 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA-Stream: Attention-based pooling for interpretable image recognition
Apr 23, 2024
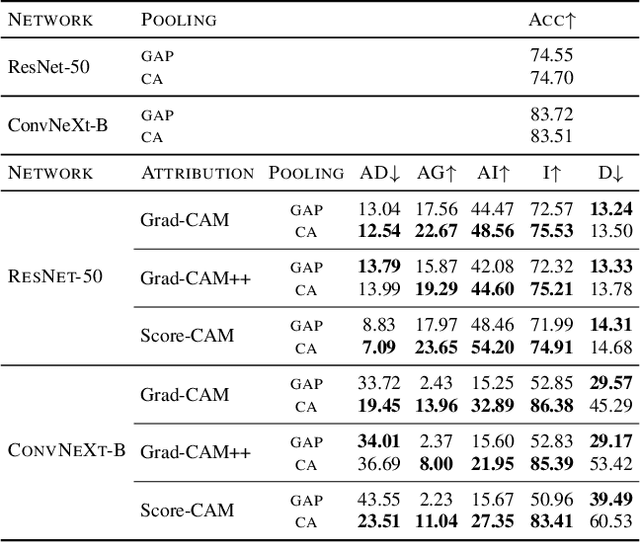

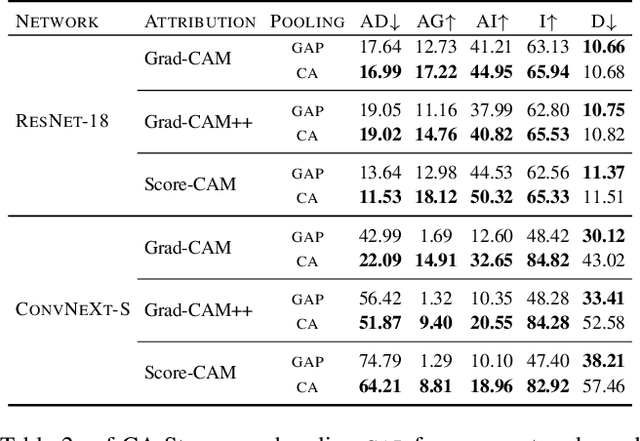
Explanations obtained from transformer-based architectures in the form of raw attention, can be seen as a class-agnostic saliency map. Additionally, attention-based pooling serves as a form of masking the in feature space. Motivated by this observation, we design an attention-based pooling mechanism intended to replace Global Average Pooling (GAP) at inference. This mechanism, called Cross-Attention Stream (CA-Stream), comprises a stream of cross attention blocks interacting with features at different network depths. CA-Stream enhances interpretability in models, while preserving recognition performance.
DP-Net: Learning Discriminative Parts for image recognition
Apr 23, 2024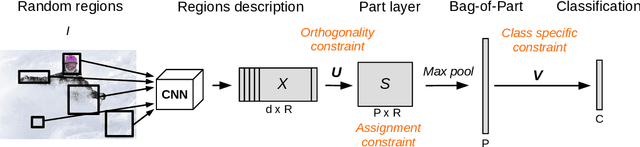
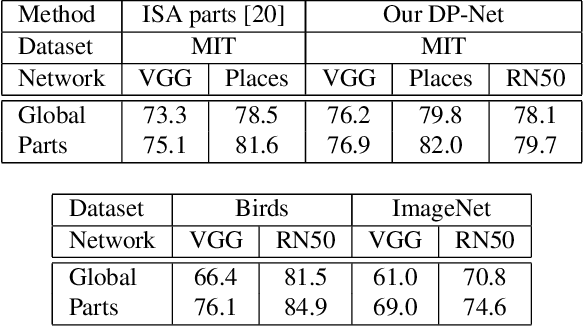

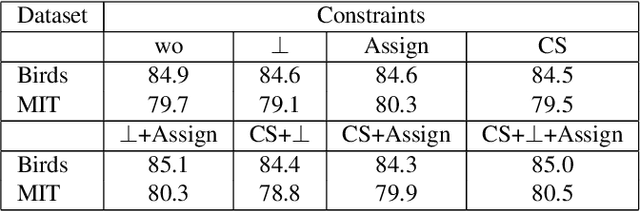
This paper presents Discriminative Part Network (DP-Net), a deep architecture with strong interpretation capabilities, which exploits a pretrained Convolutional Neural Network (CNN) combined with a part-based recognition module. This system learns and detects parts in the images that are discriminative among categories, without the need for fine-tuning the CNN, making it more scalable than other part-based models. While part-based approaches naturally offer interpretable representations, we propose explanations at image and category levels and introduce specific constraints on the part learning process to make them more discrimative.
