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Operators of Sorted Nonconvex Penalties
Jun 18, 2025This work studies the problem of sparse signal recovery with automatic grouping of variables. To this end, we investigate sorted nonsmooth penalties as a regularization approach for generalized linear models. We focus on a family of sorted nonconvex penalties which generalizes the Sorted L1 Norm (SLOPE). These penalties are designed to promote clustering of variables due to their sorted nature, while the nonconvexity reduces the shrinkage of coefficients. Our goal is to provide efficient ways to compute their proximal operator, enabling the use of popular proximal algorithms to solve composite optimization problems with this choice of sorted penalties. We distinguish between two classes of problems: the weakly convex case where computing the proximal operator remains a convex problem, and the nonconvex case where computing the proximal operator becomes a challenging nonconvex combinatorial problem. For the weakly convex case (e.g. sorted MCP and SCAD), we explain how the Pool Adjacent Violators (PAV) algorithm can exactly compute the proximal operator. For the nonconvex case (e.g. sorted Lq with q in ]0,1[), we show that a slight modification of this algorithm turns out to be remarkably efficient to tackle the computation of the proximal operator. We also present new theoretical insights on the minimizers of the nonconvex proximal problem. We demonstrate the practical interest of using such penalties on several experiments.
DeepInverse: A Python package for solving imaging inverse problems with deep learning
May 26, 2025DeepInverse is an open-source PyTorch-based library for solving imaging inverse problems. The library covers all crucial steps in image reconstruction from the efficient implementation of forward operators (e.g., optics, MRI, tomography), to the definition and resolution of variational problems and the design and training of advanced neural network architectures. In this paper, we describe the main functionality of the library and discuss the main design choices.
Convexity in ReLU Neural Networks: beyond ICNNs?
Jan 06, 2025Convex functions and their gradients play a critical role in mathematical imaging, from proximal optimization to Optimal Transport. The successes of deep learning has led many to use learning-based methods, where fixed functions or operators are replaced by learned neural networks. Regardless of their empirical superiority, establishing rigorous guarantees for these methods often requires to impose structural constraints on neural architectures, in particular convexity. The most popular way to do so is to use so-called Input Convex Neural Networks (ICNNs). In order to explore the expressivity of ICNNs, we provide necessary and sufficient conditions for a ReLU neural network to be convex. Such characterizations are based on product of weights and activations, and write nicely for any architecture in the path-lifting framework. As particular applications, we study our characterizations in depth for 1 and 2-hidden-layer neural networks: we show that every convex function implemented by a 1-hidden-layer ReLU network can be also expressed by an ICNN with the same architecture; however this property no longer holds with more layers. Finally, we provide a numerical procedure that allows an exact check of convexity for ReLU neural networks with a large number of affine regions.
Schur's Positive-Definite Network: Deep Learning in the SPD cone with structure
Jun 13, 2024Estimating matrices in the symmetric positive-definite (SPD) cone is of interest for many applications ranging from computer vision to graph learning. While there exist various convex optimization-based estimators, they remain limited in expressivity due to their model-based approach. The success of deep learning has thus led many to use neural networks to learn to estimate SPD matrices in a data-driven fashion. For learning structured outputs, one promising strategy involves architectures designed by unrolling iterative algorithms, which potentially benefit from inductive bias properties. However, designing correct unrolled architectures for SPD learning is difficult: they either do not guarantee that their output has all the desired properties, rely on heavy computations, or are overly restrained to specific matrices which hinders their expressivity. In this paper, we propose a novel and generic learning module with guaranteed SPD outputs called SpodNet, that also enables learning a larger class of functions than existing approaches. Notably, it solves the challenging task of learning jointly SPD and sparse matrices. Our experiments demonstrate the versatility of SpodNet layers.
