 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODIS: Multi-Omics Data Integration for Small and Unpaired Datasets
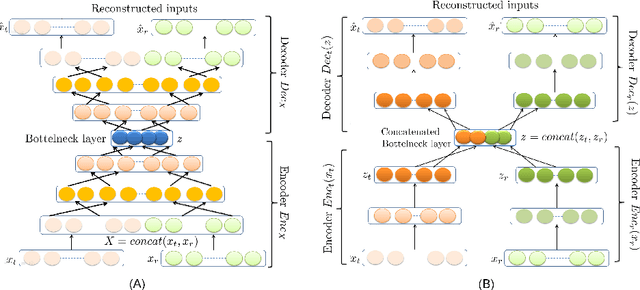
Mar 24, 2025A key challenge today lies in the ability to efficiently handle multi-omics data since such multimodal data may provide a more comprehensive overview of the underlying processes in a system. Yet it comes with challenges: multi-omics data are most often unpaired and only partially labeled, moreover only small amounts of data are available in some situation such as rare diseases. We propose MODIS which stands for Multi-Omics Data Integration for Small and unpaired datasets, a semi supervised approach to account for these particular settings. MODIS learns a probabilistic coupling of heterogeneous data modalities and learns a shared latent space where modalities are aligned. We rely on artificial data to build controlled experiments to explore how much supervision is needed for an accurate alignment of modalities, and how our approach enables dealing with new conditions for which few data are available. The code is available athttps://github.com/VILLOUTREIXLab/MODIS.
Hierarchical novel class discovery for single-cell transcriptomic profiles
Sep 09, 2024



One of the major challenges arising from single-cell transcriptomics experiments is the question of how to annotate the associated single-cell transcriptomic profiles. Because of the large size and the high dimensionality of the data, automated methods for annotation are needed. We focus here on datasets obtained in the context of developmental biology, where the differentiation process leads to a hierarchical structure. We consider a frequent setting where both labeled and unlabeled data are available at training time, but the sets of the labels of labeled data on one side and of the unlabeled data on the other side, are disjoint. It is an instance of the Novel Class Discovery problem. The goal is to achieve two objectives, clustering the data and mapping the clusters with labels. We propose extensions of k-Means and GMM clustering methods for solving the problem and report comparative results on artificial and experimental transcriptomic datasets. Our approaches take advantage of the hierarchical nature of the data.
DP-Net: Learning Discriminative Parts for image recognition
Apr 23, 2024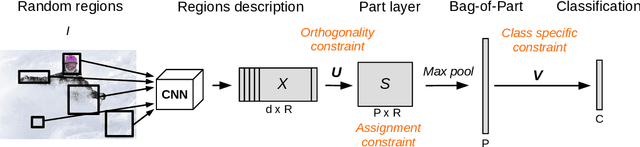
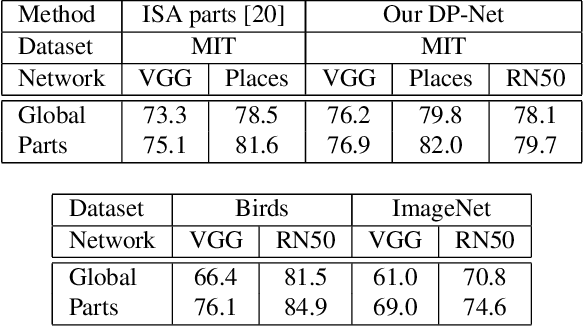

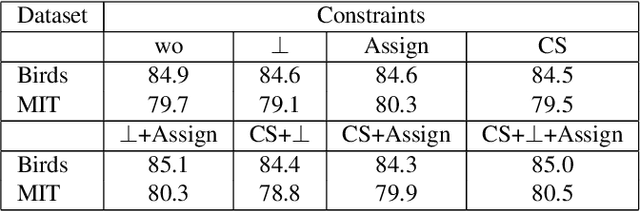
This paper presents Discriminative Part Network (DP-Net), a deep architecture with strong interpretation capabilities, which exploits a pretrained Convolutional Neural Network (CNN) combined with a part-based recognition module. This system learns and detects parts in the images that are discriminative among categories, without the need for fine-tuning the CNN, making it more scalable than other part-based models. While part-based approaches naturally offer interpretable representations, we propose explanations at image and category levels and introduce specific constraints on the part learning process to make them more discrimative.
