 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEidos: Efficient, Imperceptible Adversarial 3D Point Clouds
May 23, 2024

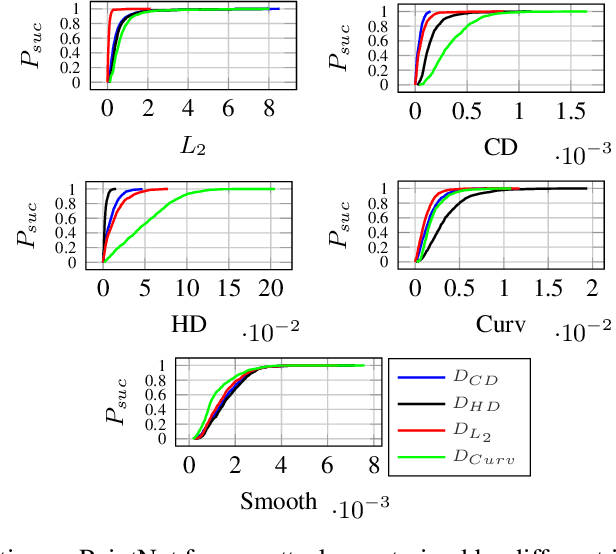

Classification of 3D point clouds is a challenging machine learning (ML) task with important real-world applications in a spectrum from autonomous driving and robot-assisted surgery to earth observation from low orbit. As with other ML tasks, classification models are notoriously brittle in the presence of adversarial attacks. These are rooted in imperceptible changes to inputs with the effect that a seemingly well-trained model ends up misclassifying the input. This paper adds to the understanding of adversarial attacks by presenting Eidos, a framework providing Efficient Imperceptible aDversarial attacks on 3D pOint cloudS. Eidos supports a diverse set of imperceptibility metrics. It employs an iterative, two-step procedure to identify optimal adversarial examples, thereby enabling a runtime-imperceptibility trade-off. We provide empirical evidence relative to several popular 3D point cloud classification models and several established 3D attack methods, showing Eidos' superiority with respect to efficiency as well as imperceptibility.
CA-Stream: Attention-based pooling for interpretable image recognition
Apr 23, 2024
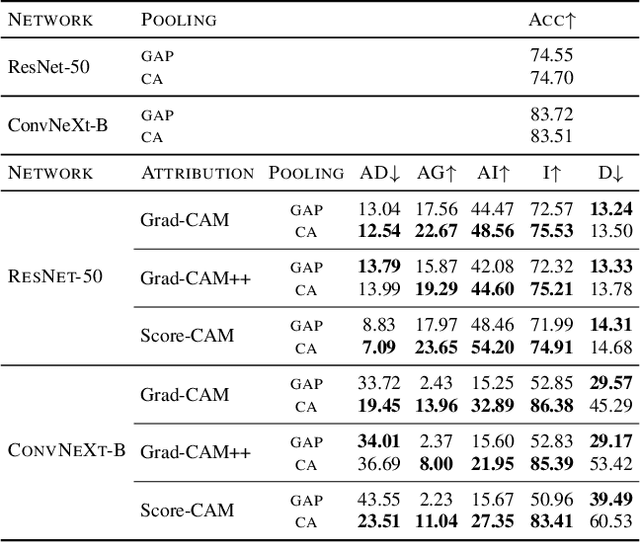

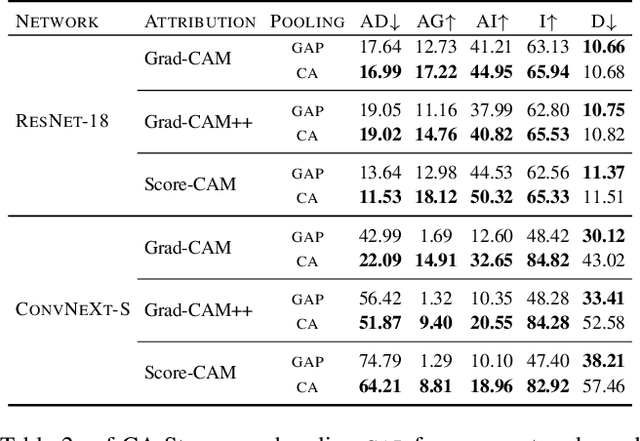
Explanations obtained from transformer-based architectures in the form of raw attention, can be seen as a class-agnostic saliency map. Additionally, attention-based pooling serves as a form of masking the in feature space. Motivated by this observation, we design an attention-based pooling mechanism intended to replace Global Average Pooling (GAP) at inference. This mechanism, called Cross-Attention Stream (CA-Stream), comprises a stream of cross attention blocks interacting with features at different network depths. CA-Stream enhances interpretability in models, while preserving recognition performance.
A Learning Paradigm for Interpretable Gradients
Apr 23, 2024


