 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALED : Surrogate-gradient for Codec-Aware Learning of Downsampling in ABR Streaming
Jan 30, 2026The rapid growth in video consumption has introduced significant challenges to modern streaming architectures. Over-the-Top (OTT) video delivery now predominantly relies on Adaptive Bitrate (ABR) streaming, which dynamically adjusts bitrate and resolution based on client-side constraints such as display capabilities and network bandwidth. This pipeline typically involves downsampling the original high-resolution content, encoding and transmitting it, followed by decoding and upsampling on the client side. Traditionally, these processing stages have been optimized in isolation, leading to suboptimal end-to-end rate-distortion (R-D) performance. The advent of deep learning has spurred interest in jointly optimizing the ABR pipeline using learned resampling methods. However, training such systems end-to-end remains challenging due to the non-differentiable nature of standard video codecs, which obstructs gradient-based optimization. Recent works have addressed this issue using differentiable proxy models, based either on deep neural networks or hybrid coding schemes with differentiable components such as soft quantization, to approximate the codec behavior. While differentiable proxy codecs have enabled progress in compression-aware learning, they remain approximations that may not fully capture the behavior of standard, non-differentiable codecs. To our knowledge, there is no prior evidence demonstrating the inefficiencies of using standard codecs during training. In this work, we introduce a novel framework that enables end-to-end training with real, non-differentiable codecs by leveraging data-driven surrogate gradients derived from actual compression errors. It facilitates the alignment between training objectives and deployment performance. Experimental results show a 5.19\% improvement in BD-BR (PSNR) compared to codec-agnostic training approaches, consistently across the entire rate-distortion convex hull spanning multiple downsampling ratios.
Taxonomy of reduction matrices for Graph Coarsening
Jun 13, 2025Graph coarsening aims to diminish the size of a graph to lighten its memory footprint, and has numerous applications in graph signal processing and machine learning. It is usually defined using a reduction matrix and a lifting matrix, which, respectively, allows to project a graph signal from the original graph to the coarsened one and back. This results in a loss of information measured by the so-called Restricted Spectral Approximation (RSA). Most coarsening frameworks impose a fixed relationship between the reduction and lifting matrices, generally as pseudo-inverses of each other, and seek to define a coarsening that minimizes the RSA. In this paper, we remark that the roles of these two matrices are not entirely symmetric: indeed, putting constraints on the lifting matrix alone ensures the existence of important objects such as the coarsened graph's adjacency matrix or Laplacian. In light of this, in this paper, we introduce a more general notion of reduction matrix, that is not necessarily the pseudo-inverse of the lifting matrix. We establish a taxonomy of ``admissible'' families of reduction matrices, discuss the different properties that they must satisfy and whether they admit a closed-form description or not. We show that, for a fixed coarsening represented by a fixed lifting matrix, the RSA can be further reduced simply by modifying the reduction matrix. We explore different examples, including some based on a constrained optimization process of the RSA. Since this criterion has also been linked to the performance of Graph Neural Networks, we also illustrate the impact of this choices on different node classification tasks on coarsened graphs.
Light-weight CNN-based VVC Inter Partitioning Acceleration
Dec 17, 2023



The Versatile Video Coding (VVC) standard has been finalized by Joint Video Exploration Team (JVET) in 2020. Compared to the High Efficiency Video Coding (HEVC) standard, VVC offers about 50% compression efficiency gain, in terms of Bjontegaard Delta-Rate (BD-rate), at the cost of about 10x more encoder complexity. In this paper, we propose a Convolutional Neural Network (CNN)-based method to speed up inter partitioning in VVC. Our method operates at the Coding Tree Unit (CTU) level, by splitting each CTU into a fixed grid of 8x8 blocks. Then each cell in this grid is associated with information about the partitioning depth within that area. A lightweight network for predicting this grid is employed during the rate-distortion optimization to limit the Quaternary Tree (QT)-split search and avoid partitions that are unlikely to be selected. Experiments show that the proposed method can achieve acceleration ranging from 17% to 30% in the RandomAccess Group Of Picture 32 (RAGOP32) mode of VVC Test Model (VTM)10 with a reasonable efficiency drop ranging from 0.37% to 1.18% in terms of BD-rate increase.