Implicit Regularization with Polynomial Growth in Deep Tensor Factorization
Jul 18, 2022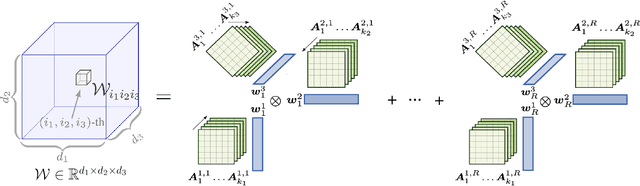
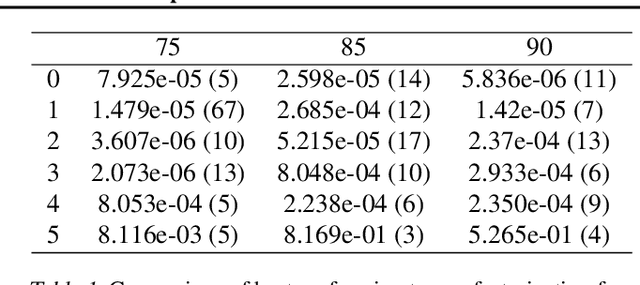
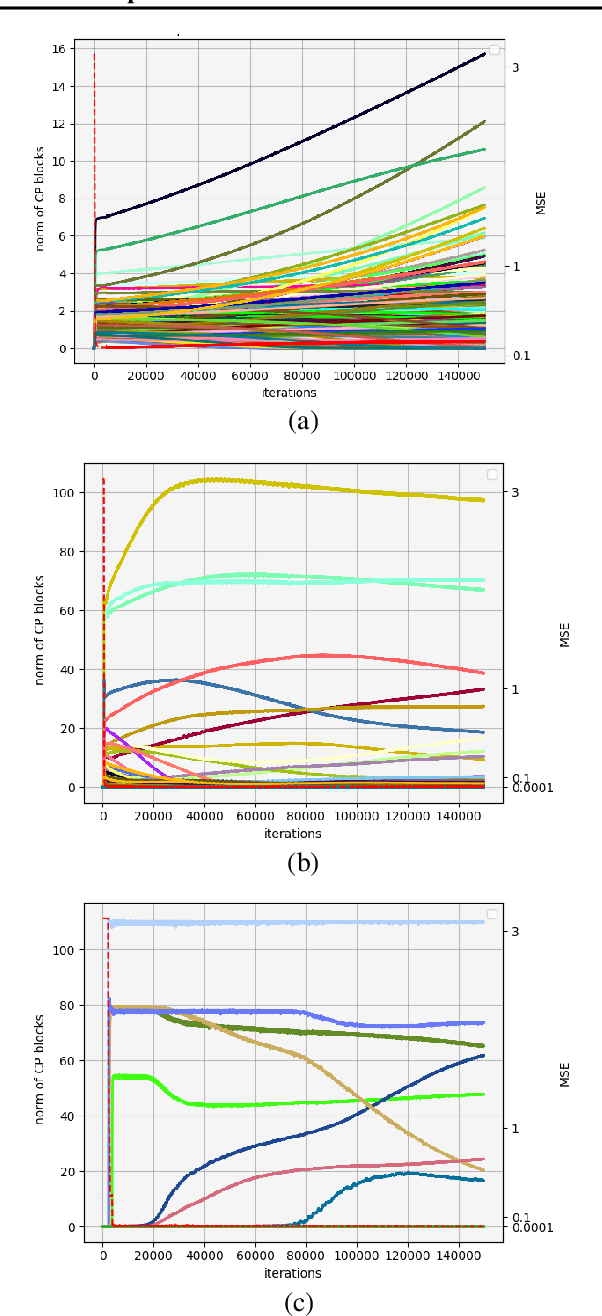
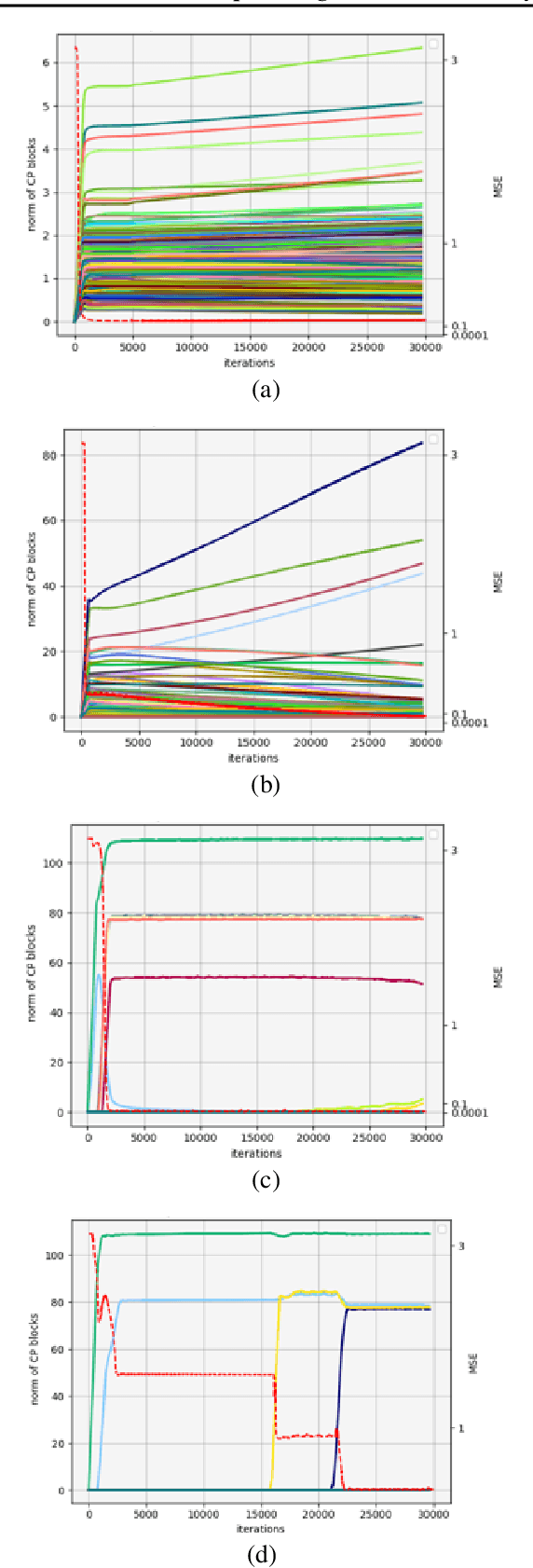
We study the implicit regularization effects of deep learning in tensor factorization. While implicit regularization in deep matrix and 'shallow' tensor factorization via linear and certain type of non-linear neural networks promotes low-rank solutions with at most quadratic growth, we show that its effect in deep tensor factorization grows polynomially with the depth of the network. This provides a remarkably faithful description of the observed experimental behaviour. Using numerical experiments, we demonstrate the benefits of this implicit regularization in yielding a more accurate estimation and better convergence properties.
* Accepted to ICML 2022
Implicit Regularization in Deep Tensor Factorization
May 04, 2021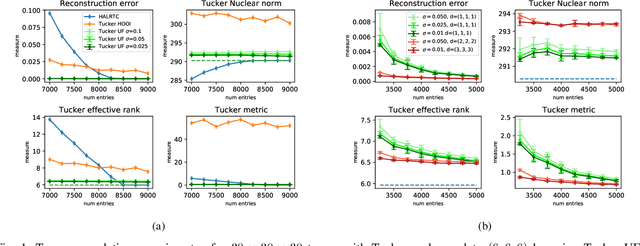
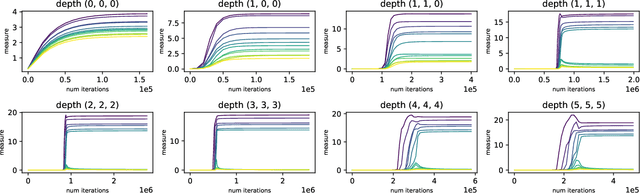
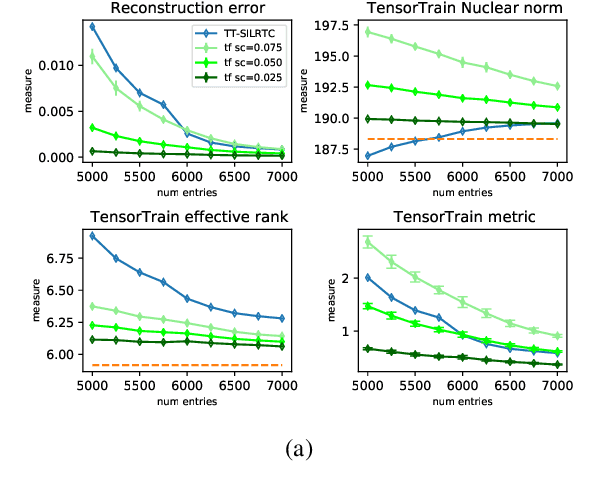
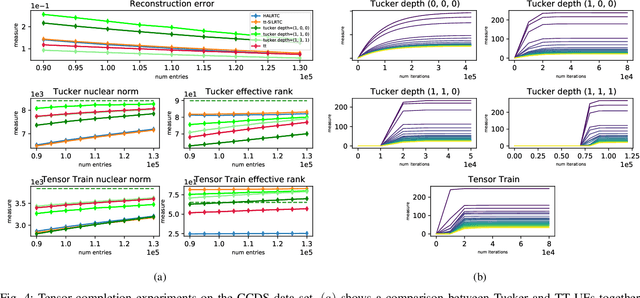
