 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIFTY: a Non-Local Image Flow Matching for Texture Synthesis
Sep 26, 2025This paper addresses the problem of exemplar-based texture synthesis. We introduce NIFTY, a hybrid framework that combines recent insights on diffusion models trained with convolutional neural networks, and classical patch-based texture optimization techniques. NIFTY is a non-parametric flow-matching model built on non-local patch matching, which avoids the need for neural network training while alleviating common shortcomings of patch-based methods, such as poor initialization or visual artifacts. Experimental results demonstrate the effectiveness of the proposed approach compared to representative methods from the literature. Code is available at https://github.com/PierrickCh/Nifty.git
Unifying and extending Precision Recall metrics for assessing generative models
May 02, 2024With the recent success of generative models in image and text, the evaluation of generative models has gained a lot of attention. Whereas most generative models are compared in terms of scalar values such as Frechet Inception Distance (FID) or Inception Score (IS), in the last years (Sajjadi et al., 2018) proposed a definition of precision-recall curve to characterize the closeness of two distributions. Since then, various approaches to precision and recall have seen the light (Kynkaanniemi et al., 2019; Naeem et al., 2020; Park & Kim, 2023). They center their attention on the extreme values of precision and recall, but apart from this fact, their ties are elusive. In this paper, we unify most of these approaches under the same umbrella, relying on the work of (Simon et al., 2019). Doing so, we were able not only to recover entire curves, but also to expose the sources of the accounted pitfalls of the concerned metrics. We also provide consistency results that go well beyond the ones presented in the corresponding literature. Last, we study the different behaviors of the curves obtained experimentally.
LATENTPATCH: A Non-Parametric Approach for Face Generation and Editing
Jan 30, 2024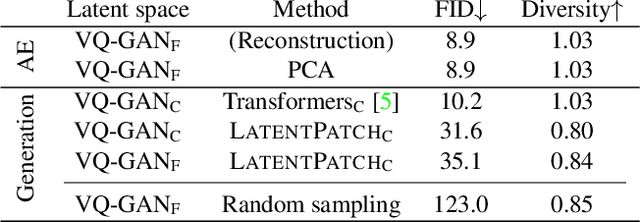


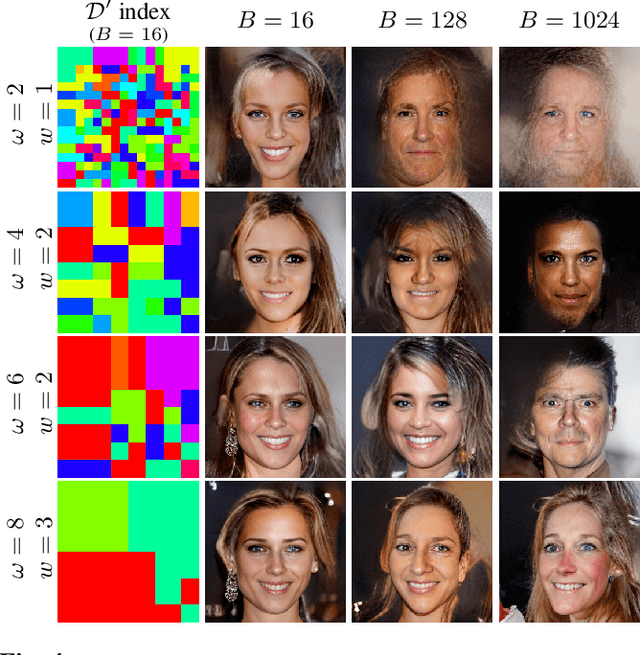
This paper presents LatentPatch, a new method for generating realistic images from a small dataset of only a few images. We use a lightweight model with only a few thousand parameters. Unlike traditional few-shot generation methods that finetune pre-trained large-scale generative models, our approach is computed directly on the latent distribution by sequential feature matching, and is explainable by design. Avoiding large models based on transformers, recursive networks, or self-attention, which are not suitable for small datasets, our method is inspired by non-parametric texture synthesis and style transfer models, and ensures that generated image features are sampled from the source distribution. We extend previous single-image models to work with a few images and demonstrate that our method can generate realistic images, as well as enable conditional sampling and image editing. We conduct experiments on face datasets and show that our simplistic model is effective and versatile.
On the De-duplication of LAION-2B
Mar 17, 2023Generative models, such as DALL-E, Midjourney, and Stable Diffusion, have societal implications that extend beyond the field of computer science. These models require large image databases like LAION-2B, which contain two billion images. At this scale, manual inspection is difficult and automated analysis is challenging. In addition, recent studies show that duplicated images pose copyright problems for models trained on LAION2B, which hinders its usability. This paper proposes an algorithmic chain that runs with modest compute, that compresses CLIP features to enable efficient duplicate detection, even for vast image volumes. Our approach demonstrates that roughly 700 million images, or about 30\%, of LAION-2B's images are likely duplicated. Our method also provides the histograms of duplication on this dataset, which we use to reveal more examples of verbatim copies by Stable Diffusion and further justify the approach. The current version of the de-duplicated set will be distributed online.
This Person (Probably) Exists. Identity Membership Attacks Against GAN Generated Faces
Jul 13, 2021