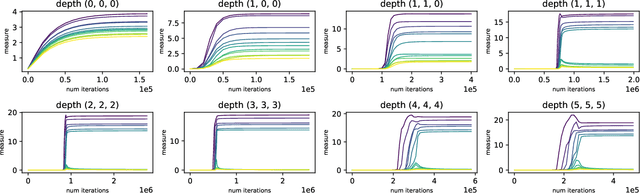
Implicit Regularization with Polynomial Growth in Deep Tensor Factorization
Jul 18, 2022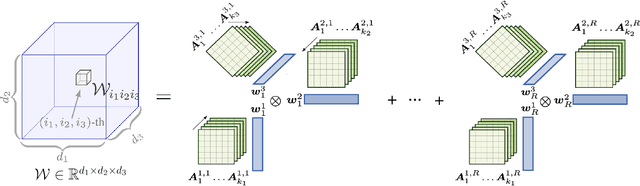
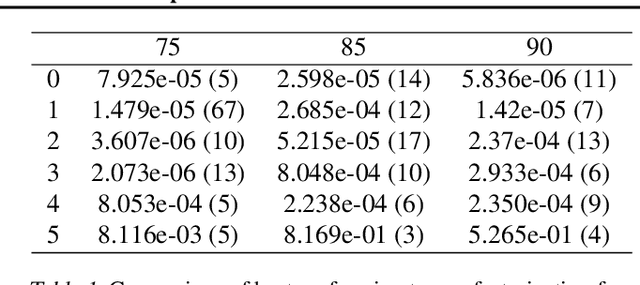
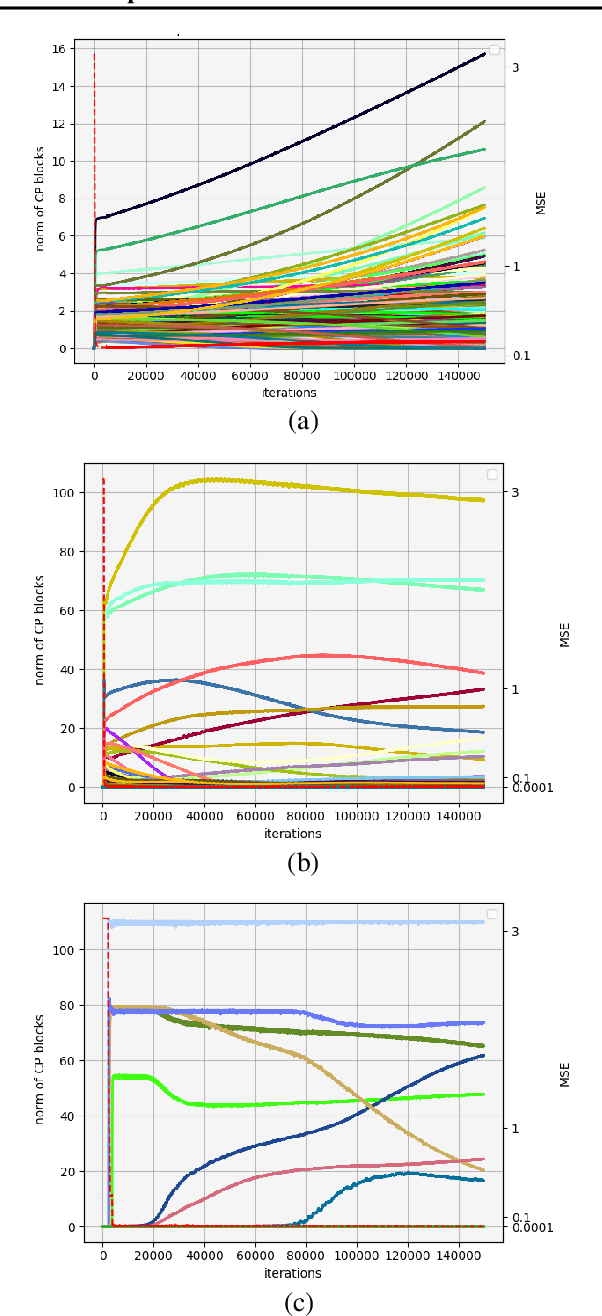
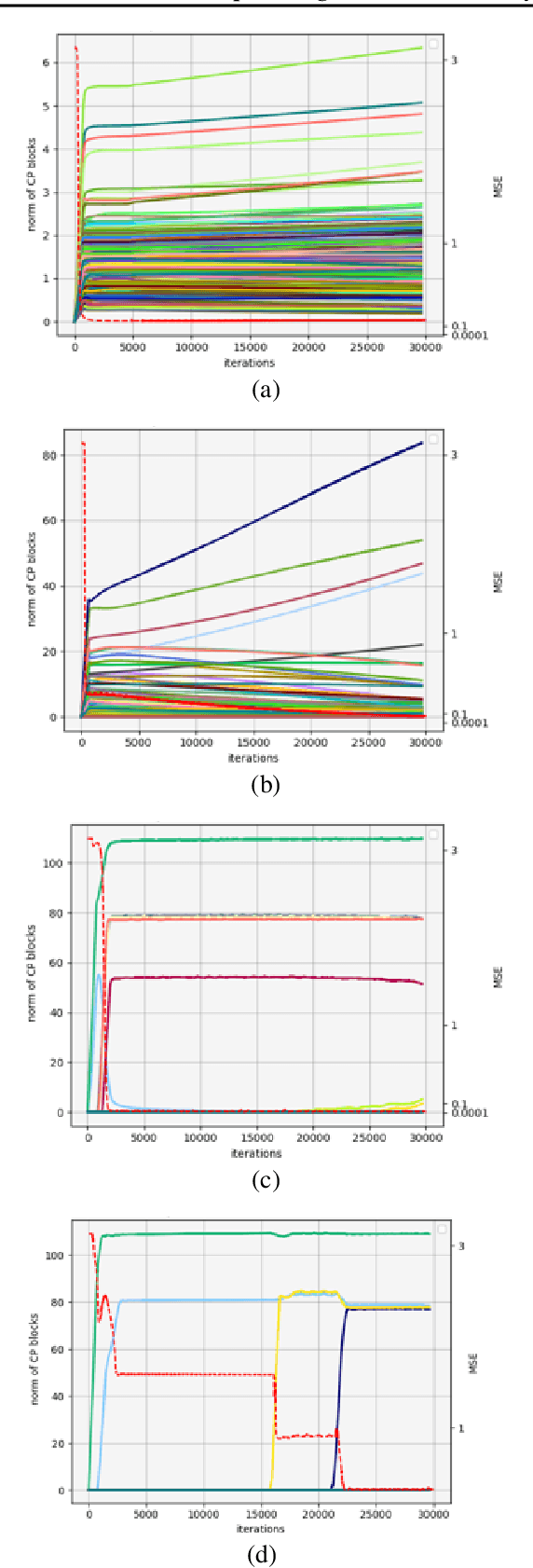
We study the implicit regularization effects of deep learning in tensor factorization. While implicit regularization in deep matrix and 'shallow' tensor factorization via linear and certain type of non-linear neural networks promotes low-rank solutions with at most quadratic growth, we show that its effect in deep tensor factorization grows polynomially with the depth of the network. This provides a remarkably faithful description of the observed experimental behaviour. Using numerical experiments, we demonstrate the benefits of this implicit regularization in yielding a more accurate estimation and better convergence properties.