Implicit Differentiation for Hyperparameter Tuning the Weighted Graphical Lasso
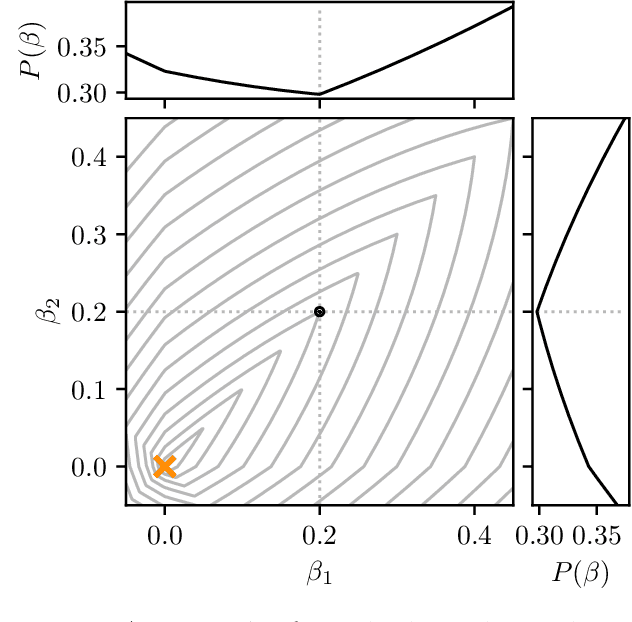
Jul 05, 2023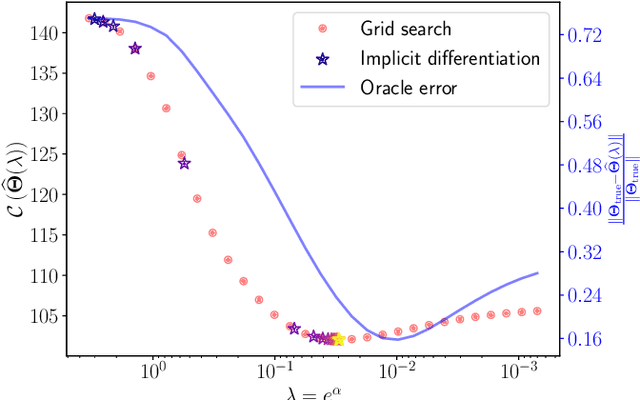
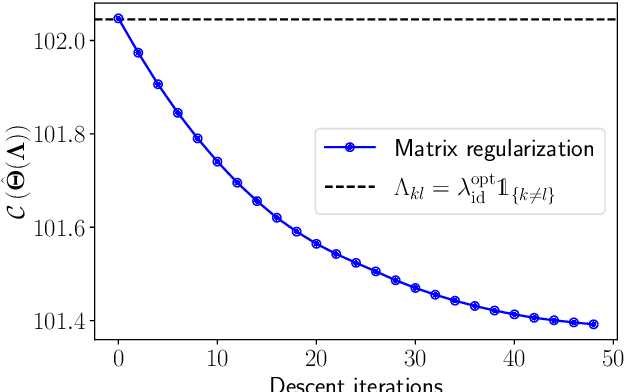
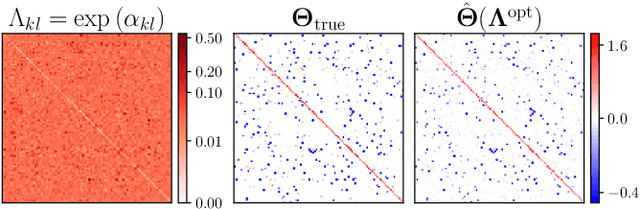
We provide a framework and algorithm for tuning the hyperparameters of the Graphical Lasso via a bilevel optimization problem solved with a first-order method. In particular, we derive the Jacobian of the Graphical Lasso solution with respect to its regularization hyperparameters.
