 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Features Control Emergent Misalignment
Jun 24, 2025



Understanding how language models generalize behaviors from their training to a broader deployment distribution is an important problem in AI safety. Betley et al. discovered that fine-tuning GPT-4o on intentionally insecure code causes "emergent misalignment," where models give stereotypically malicious responses to unrelated prompts. We extend this work, demonstrating emergent misalignment across diverse conditions, including reinforcement learning on reasoning models, fine-tuning on various synthetic datasets, and in models without safety training. To investigate the mechanisms behind this generalized misalignment, we apply a "model diffing" approach using sparse autoencoders to compare internal model representations before and after fine-tuning. This approach reveals several "misaligned persona" features in activation space, including a toxic persona feature which most strongly controls emergent misalignment and can be used to predict whether a model will exhibit such behavior. Additionally, we investigate mitigation strategies, discovering that fine-tuning an emergently misaligned model on just a few hundred benign samples efficiently restores alignment.
Scaling and evaluating sparse autoencoders
Jun 06, 2024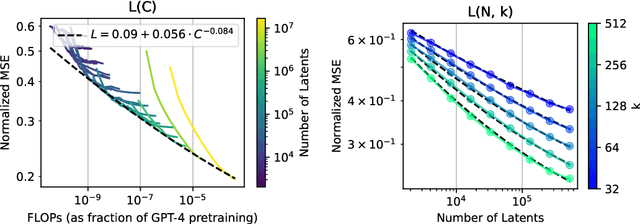
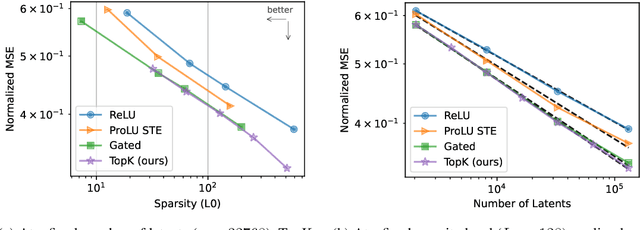
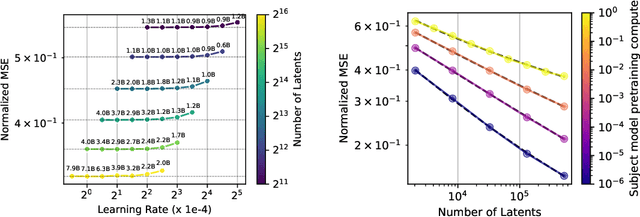
Sparse autoencoders provide a promising unsupervised approach for extracting interpretable features from a language model by reconstructing activations from a sparse bottleneck layer. Since language models learn many concepts, autoencoders need to be very large to recover all relevant features. However, studying the properties of autoencoder scaling is difficult due to the need to balance reconstruction and sparsity objectives and the presence of dead latents. We propose using k-sparse autoencoders [Makhzani and Frey, 2013] to directly control sparsity, simplifying tuning and improving the reconstruction-sparsity frontier. Additionally, we find modifications that result in few dead latents, even at the largest scales we tried. Using these techniques, we find clean scaling laws with respect to autoencoder size and sparsity. We also introduce several new metrics for evaluating feature quality based on the recovery of hypothesized features, the explainability of activation patterns, and the sparsity of downstream effects. These metrics all generally improve with autoencoder size. To demonstrate the scalability of our approach, we train a 16 million latent autoencoder on GPT-4 activations for 40 billion tokens. We release training code and autoencoders for open-source models, as well as a visualizer.
Benchopt: Reproducible, efficient and collaborative optimization benchmarks
Jun 28, 2022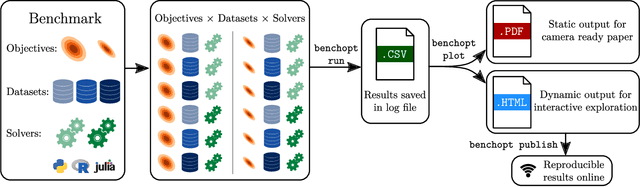
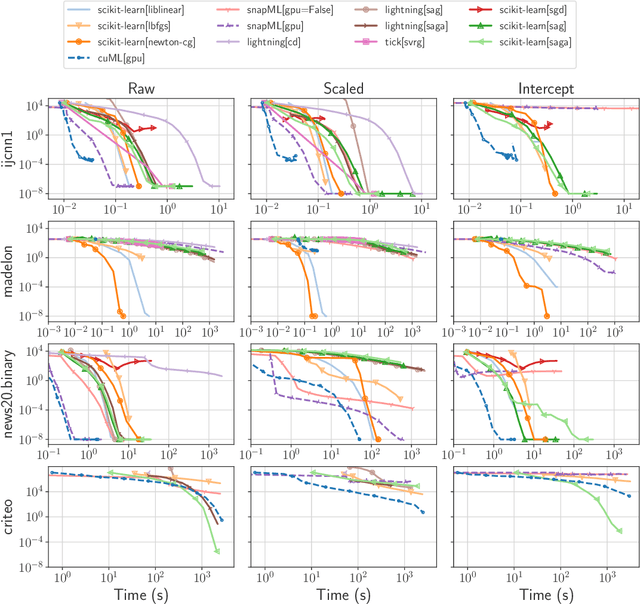
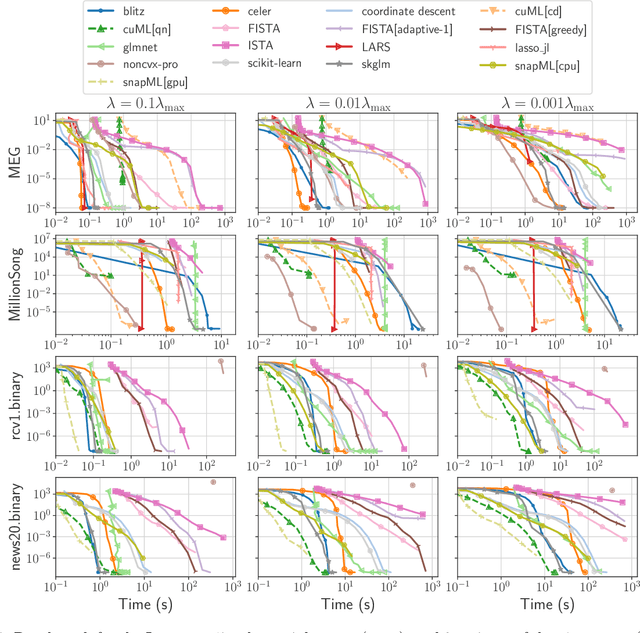
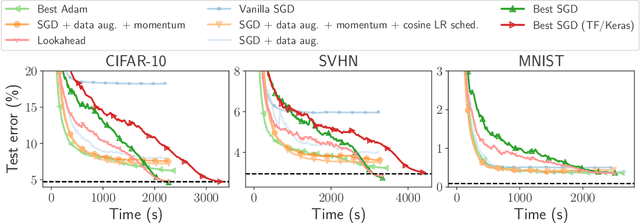
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: $\ell_2$-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.