 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Consistency of Discrete-to-Continuous Limits of Determinantal Point Processes
Mar 02, 2026We investigate the limiting behavior of discrete determinantal point processes (DPPs) towards continuous DPPs when the size of the set to sample from goes to infinity. We propose a non-asymptotic characterization of this limit in terms of the concentration of statistics associated to these processes, which we refer to as "weak coherency". This allows to translate statistical guarantees from the limiting process to the original, discrete one. Our main result describes sufficient conditions for weak coherency to hold. In particular, our study encompasses settings where both the kernel of the continuous process and its underlying space are inaccessible, or when the discrete marginal kernel is a noisy version of its continuous counterpart. We illustrate our theory on several examples. We prove that a discrete multivariate orthogonal polynomial ensemble can be used to produce coresets strictly smaller than independent sampling for the same error. We propose a process achieving repulsive sampling on an unknown manifold from a set of points sampled from an unknown density. Finally, we show that continuous DPPs can be obtained as limits on random graphs with Bernoulli edges, even when only observing the graph structure. We obtain interesting byproduct results along the way.
Compressing image encoders via latent distillation
Jan 09, 2026Deep learning models for image compression often face practical limitations in hardware-constrained applications. Although these models achieve high-quality reconstructions, they are typically complex, heavyweight, and require substantial training data and computational resources. We propose a methodology to partially compress these networks by reducing the size of their encoders. Our approach uses a simplified knowledge distillation strategy to approximate the latent space of the original models with less data and shorter training, yielding lightweight encoders from heavyweight ones. We evaluate the resulting lightweight encoders across two different architectures on the image compression task. Experiments show that our method preserves reconstruction quality and statistical fidelity better than training lightweight encoders with the original loss, making it practical for resource-limited environments.
Taxonomy of reduction matrices for Graph Coarsening
Jun 13, 2025Graph coarsening aims to diminish the size of a graph to lighten its memory footprint, and has numerous applications in graph signal processing and machine learning. It is usually defined using a reduction matrix and a lifting matrix, which, respectively, allows to project a graph signal from the original graph to the coarsened one and back. This results in a loss of information measured by the so-called Restricted Spectral Approximation (RSA). Most coarsening frameworks impose a fixed relationship between the reduction and lifting matrices, generally as pseudo-inverses of each other, and seek to define a coarsening that minimizes the RSA. In this paper, we remark that the roles of these two matrices are not entirely symmetric: indeed, putting constraints on the lifting matrix alone ensures the existence of important objects such as the coarsened graph's adjacency matrix or Laplacian. In light of this, in this paper, we introduce a more general notion of reduction matrix, that is not necessarily the pseudo-inverse of the lifting matrix. We establish a taxonomy of ``admissible'' families of reduction matrices, discuss the different properties that they must satisfy and whether they admit a closed-form description or not. We show that, for a fixed coarsening represented by a fixed lifting matrix, the RSA can be further reduced simply by modifying the reduction matrix. We explore different examples, including some based on a constrained optimization process of the RSA. Since this criterion has also been linked to the performance of Graph Neural Networks, we also illustrate the impact of this choices on different node classification tasks on coarsened graphs.
Backward Oversmoothing: why is it hard to train deep Graph Neural Networks?
May 22, 2025Oversmoothing has long been identified as a major limitation of Graph Neural Networks (GNNs): input node features are smoothed at each layer and converge to a non-informative representation, if the weights of the GNN are sufficiently bounded. This assumption is crucial: if, on the contrary, the weights are sufficiently large, then oversmoothing may not happen. Theoretically, GNN could thus learn to not oversmooth. However it does not really happen in practice, which prompts us to examine oversmoothing from an optimization point of view. In this paper, we analyze backward oversmoothing, that is, the notion that backpropagated errors used to compute gradients are also subject to oversmoothing from output to input. With non-linear activation functions, we outline the key role of the interaction between forward and backward smoothing. Moreover, we show that, due to backward oversmoothing, GNNs provably exhibit many spurious stationary points: as soon as the last layer is trained, the whole GNN is at a stationary point. As a result, we can exhibit regions where gradients are near-zero while the loss stays high. The proof relies on the fact that, unlike forward oversmoothing, backward errors are subjected to a linear oversmoothing even in the presence of non-linear activation function, such that the average of the output error plays a key role. Additionally, we show that this phenomenon is specific to deep GNNs, and exhibit counter-example Multi-Layer Perceptron. This paper is a step toward a more complete comprehension of the optimization landscape specific to GNNs.
Node Regression on Latent Position Random Graphs via Local Averaging
Oct 29, 2024