Coordinate Descent for SLOPE
Oct 26, 2022
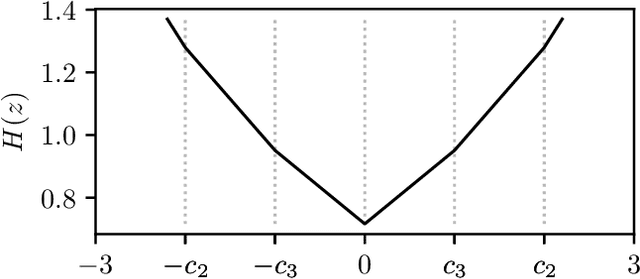

The lasso is the most famous sparse regression and feature selection method. One reason for its popularity is the speed at which the underlying optimization problem can be solved. Sorted L-One Penalized Estimation (SLOPE) is a generalization of the lasso with appealing statistical properties. In spite of this, the method has not yet reached widespread interest. A major reason for this is that current software packages that fit SLOPE rely on algorithms that perform poorly in high dimensions. To tackle this issue, we propose a new fast algorithm to solve the SLOPE optimization problem, which combines proximal gradient descent and proximal coordinate descent steps. We provide new results on the directional derivative of the SLOPE penalty and its related SLOPE thresholding operator, as well as provide convergence guarantees for our proposed solver. In extensive benchmarks on simulated and real data, we show that our method outperforms a long list of competing algorithms.
Benchopt: Reproducible, efficient and collaborative optimization benchmarks
Jun 28, 2022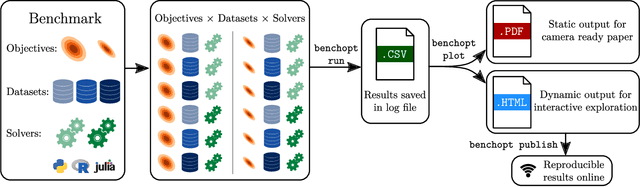
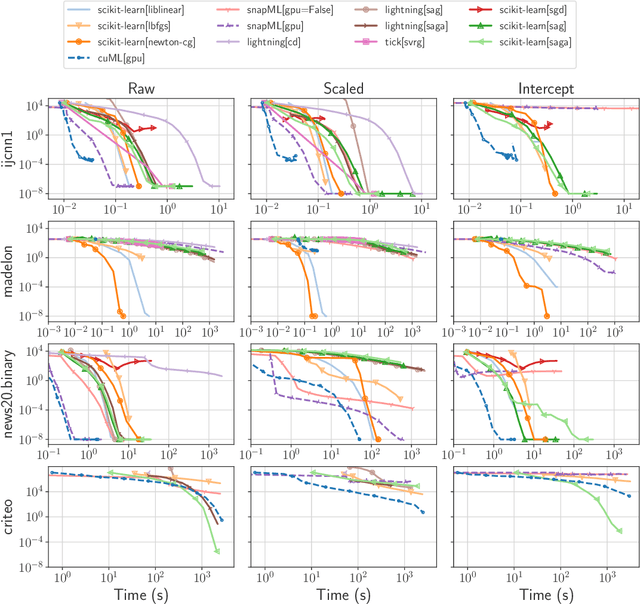
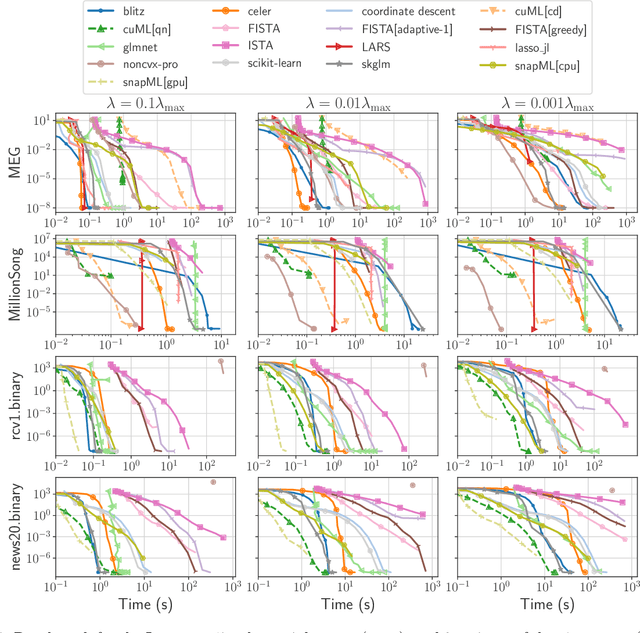
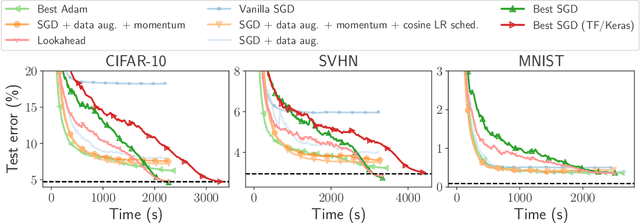
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: $\ell_2$-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.