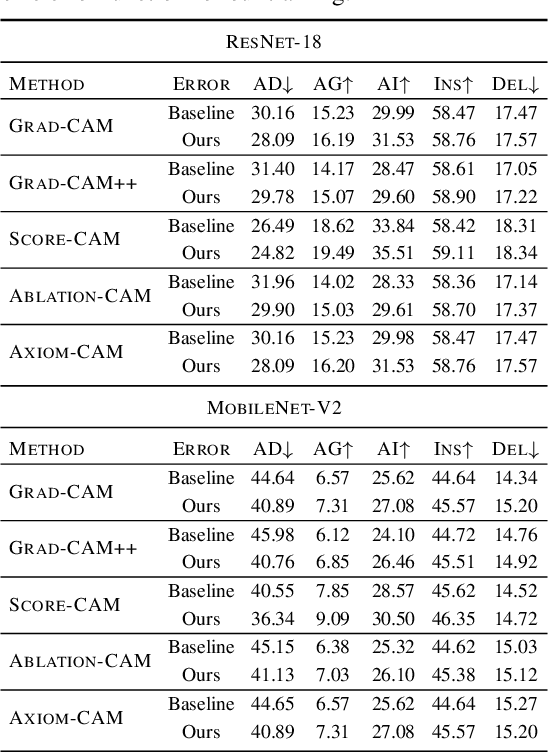
This paper studies interpretability of convolutional networks by means of saliency maps. Most approaches based on Class Activation Maps (CAM) combine information from fully connected layers and gradient through variants of backpropagation. However, it is well understood that gradients are noisy and alternatives like guided backpropagation have been proposed to obtain better visualization at inference. In this work, we present a novel training approach to improve the quality of gradients for interpretability. In particular, we introduce a regularization loss such that the gradient with respect to the input image obtained by standard backpropagation is similar to the gradient obtained by guided backpropagation. We find that the resulting gradient is qualitatively less noisy and improves quantitatively the interpretability properties of different networks, using several interpretability methods.
DP-Net: Learning Discriminative Parts for image recognition
Apr 23, 2024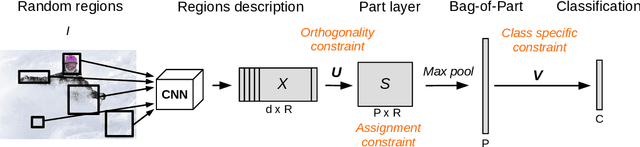
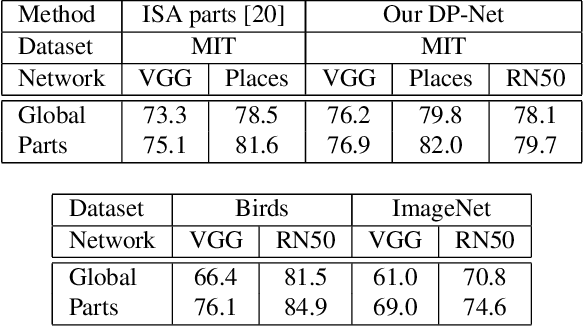