Attempts of studying implicit regularization associated to gradient descent (GD) have identified matrix completion as a suitable test-bed. Late findings suggest that this phenomenon cannot be phrased as a minimization-norm problem, implying that a paradigm shift is required and that dynamics has to be taken into account. In the present work we address the more general setup of tensor completion by leveraging two popularized tensor factorization, namely Tucker and TensorTrain (TT). We track relevant quantities such as tensor nuclear norm, effective rank, generalized singular values and we introduce deep Tucker and TT unconstrained factorization to deal with the completion task. Experiments on both synthetic and real data show that gradient descent promotes solution with low-rank, and validate the conjecture saying that the phenomenon has to be addressed from a dynamical perspective.
Mapping individual differences in cortical architecture using multi-view representation learning
Apr 01, 2020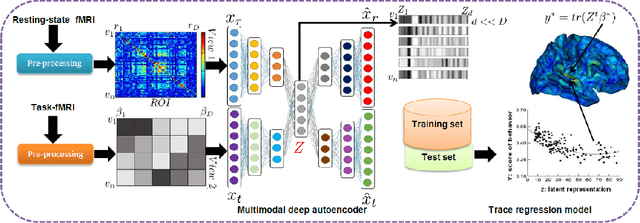
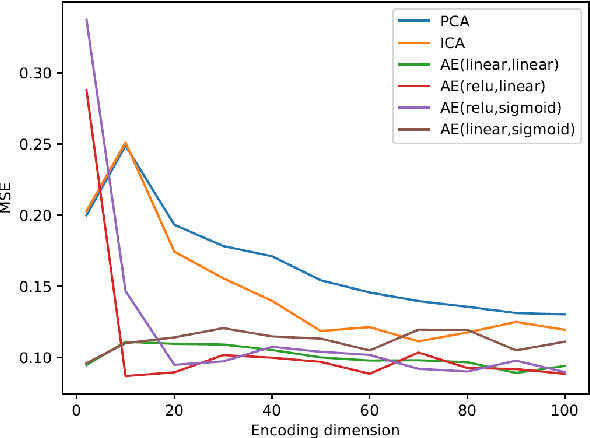
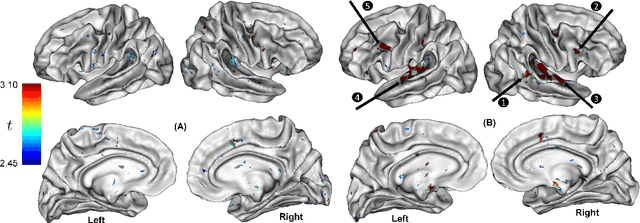
In neuroscience, understanding inter-individual differences has recently emerged as a major challenge, for which functional magnetic resonance imaging (fMRI) has proven invaluable. For this, neuroscientists rely on basic methods such as univariate linear correlations between single brain features and a score that quantifies either the severity of a disease or the subject's performance in a cognitive task. However, to this date, task-fMRI and resting-state fMRI have been exploited separately for this question, because of the lack of methods to effectively combine them. In this paper, we introduce a novel machine learning method which allows combining the activation-and connectivity-based information respectively measured through these two fMRI protocols to identify markers of individual differences in the functional organization of the brain. It combines a multi-view deep autoencoder which is designed to fuse the two fMRI modalities into a joint representation space within which a predictive model is trained to guess a scalar score that characterizes the patient. Our experimental results demonstrate the ability of the proposed method to outperform competitive approaches and to produce interpretable and biologically plausible results.