Beyond L1: Faster and Better Sparse Models with skglm
Apr 16, 2022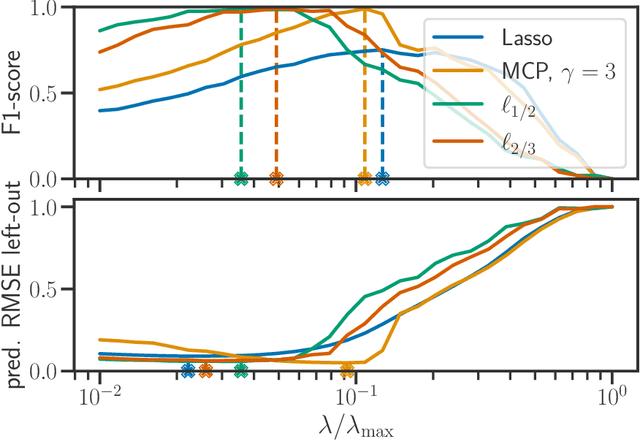
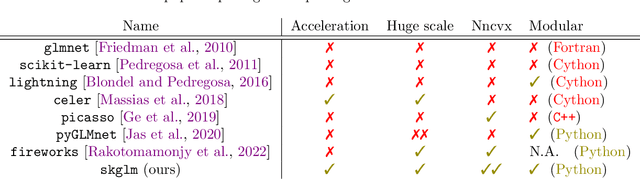
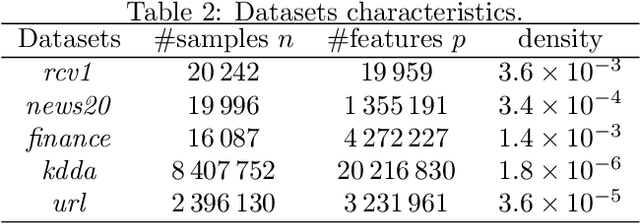
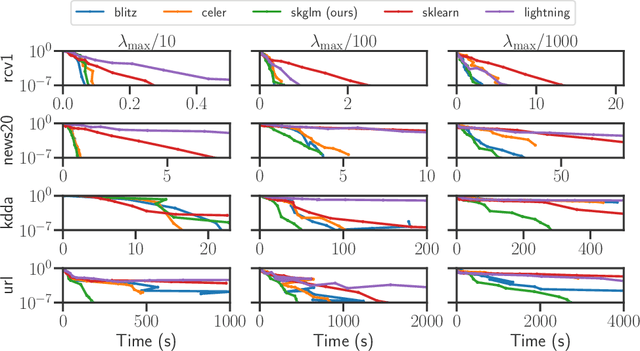
We propose a new fast algorithm to estimate any sparse generalized linear model with convex or non-convex separable penalties. Our algorithm is able to solve problems with millions of samples and features in seconds, by relying on coordinate descent, working sets and Anderson acceleration. It handles previously unaddressed models, and is extensively shown to improve state-of-art algorithms. We provide a flexible, scikit-learn compatible package, which easily handles customized datafits and penalties.
