 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High-Resolution Landscape Dataset for Concept-Based XAI With Application to Species Distribution Models
Apr 14, 2026Mapping the spatial distribution of species is essential for conservation policy and invasive species management. Species distribution models (SDMs) are the primary tools for this task, serving two purposes: achieving robust predictive performance while providing ecological insights into the driving factors of distribution. However, the increasing complexity of deep learning SDMs has made extracting these insights more challenging. To reconcile these objectives, we propose the first implementation of concept-based Explainable AI (XAI) for SDMs. We leverage the Robust TCAV (Testing with Concept Activation Vectors) methodology to quantify the influence of landscape concepts on model predictions. To enable this, we provide a new open-access landscape concept dataset derived from high-resolution multispectral and LiDAR drone imagery. It includes 653 patches across 15 distinct landscape concepts and 1,450 random reference patches, designed to suit a wide range of species. We demonstrate this approach through a case study of two aquatic insects, Plecoptera and Trichoptera, using two Convolutional Neural Networks and one Vision Transformer. Results show that concept-based XAI helps validate SDMs against expert knowledge while uncovering novel associations that generate new ecological hypotheses. Robust TCAV also provides landscape-level information, useful for policy-making and land management. Code and datasets are publicly available.
Beyond Mixtures and Products for Ensemble Aggregation: A Likelihood Perspective on Generalized Means
Mar 04, 2026Density aggregation is a central problem in machine learning, for instance when combining predictions from a Deep Ensemble. The choice of aggregation remains an open question with two commonly proposed approaches being linear pooling (probability averaging) and geometric pooling (logit averaging). In this work, we address this question by studying the normalized generalized mean of order $r \in \mathbb{R} \cup \{-\infty,+\infty\}$ through the lens of log-likelihood, the standard evaluation criterion in machine learning. This provides a unifying aggregation formalism and shows different optimal configurations for different situations. We show that the regime $r \in [0,1]$ is the only range ensuring systematic improvements relative to individual distributions, thereby providing a principled justification for the reliability and widespread practical use of linear ($r=1$) and geometric ($r=0$) pooling. In contrast, we show that aggregation rules with $r \notin [0,1]$ may fail to provide consistent gains with explicit counterexamples. Finally, we corroborate our theoretical findings with empirical evaluations using Deep Ensembles on image and text classification benchmarks.
Towards Understanding Steering Strength
Feb 02, 2026A popular approach to post-training control of large language models (LLMs) is the steering of intermediate latent representations. Namely, identify a well-chosen direction depending on the task at hand and perturbs representations along this direction at inference time. While many propositions exist to pick this direction, considerably less is understood about how to choose the magnitude of the move, whereas its importance is clear: too little and the intended behavior does not emerge, too much and the model's performance degrades beyond repair. In this work, we propose the first theoretical analysis of steering strength. We characterize its effect on next token probability, presence of a concept, and cross-entropy, deriving precise qualitative laws governing these quantities. Our analysis reveals surprising behaviors, including non-monotonic effects of steering strength. We validate our theoretical predictions empirically on eleven language models, ranging from a small GPT architecture to modern models.
When Are Two Scores Better Than One? Investigating Ensembles of Diffusion Models
Jan 16, 2026Diffusion models now generate high-quality, diverse samples, with an increasing focus on more powerful models. Although ensembling is a well-known way to improve supervised models, its application to unconditional score-based diffusion models remains largely unexplored. In this work we investigate whether it provides tangible benefits for generative modelling. We find that while ensembling the scores generally improves the score-matching loss and model likelihood, it fails to consistently enhance perceptual quality metrics such as FID on image datasets. We confirm this observation across a breadth of aggregation rules using Deep Ensembles, Monte Carlo Dropout, on CIFAR-10 and FFHQ. We attempt to explain this discrepancy by investigating possible explanations, such as the link between score estimation and image quality. We also look into tabular data through random forests, and find that one aggregation strategy outperforms the others. Finally, we provide theoretical insights into the summing of score models, which shed light not only on ensembling but also on several model composition techniques (e.g. guidance).