CNN-based Prediction of Partition Path for VVC Fast Inter Partitioning Using Motion Fields
Oct 20, 2023



The Versatile Video Coding (VVC) standard has been recently finalized by the Joint Video Exploration Team (JVET). Compared to the High Efficiency Video Coding (HEVC) standard, VVC offers about 50% compression efficiency gain, in terms of Bjontegaard Delta-Rate (BD-rate), at the cost of a 10-fold increase in encoding complexity. In this paper, we propose a method based on Convolutional Neural Network (CNN) to speed up the inter partitioning process in VVC. Firstly, a novel representation for the quadtree with nested multi-type tree (QTMT) partition is introduced, derived from the partition path. Secondly, we develop a U-Net-based CNN taking a multi-scale motion vector field as input at the Coding Tree Unit (CTU) level. The purpose of CNN inference is to predict the optimal partition path during the Rate-Distortion Optimization (RDO) process. To achieve this, we divide CTU into grids and predict the Quaternary Tree (QT) depth and Multi-type Tree (MT) split decisions for each cell of the grid. Thirdly, an efficient partition pruning algorithm is introduced to employ the CNN predictions at each partitioning level to skip RDO evaluations of unnecessary partition paths. Finally, an adaptive threshold selection scheme is designed, making the trade-off between complexity and efficiency scalable. Experiments show that the proposed method can achieve acceleration ranging from 16.5% to 60.2% under the RandomAccess Group Of Picture 32 (RAGOP32) configuration with a reasonable efficiency drop ranging from 0.44% to 4.59% in terms of BD-rate, which surpasses other state-of-the-art solutions. Additionally, our method stands out as one of the lightest approaches in the field, which ensures its applicability to other encoders.
OSLO: On-the-Sphere Learning for Omnidirectional images and its application to 360-degree image compression
Jul 19, 2021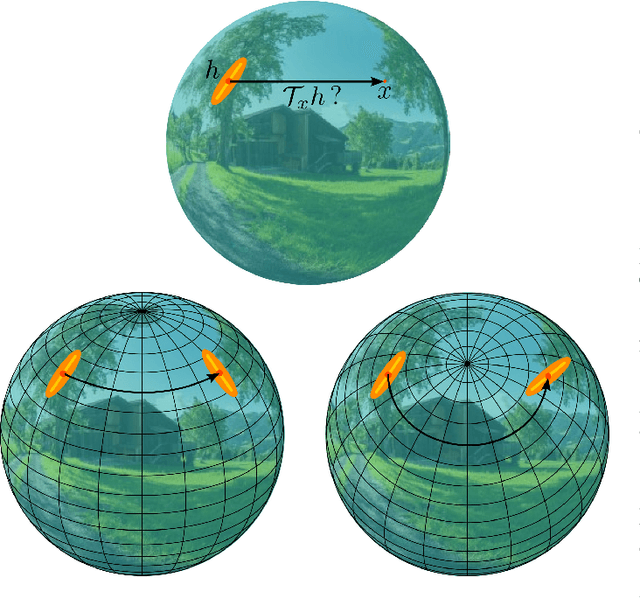
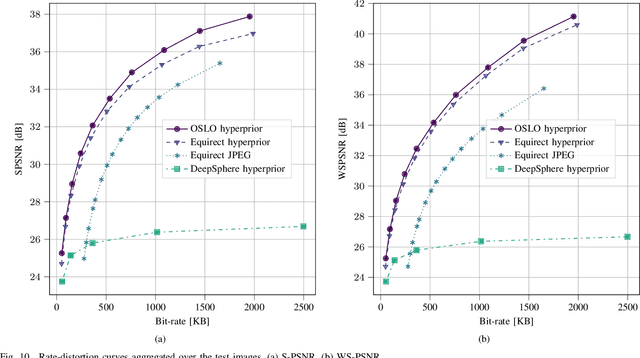
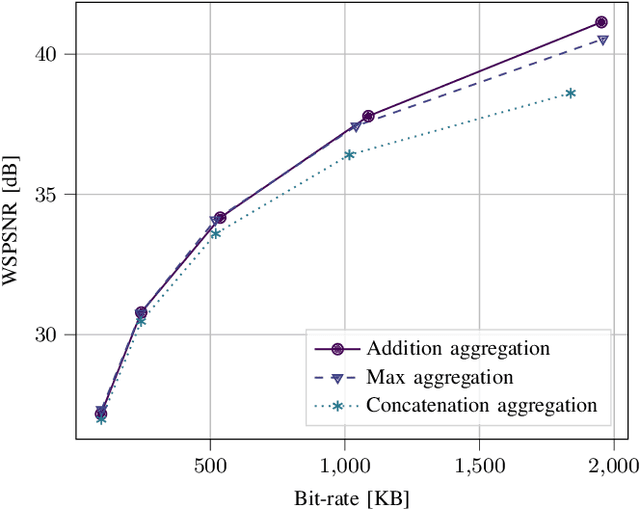
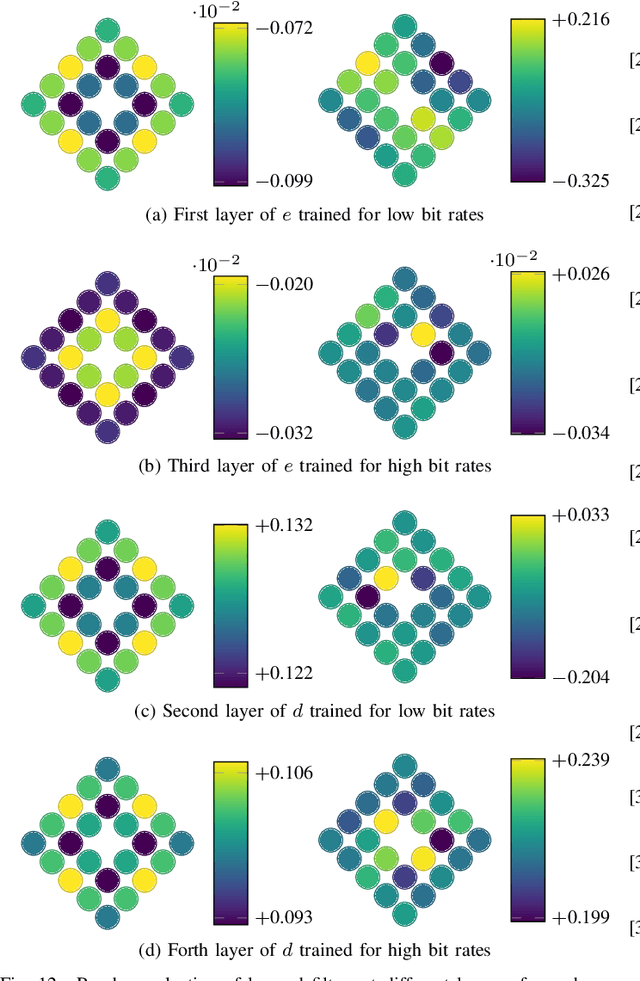
State-of-the-art 2D image compression schemes rely on the power of convolutional neural networks (CNNs). Although CNNs offer promising perspectives for 2D image compression, extending such models to omnidirectional images is not straightforward. First, omnidirectional images have specific spatial and statistical properties that can not be fully captured by current CNN models. Second, basic mathematical operations composing a CNN architecture, e.g., translation and sampling, are not well-defined on the sphere. In this paper, we study the learning of