* Accepted to ICML 2022
Implicit Regularization in Deep Tensor Factorization
May 04, 2021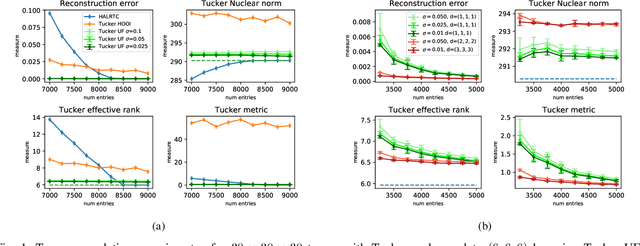
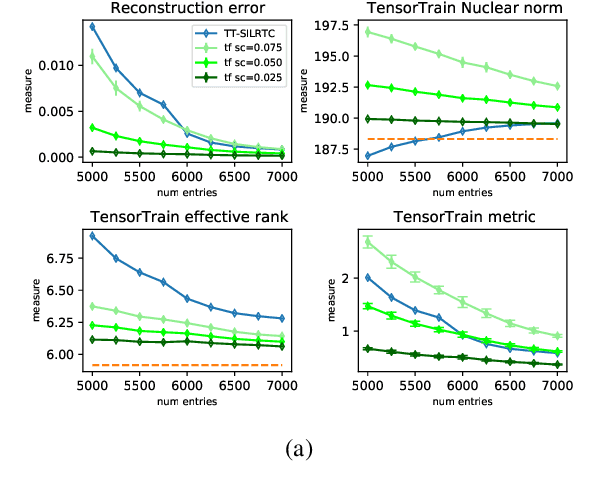
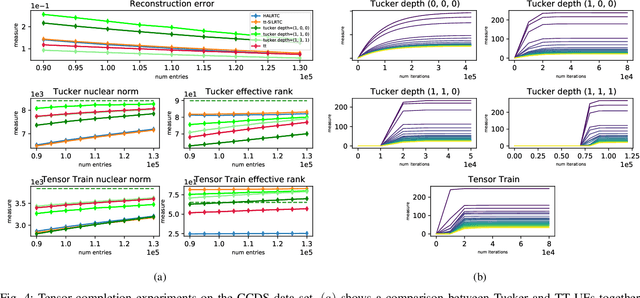
Attempts of studying implicit regularization associated to gradient descent (GD) have identified matrix completion as a suitable test-bed. Late findings suggest that this phenomenon cannot be phrased as a minimization-norm problem, implying that a paradigm shift is required and that dynamics has to be taken into account. In the present work we address the more general setup of tensor completion by leveraging two popularized tensor factorization, namely Tucker and TensorTrain (TT). We track relevant quantities such as tensor nuclear norm, effective rank, generalized singular values and we introduce deep Tucker and TT unconstrained factorization to deal with the completion task. Experiments on both synthetic and real data show that gradient descent promotes solution with low-rank, and validate the conjecture saying that the phenomenon has to be addressed from a dynamical perspective.