Deep Networks with Adaptive Nyström Approximation
Nov 29, 2019


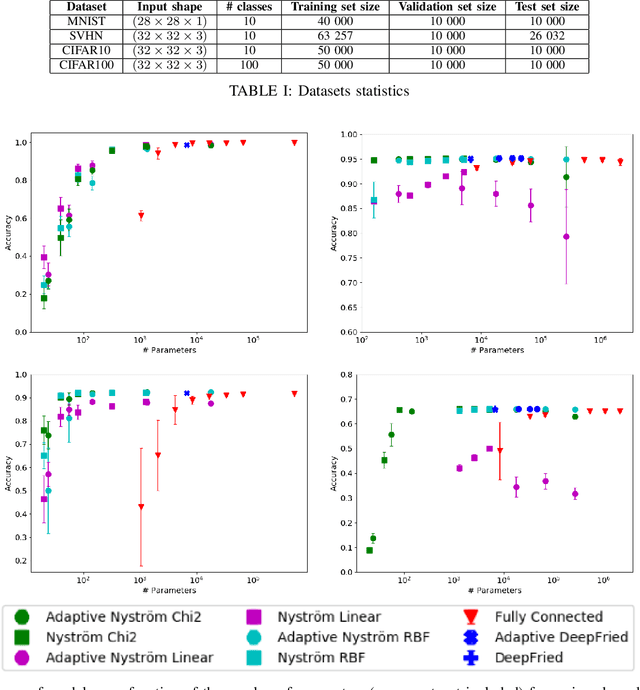
Recent work has focused on combining kernel methods and deep learning to exploit the best of the two approaches. Here, we introduce a new architecture of neural networks in which we replace the top dense layers of standard convolutional architectures with an approximation of a kernel function by relying on the Nystr{\"o}m approximation. Our approach is easy and highly flexible. It is compatible with any kernel function and it allows exploiting multiple kernels. We show that our architecture has the same performance than standard architecture on datasets like SVHN and CIFAR100. One benefit of the method lies in its limited number of learnable parameters which makes it particularly suited for small training set sizes, e.g. from 5 to 20 samples per class.
Unsupervised Object Segmentation by Redrawing
May 27, 2019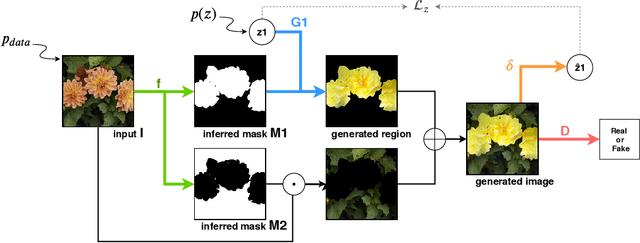



Object segmentation is a crucial problem that is usually solved by using supervised learning approaches over very large datasets composed of both images and corresponding object masks. Since the masks have to be provided at pixel level, building such a dataset for any new domain can be very costly. We present ReDO, a new model able to extract objects from images without any annotation in an unsupervised way. It relies on the idea that it should be possible to change the textures or colors of the objects without changing the overall distribution of the dataset. Following this assumption, our approach is based on an adversarial architecture where the generator is guided by an input sample: given an image, it extracts the object mask, then redraws a new object at the same location. The generator is controlled by a discriminator that ensures that the distribution of generated images is aligned to the original one. We experiment with this method on different datasets and demonstrate the good quality of extracted masks.
Multi-View Data Generation Without View Supervision
Nov 01, 2017

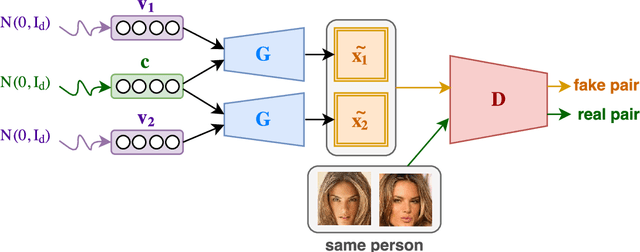

The development of high-dimensional generative models has recently gained a great surge of interest with the introduction of variational auto-encoders and generative adversarial neural networks. Different variants have been proposed where the underlying latent space is structured, for example, based on attributes describing the data to generate. We focus on a particular problem where one aims at generating samples corresponding to a number of objects under various views. We assume that the distribution of the data is driven by two independent latent factors: the content, which represents the intrinsic features of an object, and the view, which stands for the settings of a particular observation of that object. Therefore, we propose a generative model and a conditional variant built on such a disentangled latent space. This approach allows us to generate realistic samples corresponding to various objects in a high variety of views. Unlike many multi-view approaches, our model doesn't need any supervision on the views but only on the content. Compared to other conditional generation approaches that are mostly based on binary or categorical attributes, we make no such assumption about the factors of variations. Our model can be used on problems with a huge, potentially infinite, number of categories. We experiment it on four image datasets on which we demonstrate the effectiveness of the model and its ability to generalize.