representation models for omnidirectional images and propose to use the properties of HEALPix uniform sampling of the sphere to redefine the mathematical tools used in deep learning models for omnidirectional images. In particular, we: i) propose the definition of a new convolution operation on the sphere that keeps the high expressiveness and the low complexity of a classical 2D convolution; ii) adapt standard CNN techniques such as stride, iterative aggregation, and pixel shuffling to the spherical domain; and then iii) apply our new framework to the task of omnidirectional image compression. Our experiments show that our proposed on-the-sphere solution leads to a better compression gain that can save 13.7% of the bit rate compared to similar learned models applied to equirectangular images. Also, compared to learning models based on graph convolutional networks, our solution supports more expressive filters that can preserve high frequencies and provide a better perceptual quality of the compressed images. Such results demonstrate the efficiency of the proposed framework, which opens new research venues for other omnidirectional vision tasks to be effectively implemented on the sphere manifold.
Fine granularity access in interactive compression of 360-degree images based on rate adaptive channel codes
Jun 25, 2020
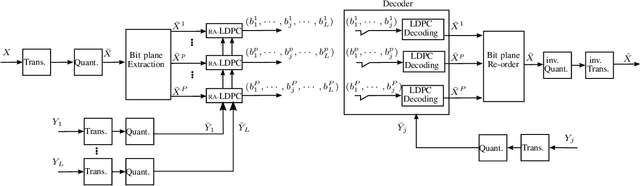

In this paper, we propose a new interactive compression scheme for omnidirectional images. This requires two characteristics: efficient compression of data, to lower the storage cost, and random access ability to extract part of the compressed stream requested by the user (for reducing the transmission rate). For efficient compression, data needs to be predicted by a series of references that have been pre-defined and compressed. This contrasts with the spirit of random accessibility. We propose a solution for this problem based on incremental codes implemented by rate adaptive channel codes. This scheme encodes the image while adapting to any user request and leads to an efficient coding that is flexible in extracting data depending on the available information at the decoder. Therefore, only the information that is needed to be displayed at the user's side is transmitted during the user's request as if the request was already known at the encoder. The experimental results demonstrate that our coder obtains better transmission rate than the state-of-the-art tile-based methods at a small cost in storage. Moreover, the transmission rate grows gradually with the size of the request and avoids a staircase effect, which shows the perfect suitability of our coder for interactive transmission.