Feature Attribution from First Principles
May 30, 2025Feature attribution methods are a popular approach to explain the behavior of machine learning models. They assign importance scores to each input feature, quantifying their influence on the model's prediction. However, evaluating these methods empirically remains a significant challenge. To bypass this shortcoming, several prior works have proposed axiomatic frameworks that any feature attribution method should satisfy. In this work, we argue that such axioms are often too restrictive, and propose in response a new feature attribution framework, built from the ground up. Rather than imposing axioms, we start by defining attributions for the simplest possible models, i.e., indicator functions, and use these as building blocks for more complex models. We then show that one recovers several existing attribution methods, depending on the choice of atomic attribution. Subsequently, we derive closed-form expressions for attribution of deep ReLU networks, and take a step toward the optimization of evaluation metrics with respect to feature attributions.
GLEAMS: Bridging the Gap Between Local and Global Explanations
Aug 09, 2024



The explainability of machine learning algorithms is crucial, and numerous methods have emerged recently. Local, post-hoc methods assign an attribution score to each feature, indicating its importance for the prediction. However, these methods require recalculating explanations for each example. On the other side, while there exist global approaches they often produce explanations that are either overly simplistic and unreliable or excessively complex. To bridge this gap, we propose GLEAMS, a novel method that partitions the input space and learns an interpretable model within each sub-region, thereby providing both faithful local and global surrogates. We demonstrate GLEAMS' effectiveness on both synthetic and real-world data, highlighting its desirable properties and human-understandable insights.
CAM-Based Methods Can See through Walls
Apr 02, 2024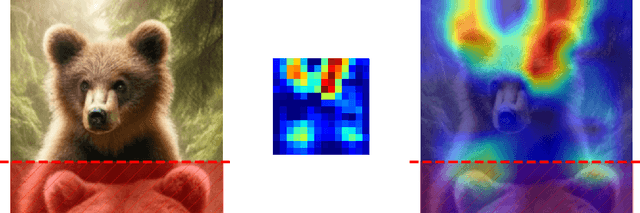
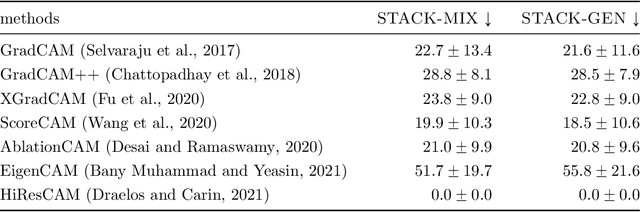
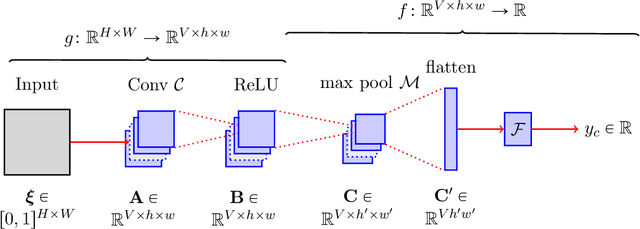

CAM-based methods are widely-used post-hoc interpretability method that produce a saliency map to explain the decision of an image classification model. The saliency map highlights the important areas of the image relevant to the prediction. In this paper, we show that most of these methods can incorrectly attribute an important score to parts of the image that the model cannot see. We show that this phenomenon occurs both theoretically and experimentally. On the theory side, we analyze the behavior of GradCAM on a simple masked CNN model at initialization. Experimentally, we train a VGG-like model constrained to not use the lower part of the image and nevertheless observe positive scores in the unseen part of the image. This behavior is evaluated quantitatively on two new datasets. We believe that this is problematic, potentially leading to mis-interpretation of the model's behavior.
