 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal basin hopping: global optimization with guarantees
May 18, 2026Global optimization is a challenging problem, with plenty of algorithms displaying empirical success, but scarce theoretical backing. In this work, we propose a new theoretical framework called Proximal Basin Hopping (PBH), carefully tailored to combine proximal optimization and local minimization. We use it to construct a practical algorithm that converges to the global minimizer with high probability, when using a finite amount of samples. Proximal Basin Hopping outperforms well known algorithms with theoretical backing on standard synthetic hard functions, and real problems such as fitting scaling laws for deep learning. Furthermore, the higher the dimension, the better the performance gap.
On the Hardness of Junking LLMs
May 06, 2026Large language models (LLMs) are known to be vulnerable to jailbreak attacks, which typically rely on carefully designed prompts containing explicit semantic structure. These attacks generally operate by fixing an adversarial instruction and optimizing small adversarial components (e.g., suffixes or prefixes). In this setting, prompt structure is fundamental for performance, and recent results show that even simple random search can achieve strong performance when combined with sophisticated prompt design. Recently, it has been observed that harmful behaviors can be elicited even without the adversarial prompt, relying solely on optimized token sequences. This suggests the existence of natural backdoors, i.e., token sequences naturally emerged during LLMs training that trigger unsafe outputs without any meaningful instruction. However, despite these observations, this setting remains largely unexplored, and in particular the hardness of finding natural backdoors has not been assessed yet. In this work, we provide a first proof-of-concept study investigating the hardness of this task, which we refer to as the junking problem. We formalize it as the problem of finding token sequences that maximize the probability of generating a target prefix of harmful responses, propose a greedy random-search method to assess is such sequences can be discovered easily. Our results show that this problem is harder than standard jailbreak attacks, confirming the importance of semantic information in prompt design. At the same time, we find that our simple strategy is sufficient to solve it with a high success rate, suggesting that natural backdoors are present and easily recoverable. Finally, through perplexity analysis, we observe that the discovered token sequences lie in low-probability regions of the model distribution, supporting the hypothesis that they emerged implicitly from the training process.
Towards Understanding Steering Strength
Feb 02, 2026A popular approach to post-training control of large language models (LLMs) is the steering of intermediate latent representations. Namely, identify a well-chosen direction depending on the task at hand and perturbs representations along this direction at inference time. While many propositions exist to pick this direction, considerably less is understood about how to choose the magnitude of the move, whereas its importance is clear: too little and the intended behavior does not emerge, too much and the model's performance degrades beyond repair. In this work, we propose the first theoretical analysis of steering strength. We characterize its effect on next token probability, presence of a concept, and cross-entropy, deriving precise qualitative laws governing these quantities. Our analysis reveals surprising behaviors, including non-monotonic effects of steering strength. We validate our theoretical predictions empirically on eleven language models, ranging from a small GPT architecture to modern models.
Fairness-informed Pareto Optimization : An Efficient Bilevel Framework
Jan 19, 2026Despite their promise, fair machine learning methods often yield Pareto-inefficient models, in which the performance of certain groups can be improved without degrading that of others. This issue arises frequently in traditional in-processing approaches such as fairness-through-regularization. In contrast, existing Pareto-efficient approaches are biased towards a certain perspective on fairness and fail to adapt to the broad range of fairness metrics studied in the literature. In this paper, we present BADR, a simple framework to recover the optimal Pareto-efficient model for any fairness metric. Our framework recovers its models through a Bilevel Adaptive Rescalarisation procedure. The lower level is a weighted empirical risk minimization task where the weights are a convex combination of the groups, while the upper level optimizes the chosen fairness objective. We equip our framework with two novel large-scale, single-loop algorithms, BADR-GD and BADR-SGD, and establish their convergence guarantees. We release badr, an open-source Python toolbox implementing our framework for a variety of learning tasks and fairness metrics. Finally, we conduct extensive numerical experiments demonstrating the advantages of BADR over existing Pareto-efficient approaches to fairness.