An AI-powered blood test to detect cancer using nanoDSF
Aug 08, 2020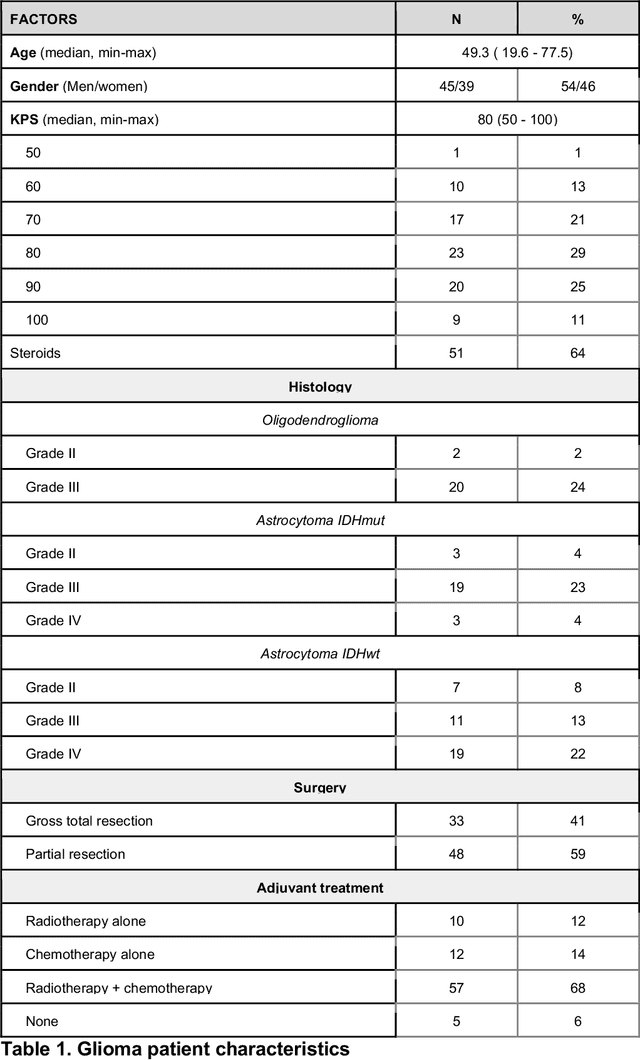
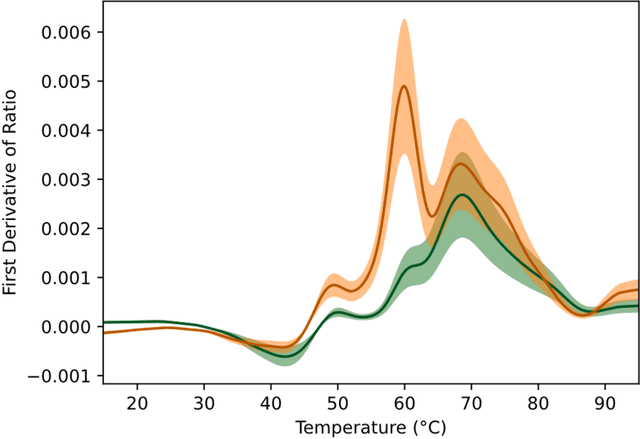
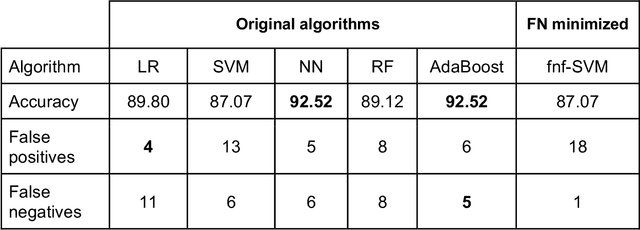
We describe a novel cancer diagnostic method based on plasma denaturation profiles obtained by a non-conventional use of Differential Scanning Fluorimetry. We show that 84 glioma patients and 63 healthy controls can be automatically classified using denaturation profiles with the help of machine learning algorithms with 92% accuracy. Proposed high throughput workflow can be applied to any type of cancer and could become a powerful pan-cancer diagnostic and monitoring tool from a simple blood test.
