 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Steering Strength
Feb 02, 2026A popular approach to post-training control of large language models (LLMs) is the steering of intermediate latent representations. Namely, identify a well-chosen direction depending on the task at hand and perturbs representations along this direction at inference time. While many propositions exist to pick this direction, considerably less is understood about how to choose the magnitude of the move, whereas its importance is clear: too little and the intended behavior does not emerge, too much and the model's performance degrades beyond repair. In this work, we propose the first theoretical analysis of steering strength. We characterize its effect on next token probability, presence of a concept, and cross-entropy, deriving precise qualitative laws governing these quantities. Our analysis reveals surprising behaviors, including non-monotonic effects of steering strength. We validate our theoretical predictions empirically on eleven language models, ranging from a small GPT architecture to modern models.
Feature Attribution from First Principles
May 30, 2025Feature attribution methods are a popular approach to explain the behavior of machine learning models. They assign importance scores to each input feature, quantifying their influence on the model's prediction. However, evaluating these methods empirically remains a significant challenge. To bypass this shortcoming, several prior works have proposed axiomatic frameworks that any feature attribution method should satisfy. In this work, we argue that such axioms are often too restrictive, and propose in response a new feature attribution framework, built from the ground up. Rather than imposing axioms, we start by defining attributions for the simplest possible models, i.e., indicator functions, and use these as building blocks for more complex models. We then show that one recovers several existing attribution methods, depending on the choice of atomic attribution. Subsequently, we derive closed-form expressions for attribution of deep ReLU networks, and take a step toward the optimization of evaluation metrics with respect to feature attributions.
CAM-Based Methods Can See through Walls
Apr 02, 2024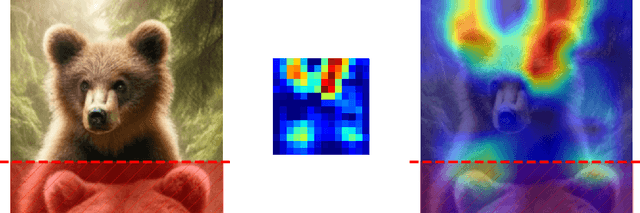
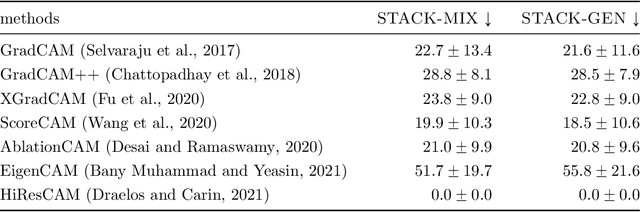
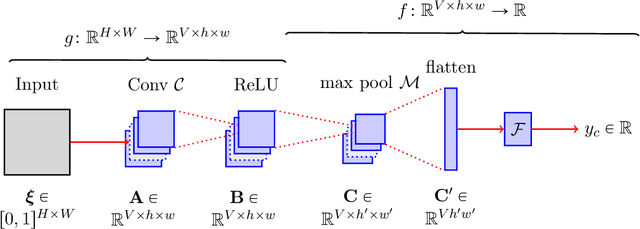

CAM-based methods are widely-used post-hoc interpretability method that produce a saliency map to explain the decision of an image classification model. The saliency map highlights the important areas of the image relevant to the prediction. In this paper, we show that most of these methods can incorrectly attribute an important score to parts of the image that the model cannot see. We show that this phenomenon occurs both theoretically and experimentally. On the theory side, we analyze the behavior of GradCAM on a simple masked CNN model at initialization. Experimentally, we train a VGG-like model constrained to not use the lower part of the image and nevertheless observe positive scores in the unseen part of the image. This behavior is evaluated quantitatively on two new datasets. We believe that this is problematic, potentially leading to mis-interpretation of the model's behavior.