From Shortcut to Induction Head: How Data Diversity Shapes Algorithm Selection in Transformers
Dec 21, 2025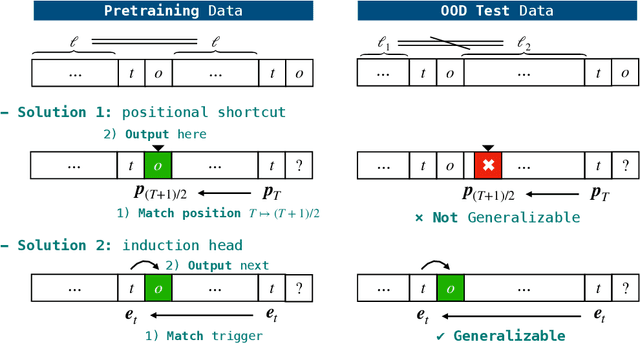
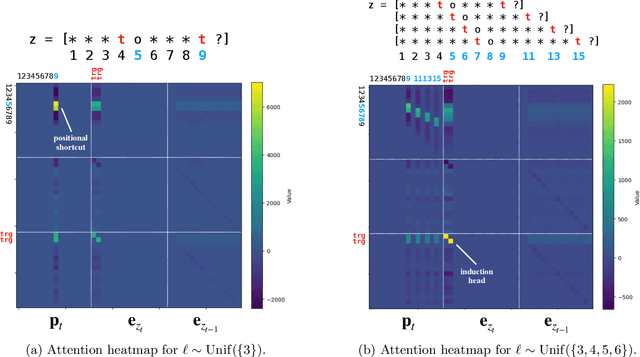
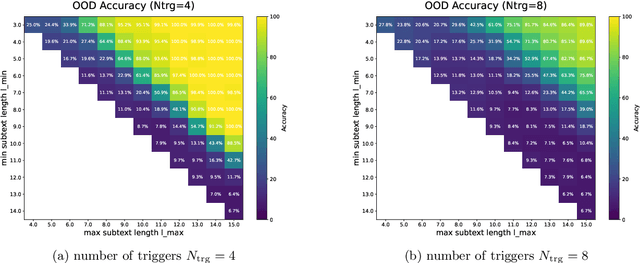
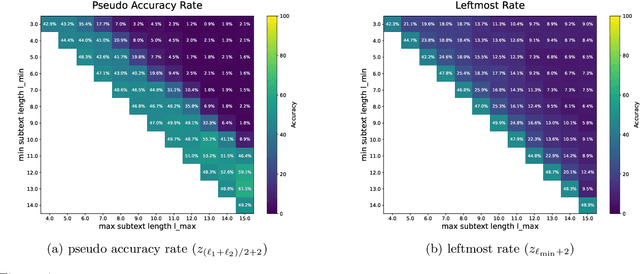
Transformers can implement both generalizable algorithms (e.g., induction heads) and simple positional shortcuts (e.g., memorizing fixed output positions). In this work, we study how the choice of pretraining data distribution steers a shallow transformer toward one behavior or the other. Focusing on a minimal trigger-output prediction task -- copying the token immediately following a special trigger upon its second occurrence -- we present a rigorous analysis of gradient-based training of a single-layer transformer. In both the infinite and finite sample regimes, we prove a transition in the learned mechanism: if input sequences exhibit sufficient diversity, measured by a low ``max-sum'' ratio of trigger-to-trigger distances, the trained model implements an induction head and generalizes to unseen contexts; by contrast, when this ratio is large, the model resorts to a positional shortcut and fails to generalize out-of-distribution (OOD). We also reveal a trade-off between the pretraining context length and OOD generalization, and derive the optimal pretraining distribution that minimizes computational cost per sample. Finally, we validate our theoretical predictions with controlled synthetic experiments, demonstrating that broadening context distributions robustly induces induction heads and enables OOD generalization. Our results shed light on the algorithmic biases of pretrained transformers and offer conceptual guidelines for data-driven control of their learned behaviors.