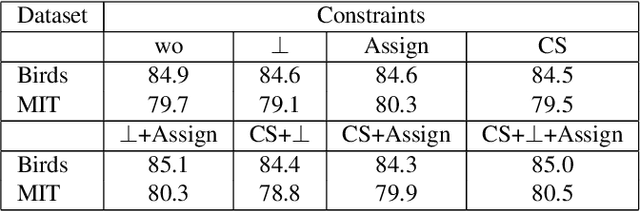
This paper presents Discriminative Part Network (DP-Net), a deep architecture with strong interpretation capabilities, which exploits a pretrained Convolutional Neural Network (CNN) combined with a part-based recognition module. This system learns and detects parts in the images that are discriminative among categories, without the need for fine-tuning the CNN, making it more scalable than other part-based models. While part-based approaches naturally offer interpretable representations, we propose explanations at image and category levels and introduce specific constraints on the part learning process to make them more discrimative.
CAM-Based Methods Can See through Walls
Apr 02, 2024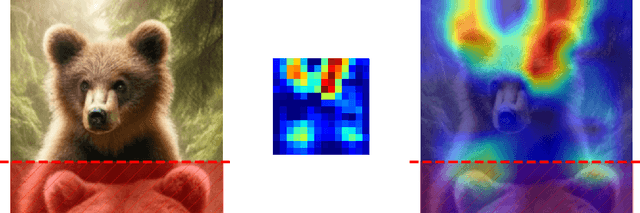
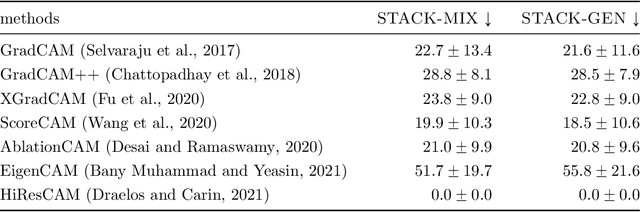
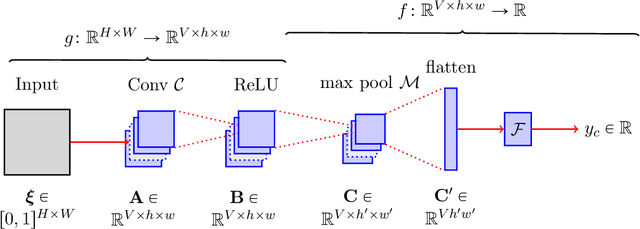

CAM-based methods are widely-used post-hoc interpretability method that produce a saliency map to explain the decision of an image classification model. The saliency map highlights the important areas of the image relevant to the prediction. In this paper, we show that most of these methods can incorrectly attribute an important score to parts of the image that the model cannot see. We show that this phenomenon occurs both theoretically and experimentally. On the theory side, we analyze the behavior of GradCAM on a simple masked CNN model at initialization. Experimentally, we train a VGG-like model constrained to not use the lower part of the image and nevertheless observe positive scores in the unseen part of the image. This behavior is evaluated quantitatively on two new datasets. We believe that this is problematic, potentially leading to mis-interpretation of the model's behavior.
Revisiting Transferable Adversarial Image Examples: Attack Categorization, Evaluation Guidelines, and New Insights
Oct 18, 2023



Transferable adversarial examples raise critical security concerns in real-world, black-box attack scenarios. However, in this work, we identify two main problems in common evaluation practices: (1) For attack transferability, lack of systematic, one-to-one attack comparison and fair hyperparameter settings. (2) For attack stealthiness, simply no comparisons. To address these problems, we establish new evaluation guidelines by (1) proposing a novel attack categorization strategy and conducting systematic and fair intra-category analyses on transferability, and (2) considering diverse imperceptibility metrics and finer-grained stealthiness characteristics from the perspective of attack traceback. To this end, we provide the first large-scale evaluation of transferable adversarial examples on ImageNet, involving 23 representative attacks against 9 representative defenses. Our evaluation leads to a number of new insights, including consensus-challenging ones: (1) Under a fair attack hyperparameter setting, one early attack method, DI, actually outperforms all the follow-up methods. (2) A state-of-the-art defense, DiffPure, actually gives a false sense of (white-box) security since it is indeed largely bypassed by our (black-box) transferable attacks. (3) Even when all attacks are bounded by the same $L_p$ norm, they lead to dramatically different stealthiness performance, which negatively correlates with their transferability performance. Overall, our work demonstrates that existing problematic evaluations have indeed caused misleading conclusions and missing points, and as a result, hindered the assessment of the actual progress in this field.
Opti-CAM: Optimizing saliency maps for interpretability
Jan 17, 2023