Partial Trace Regression and Low-Rank Kraus Decomposition
Jul 02, 2020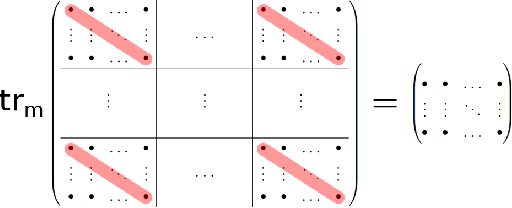

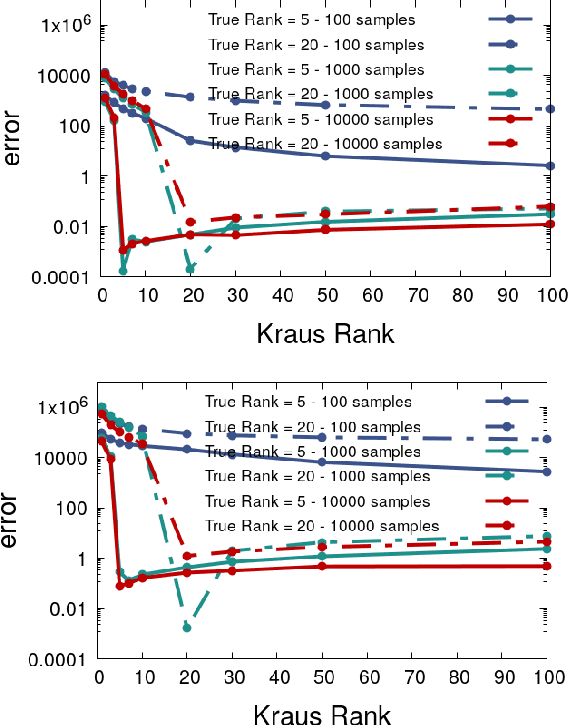
The trace regression model, a direct extension of the well-studied linear regression model, allows one to map matrices to real-valued outputs. We here introduce an even more general model, namely the partial-trace regression model, a family of linear mappings from matrix-valued inputs to matrix-valued outputs; this model subsumes the trace regression model and thus the linear regression model. Borrowing tools from quantum information theory, where partial trace operators have been extensively studied, we propose a framework for learning partial trace regression models from data by taking advantage of the so-called low-rank Kraus representation of completely positive maps. We show the relevance of our framework with synthetic and real-world experiments conducted for both i) matrix-to-matrix regression and ii) positive semidefinite matrix completion, two tasks which can be formulated as partial trace regression problems.
Mapping individual differences in cortical architecture using multi-view representation learning
Apr 01, 2020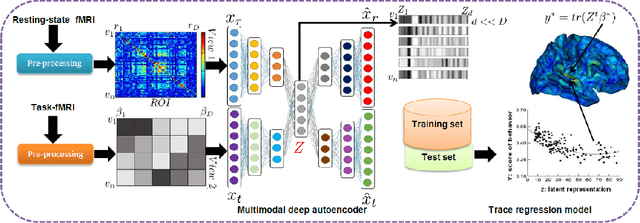
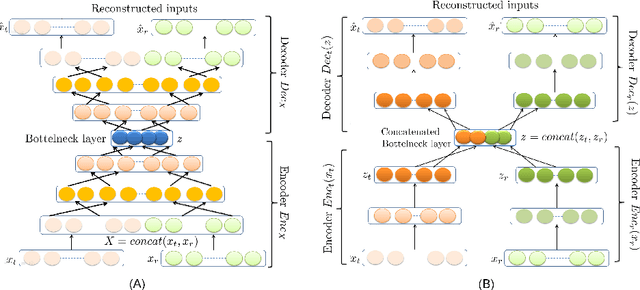
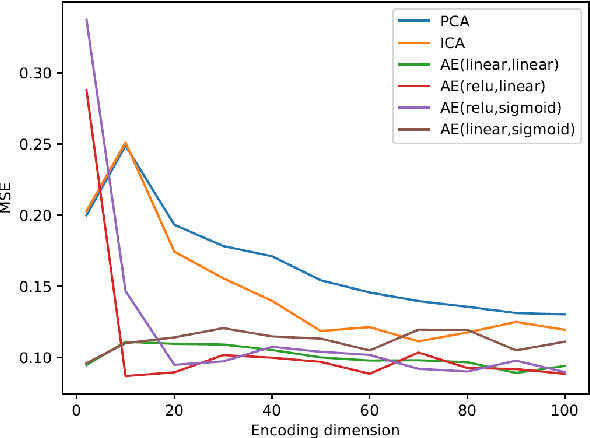
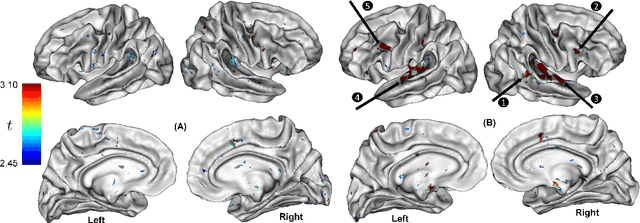
In neuroscience, understanding inter-individual differences has recently emerged as a major challenge, for which functional magnetic resonance imaging (fMRI) has proven invaluable. For this, neuroscientists rely on basic methods such as univariate linear correlations between single brain features and a score that quantifies either the severity of a disease or the subject's