Context-adaptive neural network based prediction for image compression
Jul 17, 2018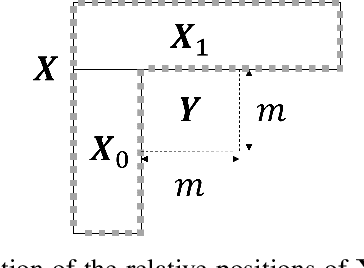



This paper describes a set of neural network architectures, called Prediction Neural Networks Set (PNNS), based on both fully-connected and convolutional neural networks, for intra image prediction. The choice of neural network for predicting a given image block depends on the block size, hence does not need to be signalled to the decoder. It is shown that, while fully-connected neural networks give good performance for small block sizes, convolutional neural networks provide better predictions in large blocks with complex textures. Thanks to the use of masks of random sizes during training, the neural networks of PNNS well adapt to the available context that may vary, depending on the position of the image block to be predicted. When integrating PNNS into a H.265 codec, PSNR-rate performance gains going from 1.46% to 5.20% are obtained. These gains are on average 0.99% larger than those of prior neural network based methods. Unlike the H.265 intra prediction modes, which are each specialized in predicting a specific texture, the proposed PNNS can model a large set of complex textures.
Autoencoder based image compression: can the learning be quantization independent?
Feb 23, 2018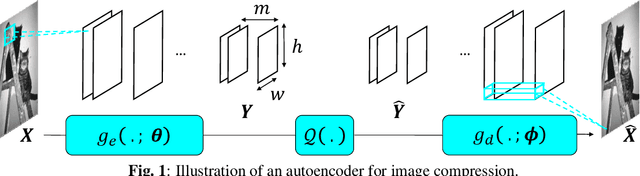
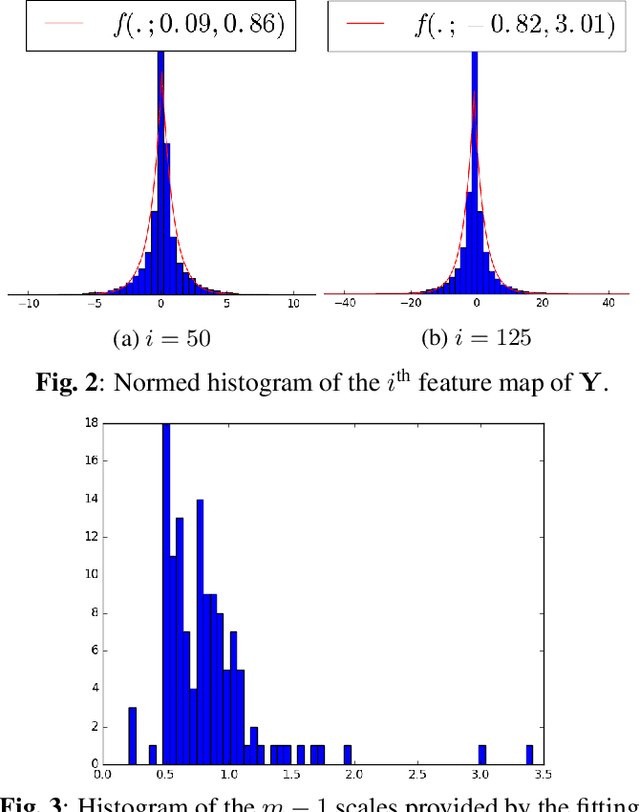

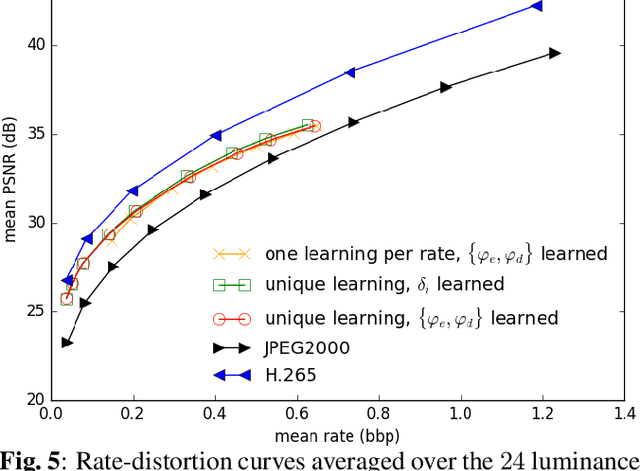
This paper explores the problem of learning transforms for image compression via autoencoders. Usually, the rate-distortion performances of image compression are tuned by varying the quantization step size. In the case of autoen-coders, this in principle would require learning one transform per rate-distortion point at a given quantization step size. Here, we show that comparable performances can be obtained with a unique learned transform. The different rate-distortion points are then reached by varying the quantization step size at test time. This approach saves a lot of training time.