Sequential Cost-Sensitive Feature Acquisition
Jul 13, 2016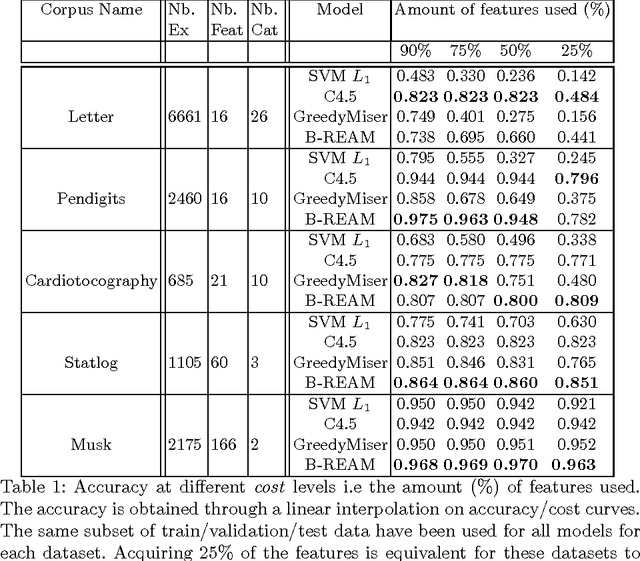
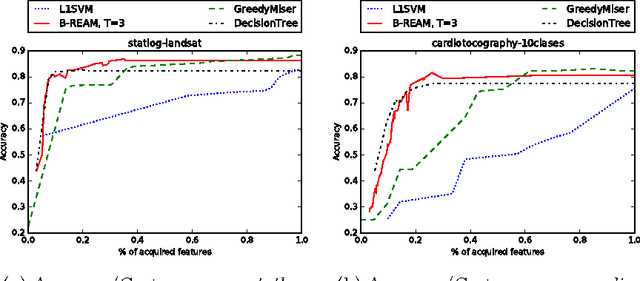
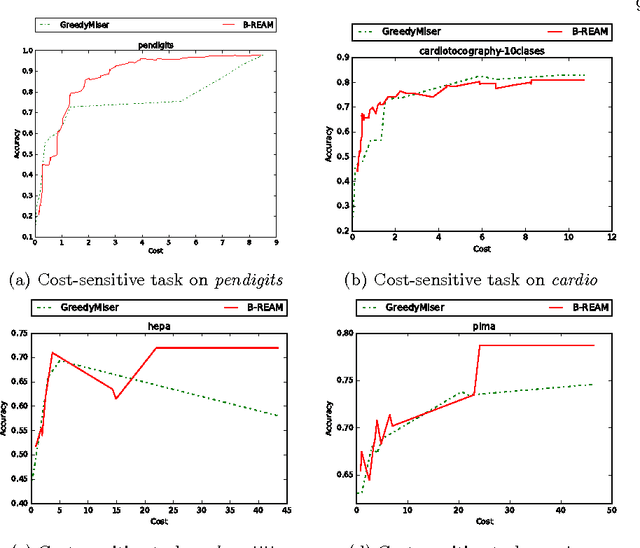
We propose a reinforcement learning based approach to tackle the cost-sensitive learning problem where each input feature has a specific cost. The acquisition process is handled through a stochastic policy which allows features to be acquired in an adaptive way. The general architecture of our approach relies on representation learning to enable performing prediction on any partially observed sample, whatever the set of its observed features are. The resulting model is an original mix of representation learning and of reinforcement learning ideas. It is learned with policy gradient techniques to minimize a budgeted inference cost. We demonstrate the effectiveness of our proposed method with several experiments on a variety of datasets for the sparse prediction problem where all features have the same cost, but also for some cost-sensitive settings.