performance in a cognitive task. However, to this date, task-fMRI and resting-state fMRI have been exploited separately for this question, because of the lack of methods to effectively combine them. In this paper, we introduce a novel machine learning method which allows combining the activation-and connectivity-based information respectively measured through these two fMRI protocols to identify markers of individual differences in the functional organization of the brain. It combines a multi-view deep autoencoder which is designed to fuse the two fMRI modalities into a joint representation space within which a predictive model is trained to guess a scalar score that characterizes the patient. Our experimental results demonstrate the ability of the proposed method to outperform competitive approaches and to produce interpretable and biologically plausible results.
Deep Networks with Adaptive Nyström Approximation
Nov 29, 2019


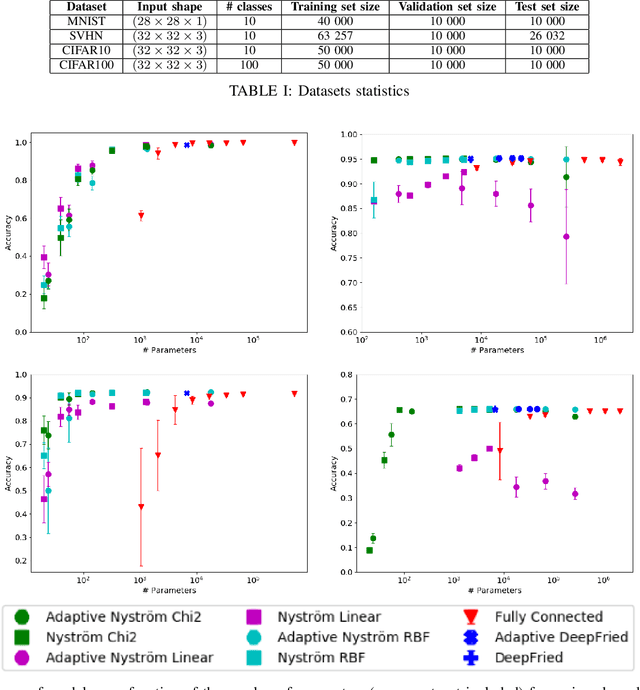
Recent work has focused on combining kernel methods and deep learning to exploit the best of the two approaches. Here, we introduce a new architecture of neural networks in which we replace the top dense layers of standard convolutional architectures with an approximation of a kernel function by relying on the Nystr{\"o}m approximation. Our approach is easy and highly flexible. It is compatible with any kernel function and it allows exploiting multiple kernels. We show that our architecture has the same performance than standard architecture on datasets like SVHN and CIFAR100. One benefit of the method lies in its limited number of learnable parameters which makes it particularly suited for small training set sizes, e.g. from 5 to 20 samples per class.