Methods based on class activation maps (CAM) provide a simple mechanism to interpret predictions of convolutional neural networks by using linear combinations of feature maps as saliency maps. By contrast, masking-based methods optimize a saliency map directly in the image space or learn it by training another network on additional data. In this work we introduce Opti-CAM, combining ideas from CAM-based and masking-based approaches. Our saliency map is a linear combination of feature maps, where weights are optimized per image such that the logit of the masked image for a given class is maximized. We also fix a fundamental flaw in two of the most common evaluation metrics of attribution methods. On several datasets, Opti-CAM largely outperforms other CAM-based approaches according to the most relevant classification metrics. We provide empirical evidence supporting that localization and classifier interpretability are not necessarily aligned.
Towards Good Practices in Evaluating Transfer Adversarial Attacks
Nov 17, 2022
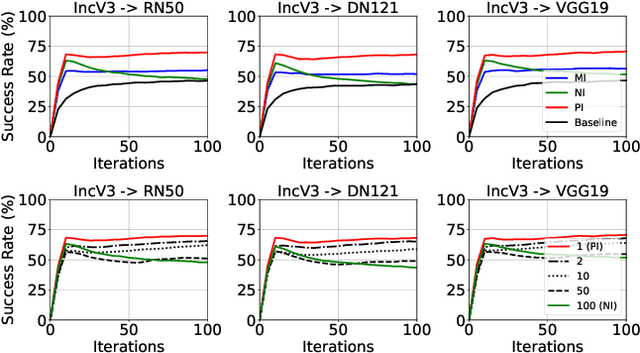

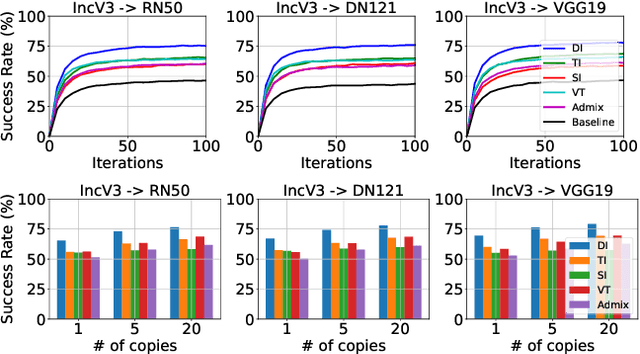
Transfer adversarial attacks raise critical security concerns in real-world, black-box scenarios. However, the actual progress of attack methods is difficult to assess due to two main limitations in existing evaluations. First, existing evaluations are unsystematic and sometimes unfair since new methods are often directly added to old ones without complete comparisons to similar methods. Second, existing evaluations mainly focus on transferability but overlook another key attack property: stealthiness. In this work, we design good practices to address these limitations. We first introduce a new attack categorization, which enables our systematic analyses of similar attacks in each specific category. Our analyses lead to new findings that complement or even challenge existing knowledge. Furthermore, we comprehensively evaluate 23 representative attacks against 9 defenses on ImageNet. We pay particular attention to stealthiness, by adopting diverse imperceptibility metrics and looking into new, finer-grained characteristics. Our evaluation reveals new important insights: 1) Transferability is highly contextual, and some white-box defenses may give a false sense of security since they are actually vulnerable to (black-box) transfer attacks; 2) All transfer attacks are less stealthy, and their stealthiness can vary dramatically under the same $L_{\infty}$ bound.
Unsupervised part learning for visual recognition
Apr 12, 2017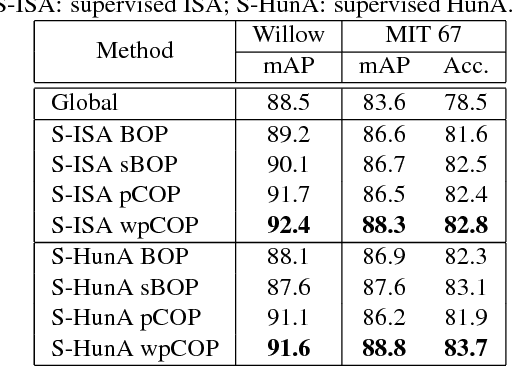