Deep Equilibrium models for Poisson Imaging Inverse problems via Mirror Descent
Jul 15, 2025Deep Equilibrium Models (DEQs) are implicit neural networks with fixed points, which have recently gained attention for learning image regularization functionals, particularly in settings involving Gaussian fidelities, where assumptions on the forward operator ensure contractiveness of standard (proximal) Gradient Descent operators. In this work, we extend the application of DEQs to Poisson inverse problems, where the data fidelity term is more appropriately modeled by the Kullback-Leibler divergence. To this end, we introduce a novel DEQ formulation based on Mirror Descent defined in terms of a tailored non-Euclidean geometry that naturally adapts with the structure of the data term. This enables the learning of neural regularizers within a principled training framework. We derive sufficient conditions to guarantee the convergence of the learned reconstruction scheme and propose computational strategies that enable both efficient training and fully parameter-free inference. Numerical experiments show that our method outperforms traditional model-based approaches and it is comparable to the performance of Bregman Plug-and-Play methods, while mitigating their typical drawbacks - namely, sensitivity to initialization and careful tuning of hyperparameters. The code is publicly available at https://github.com/christiandaniele/DEQ-MD.
Differentiable Generalized Sliced Wasserstein Plans
May 28, 2025Optimal Transport (OT) has attracted significant interest in the machine learning community, not only for its ability to define meaningful distances between probability distributions -- such as the Wasserstein distance -- but also for its formulation of OT plans. Its computational complexity remains a bottleneck, though, and slicing techniques have been developed to scale OT to large datasets. Recently, a novel slicing scheme, dubbed min-SWGG, lifts a single one-dimensional plan back to the original multidimensional space, finally selecting the slice that yields the lowest Wasserstein distance as an approximation of the full OT plan. Despite its computational and theoretical advantages, min-SWGG inherits typical limitations of slicing methods: (i) the number of required slices grows exponentially with the data dimension, and (ii) it is constrained to linear projections. Here, we reformulate min-SWGG as a bilevel optimization problem and propose a differentiable approximation scheme to efficiently identify the optimal slice, even in high-dimensional settings. We furthermore define its generalized extension for accommodating to data living on manifolds. Finally, we demonstrate the practical value of our approach in various applications, including gradient flows on manifolds and high-dimensional spaces, as well as a novel sliced OT-based conditional flow matching for image generation -- where fast computation of transport plans is essential.
Learning Theory for Kernel Bilevel Optimization
Feb 12, 2025
Bilevel optimization has emerged as a technique for addressing a wide range of machine learning problems that involve an outer objective implicitly determined by the minimizer of an inner problem. In this paper, we investigate the generalization properties for kernel bilevel optimization problems where the inner objective is optimized over a Reproducing Kernel Hilbert Space. This setting enables rich function approximation while providing a foundation for rigorous theoretical analysis. In this context, we establish novel generalization error bounds for the bilevel problem under finite-sample approximation. Our approach adopts a functional perspective, inspired by (Petrulionyte et al., 2024), and leverages tools from empirical process theory and maximal inequalities for degenerate $U$-processes to derive uniform error bounds. These generalization error estimates allow to characterize the statistical accuracy of gradient-based methods applied to the empirical discretization of the bilevel problem.
CHANI: Correlation-based Hawkes Aggregation of Neurons with bio-Inspiration
May 29, 2024



The present work aims at proving mathematically that a neural network inspired by biology can learn a classification task thanks to local transformations only. In this purpose, we propose a spiking neural network named CHANI (Correlation-based Hawkes Aggregation of Neurons with bio-Inspiration), whose neurons activity is modeled by Hawkes processes. Synaptic weights are updated thanks to an expert aggregation algorithm, providing a local and simple learning rule. We were able to prove that our network can learn on average and asymptotically. Moreover, we demonstrated that it automatically produces neuronal assemblies in the sense that the network can encode several classes and that a same neuron in the intermediate layers might be activated by more than one class, and we provided numerical simulations on synthetic dataset. This theoretical approach contrasts with the traditional empirical validation of biologically inspired networks and paves the way for understanding how local learning rules enable neurons to form assemblies able to represent complex concepts.
Derivatives of Stochastic Gradient Descent
May 24, 2024

We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(\log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.