Attention Meets Post-hoc Interpretability: A Mathematical Perspective
Feb 05, 2024
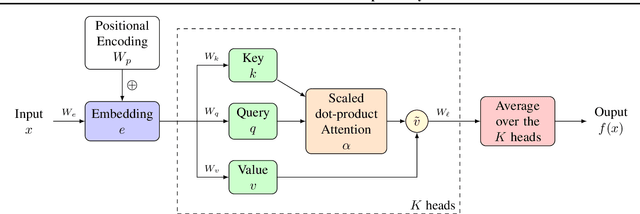
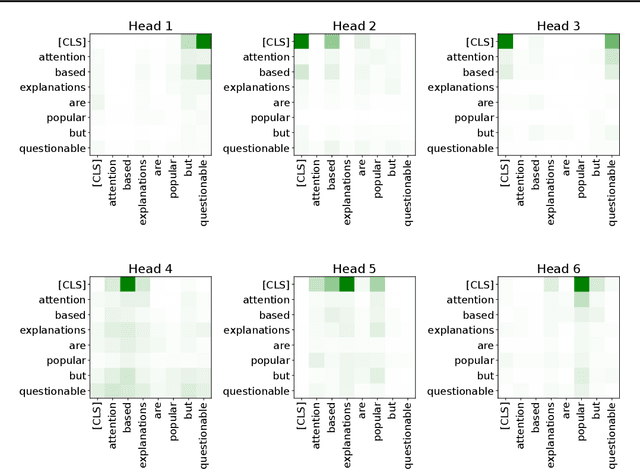
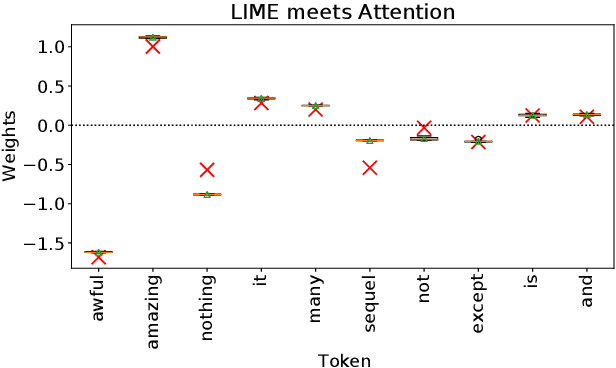
Attention-based architectures, in particular transformers, are at the heart of a technological revolution. Interestingly, in addition to helping obtain state-of-the-art results on a wide range of applications, the attention mechanism intrinsically provides meaningful insights on the internal behavior of the model. Can these insights be used as explanations? Debate rages on. In this paper, we mathematically study a simple attention-based architecture and pinpoint the differences between post-hoc and attention-based explanations. We show that they provide quite different results, and that, despite their limitations, post-hoc methods are capable of capturing more useful insights than merely examining the attention weights.
Are ensembles getting better all the time?
Nov 29, 2023Ensemble methods combine the predictions of several base models. We study whether or not including more models in an ensemble always improve its average performance. Such a question depends on the kind of ensemble considered, as well as the predictive metric chosen. We focus on situations where all members of the ensemble are a priori expected to perform as well, which is the case of several popular methods like random forests or deep ensembles. In this setting, we essentially show that ensembles are getting better all the time if, and only if, the considered loss function is convex. More precisely, in that case, the average loss of the ensemble is a decreasing function of the number of models. When the loss function is nonconvex, we show a series of results that can be summarised by the insight that ensembles of good models keep getting better, and ensembles of bad models keep getting worse. To this end, we prove a new result on the monotonicity of tail probabilities that may be of independent interest. We illustrate our results on a simple machine learning problem (diagnosing melanomas using neural nets).
Faithful and Robust Local Interpretability for Textual Predictions
Oct 30, 2023



Interpretability is essential for machine learning models to be trusted and deployed in critical domains. However, existing methods for interpreting text models are often complex, lack solid mathematical foundations, and their performance is not guaranteed. In this paper, we propose FRED (Faithful and Robust Explainer for textual Documents), a novel method for interpreting predictions over text. FRED identifies key words in a document that significantly impact the prediction when removed. We establish the reliability of FRED through formal definitions and theoretical analyses on interpretable classifiers. Additionally, our empirical evaluation against state-of-the-art methods demonstrates the effectiveness of FRED in providing insights into text models.