Part-based image classification aims at representing categories by small sets of learned discriminative parts, upon which an image representation is built. Considered as a promising avenue a decade ago, this direction has been neglected since the advent of deep neural networks. In this context, this paper brings two contributions: first, it shows that despite the recent success of end-to-end holistic models, explicit part learning can boosts classification performance. Second, this work proceeds one step further than recent part-based models (PBM), focusing on how to learn parts without using any labeled data. Instead of learning a set of parts per class, as generally done in the PBM literature, the proposed approach both constructs a partition of a given set of images into visually similar groups, and subsequently learn a set of discriminative parts per group in a fully unsupervised fashion. This strategy opens the door to the use of PBM in new applications for which the notion of image categories is irrelevant, such as instance-based image retrieval, for example. We experimentally show that our learned parts can help building efficient image representations, for classification as well as for indexing tasks, resulting in performance superior to holistic state-of-the art Deep Convolutional Neural Networks (DCNN) encoding.
Automatic discovery of discriminative parts as a quadratic assignment problem
Nov 14, 2016

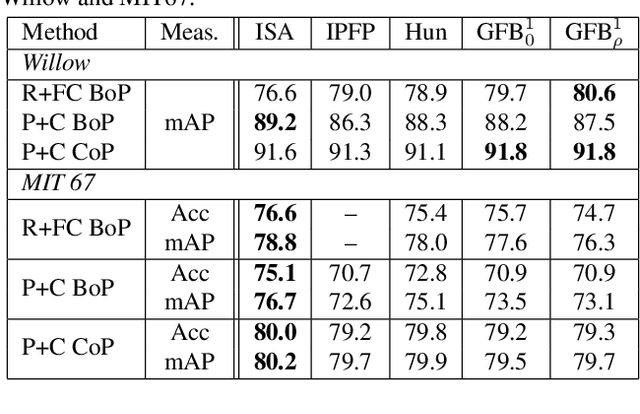

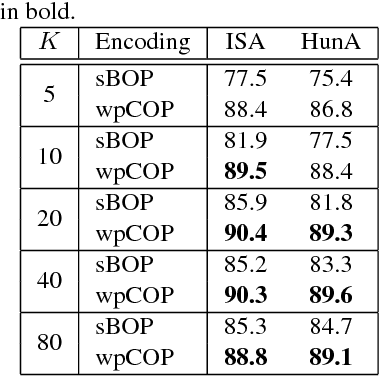
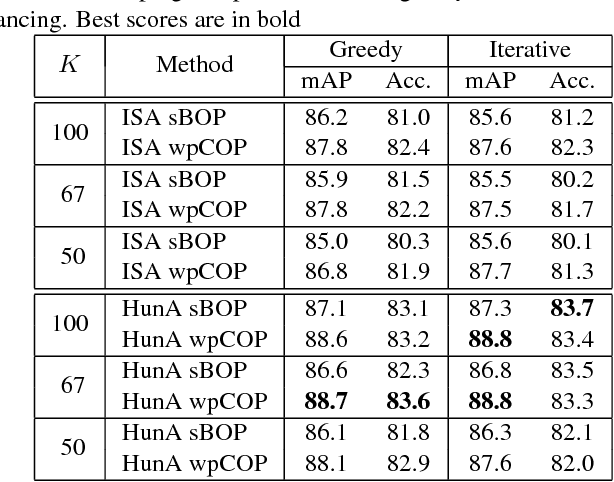
Part-based image classification consists in representing categories by small sets of discriminative parts upon which a representation of the images is built. This paper addresses the question of how to automatically learn such parts from a set of labeled training images. The training of parts is cast as a quadratic assignment problem in which optimal correspondences between image regions and parts are automatically learned. The paper analyses different assignment strategies and thoroughly evaluates them on two public datasets: Willow actions and MIT 67 scenes. State-of-the art results are obtained on these datasets.