Majority Vote of Diverse Classifiers for Late Fusion
Jun 19, 2014
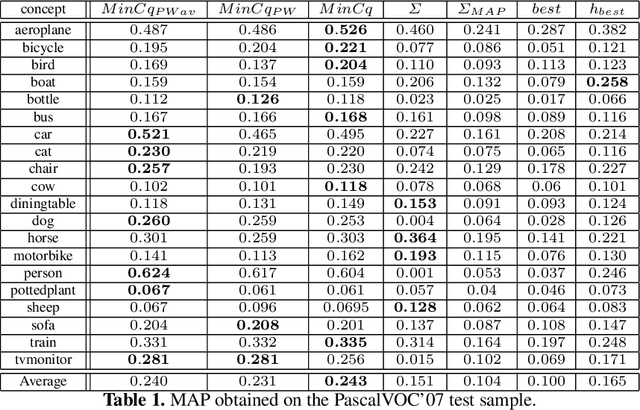
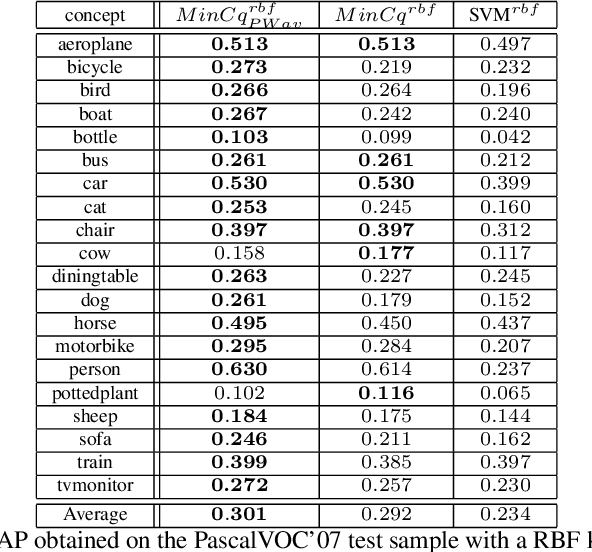
In the past few years, a lot of attention has been devoted to multimedia indexing by fusing multimodal informations. Two kinds of fusion schemes are generally considered: The early fusion and the late fusion. We focus on late classifier fusion, where one combines the scores of each modality at the decision level. To tackle this problem, we investigate a recent and elegant well-founded quadratic program named MinCq coming from the machine learning PAC-Bayesian theory. MinCq looks for the weighted combination, over a set of real-valued functions seen as voters, leading to the lowest misclassification rate, while maximizing the voters' diversity. We propose an extension of MinCq tailored to multimedia indexing. Our method is based on an order-preserving pairwise loss adapted to ranking that allows us to improve Mean Averaged Precision measure while taking into account the diversity of the voters that we want to fuse. We provide evidence that this method is naturally adapted to late fusion procedures and confirm the good behavior of our approach on the challenging PASCAL VOC'07 benchmark.
PAC-Bayesian Majority Vote for Late Classifier Fusion
Jul 04, 2012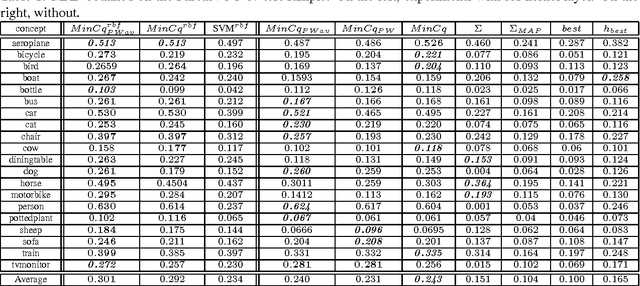
A lot of attention has been devoted to multimedia indexing over the past few years. In the literature, we often consider two kinds of fusion schemes: The early fusion and the late fusion. In this paper we focus on late classifier fusion, where one combines the scores of each modality at the decision level. To tackle this problem, we investigate a recent and elegant well-founded quadratic program named MinCq coming from the Machine Learning PAC-Bayes theory. MinCq looks for the weighted combination, over a set of real-valued functions seen as voters, leading to the lowest misclassification rate, while making use of the voters' diversity. We provide evidence that this method is naturally adapted to late fusion procedure. We propose an extension of MinCq by adding an order- preserving pairwise loss for ranking, helping to improve Mean Averaged Precision measure. We confirm the good behavior of the MinCq-based fusion approaches with experiments on a real image benchmark.