Node regression consists in predicting the value of a graph label at a node, given observations at the other nodes. To gain some insight into the performance of various estimators for this task, we perform a theoretical study in a context where the graph is random. Specifically, we assume that the graph is generated by a Latent Position Model, where each node of the graph has a latent position, and the probability that two nodes are connected depend on the distance between the latent positions of the two nodes. In this context, we begin by studying the simplest possible estimator for graph regression, which consists in averaging the value of the label at all neighboring nodes. We show that in Latent Position Models this estimator tends to a Nadaraya Watson estimator in the latent space, and that its rate of convergence is in fact the same. One issue with this standard estimator is that it averages over a region consisting of all neighbors of a node, and that depending on the graph model this may be too much or too little. An alternative consists in first estimating the true distances between the latent positions, then injecting these estimated distances into a classical Nadaraya Watson estimator. This enables averaging in regions either smaller or larger than the typical graph neighborhood. We show that this method can achieve standard nonparametric rates in certain instances even when the graph neighborhood is too large or too small.
Graph Coarsening with Message-Passing Guarantees
May 28, 2024Graph coarsening aims to reduce the size of a large graph while preserving some of its key properties, which has been used in many applications to reduce computational load and memory footprint. For instance, in graph machine learning, training Graph Neural Networks (GNNs) on coarsened graphs leads to drastic savings in time and memory. However, GNNs rely on the Message-Passing (MP) paradigm, and classical spectral preservation guarantees for graph coarsening do not directly lead to theoretical guarantees when performing naive message-passing on the coarsened graph. In this work, we propose a new message-passing operation specific to coarsened graphs, which exhibit theoretical guarantees on the preservation of the propagated signal. Interestingly, and in a sharp departure from previous proposals, this operation on coarsened graphs is oriented, even when the original graph is undirected. We conduct node classification tasks on synthetic and real data and observe improved results compared to performing naive message-passing on the coarsened graph.
What functions can Graph Neural Networks compute on random graphs? The role of Positional Encoding
May 24, 2023


We aim to deepen the theoretical understanding of Graph Neural Networks (GNNs) on large graphs, with a focus on their expressive power. Existing analyses relate this notion to the graph isomorphism problem, which is mostly relevant for graphs of small sizes, or studied graph classification or regression tasks, while prediction tasks on nodes are far more relevant on large graphs. Recently, several works showed that, on very general random graphs models, GNNs converge to certains functions as the number of nodes grows. In this paper, we provide a more complete and intuitive description of the function space generated by equivariant GNNs for node-tasks, through general notions of convergence that encompass several previous examples. We emphasize the role of input node features, and study the impact of node Positional Encodings (PEs), a recent line of work that has been shown to yield state-of-the-art results in practice. Through the study of several examples of PEs on large random graphs, we extend previously known universality results to significantly more general models. Our theoretical results hint at some normalization tricks, which is shown numerically to have a positive impact on GNN generalization on synthetic and real data. Our proofs contain new concentration inequalities of independent interest.
Convergence of Message Passing Graph Neural Networks with Generic Aggregation On Large Random Graphs
Apr 21, 2023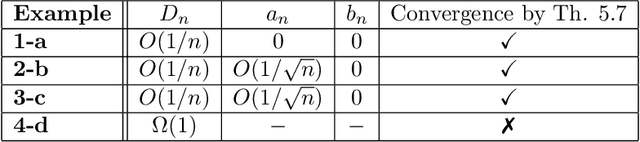
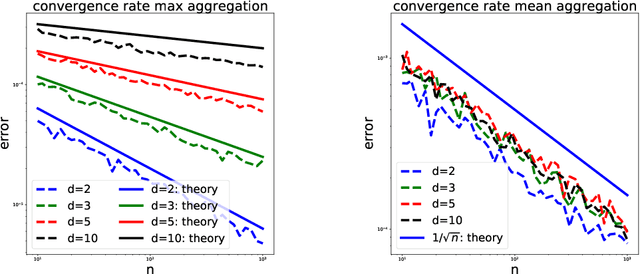
We study the convergence of message passing graph neural networks on random graph models to their continuous counterpart as the number of nodes tends to infinity. Until now, this convergence was only known for architectures with aggregation functions in the form of degree-normalized means. We extend such results to a very large class of aggregation functions, that encompasses all classically used message passing graph neural networks, such as attention-based mesage passing or max convolutional message passing on top of (degree-normalized) convolutional message passing. Under mild assumptions, we give non asymptotic bounds with high probability to quantify this convergence. Our main result is based on the McDiarmid inequality. Interestingly, we treat the case where the aggregation is a coordinate-wise maximum separately, at it necessitates a very different proof technique and yields a qualitatively different convergence rate.
Gradient scarcity with Bilevel Optimization for Graph Learning
Mar 24, 2023



A common issue in graph learning under the semi-supervised setting is referred to as gradient scarcity. That is, learning graphs by minimizing a loss on a subset of nodes causes edges between unlabelled nodes that are far from labelled ones to receive zero gradients. The phenomenon was first described when optimizing the graph and the weights of a Graph Neural Network (GCN) with a joint optimization algorithm. In this work, we give a precise mathematical characterization of this phenomenon, and prove that it also emerges in bilevel optimization, where additional dependency exists between the parameters of the problem. While for GCNs gradient scarcity occurs due to their finite receptive field, we show that it also occurs with the Laplacian regularization model, in the sense that gradients amplitude decreases exponentially with distance to labelled nodes. To alleviate this issue, we study several solutions: we propose to resort to latent graph learning using a Graph-to-Graph model (G2G), graph regularization to impose a prior structure on the graph, or optimizing on a larger graph than the original one with a reduced diameter. Our experiments on synthetic and real datasets validate our analysis and prove the efficiency of the proposed solutions.
Stability of Entropic Wasserstein Barycenters and application to random geometric graphs
Oct 19, 2022

As interest in graph data has grown in recent years, the computation of various geometric tools has become essential. In some area such as mesh processing, they often rely on the computation of geodesics and shortest paths in discretized manifolds. A recent example of such a tool is the computation of Wasserstein barycenters (WB), a very general notion of barycenters derived from the theory of Optimal Transport, and their entropic-regularized variant. In this paper, we examine how WBs on discretized meshes relate to the geometry of the underlying manifold. We first provide a generic stability result with respect to the input cost matrices. We then apply this result to random geometric graphs on manifolds, whose shortest paths converge to geodesics, hence proving the consistency of WBs computed on discretized shapes.