Iterative regularization for low complexity regularizers
Feb 01, 2022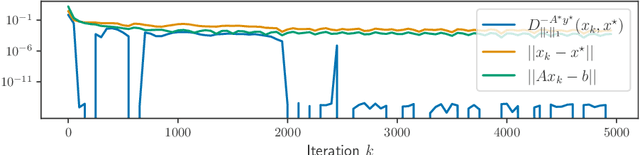
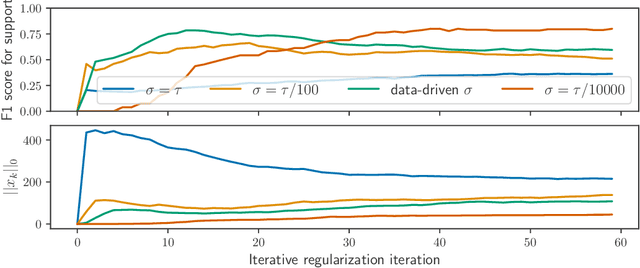
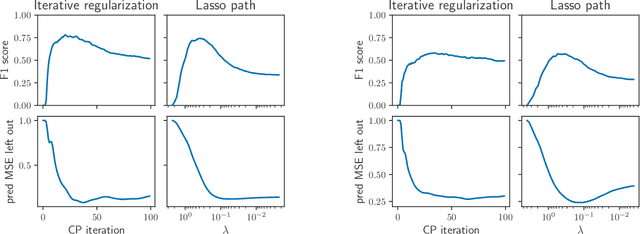
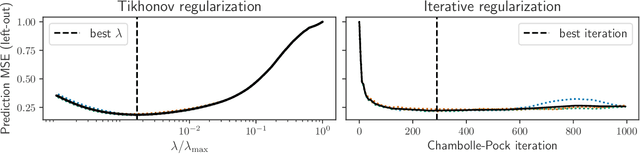
Iterative regularization exploits the implicit bias of an optimization algorithm to regularize ill-posed problems. Constructing algorithms with such built-in regularization mechanisms is a classic challenge in inverse problems but also in modern machine learning, where it provides both a new perspective on algorithms analysis, and significant speed-ups compared to explicit regularization. In this work, we propose and study the first iterative regularization procedure able to handle biases described by non smooth and non strongly convex functionals, prominent in low-complexity regularization. Our approach is based on a primal-dual algorithm of which we analyze convergence and stability properties, even in the case where the original problem is unfeasible. The general results are illustrated considering the special case of sparse recovery with the $\ell_1$ penalty. Our theoretical results are complemented by experiments showing the computational benefits of our approach.
Implicit differentiation for fast hyperparameter selection in non-smooth convex learning
May 17, 2021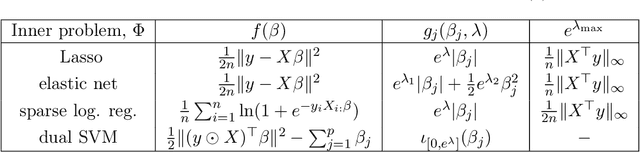
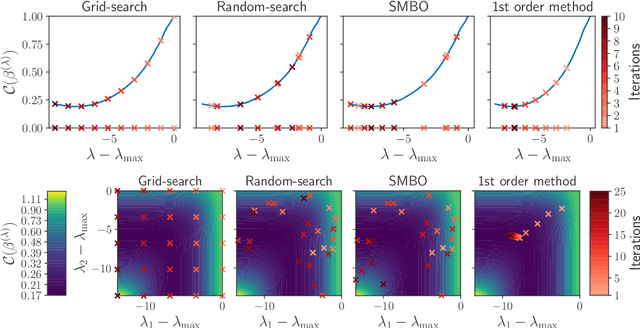
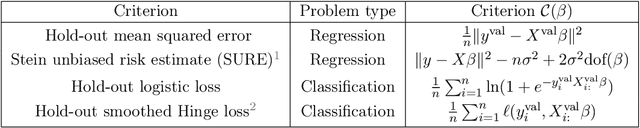
Finding the optimal hyperparameters of a model can be cast as a bilevel optimization problem, typically solved using zero-order techniques. In this work we study first-order methods when the inner optimization problem is convex but non-smooth. We show that the forward-mode differentiation of proximal gradient descent and proximal coordinate descent yield sequences of Jacobians converging toward the exact Jacobian. Using implicit differentiation, we show it is possible to leverage the non-smoothness of the inner problem to speed up the computation. Finally, we provide a bound on the error made on the hypergradient when the inner optimization problem is solved approximately. Results on regression and classification problems reveal computational benefits for hyperparameter optimization, especially when multiple hyperparameters are required.