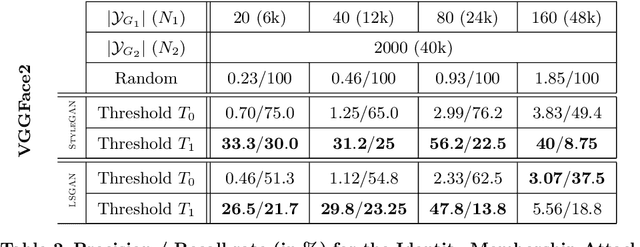
Recently, generative adversarial networks (GANs) have achieved stunning realism, fooling even human observers. Indeed, the popular tongue-in-cheek website {\small \url{ http://thispersondoesnotexist.com}}, taunts users with GAN generated images that seem too real to believe. On the other hand, GANs do leak information about their training data, as evidenced by membership attacks recently demonstrated in the literature. In this work, we challenge the assumption that GAN faces really are novel creations, by constructing a successful membership attack of a new kind. Unlike previous works, our attack can accurately discern samples sharing the same identity as training samples without being the same samples. We demonstrate the interest of our attack across several popular face datasets and GAN training procedures. Notably, we show that even in the presence of significant dataset diversity, an over represented person can pose a privacy concern.
Variational models for signal processing with Graph Neural Networks
Apr 03, 2021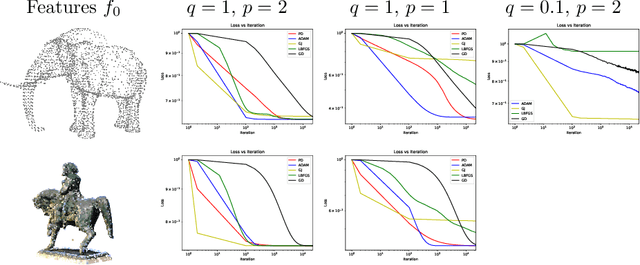


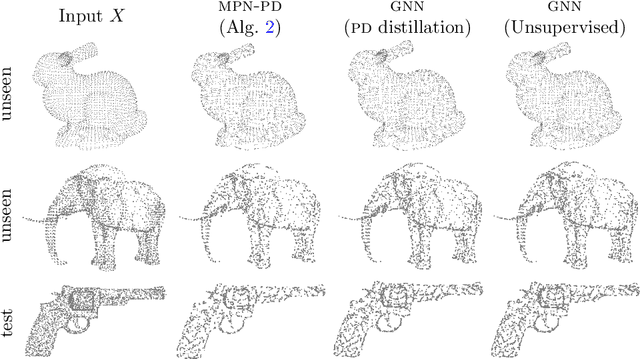
This paper is devoted to signal processing on point-clouds by means of neural networks. Nowadays, state-of-the-art in image processing and computer vision is mostly based on training deep convolutional neural networks on large datasets. While it is also the case for the processing of point-clouds with Graph Neural Networks (GNN), the focus has been largely given to high-level tasks such as classification and segmentation using supervised learning on labeled datasets such as ShapeNet. Yet, such datasets are scarce and time-consuming to build depending on the target application. In this work, we investigate the use of variational models for such GNN to process signals on graphs for unsupervised learning. Our contributions are two-fold. We first show that some existing variational-based algorithms for signals on graphs can be formulated as Message Passing Networks (MPN), a particular instance of GNN, making them computationally efficient in practice when compared to standard gradient-based machine learning algorithms. Secondly, we investigate the unsupervised learning of feed-forward GNN, either by direct optimization of an inverse problem or by model distillation from variational-based MPN. Keywords:Graph Processing. Neural Network. Total Variation. Variational Methods. Message Passing Network. Unsupervised learning
On the Existence of Optimal Transport Gradient for Learning Generative Models
Feb 10, 2021

The use of optimal transport cost for learning generative models has become popular with Wasserstein Generative Adversarial Networks (WGAN). Training of WGAN relies on a theoretical background: the calculation of the gradient of the optimal transport cost with respect to the generative model parameters. We first demonstrate that such gradient may not be defined, which can result in numerical instabilities during gradient-based optimization. We address this issue by stating a valid differentiation theorem in the case of entropic regularized transport and specify conditions under which existence is ensured. By exploiting the discrete nature of empirical data, we formulate the gradient in a semi-discrete setting and propose an algorithm for the optimization of the generative model parameters. Finally, we illustrate numerically the advantage of the proposed framework.
Equivalence of several curves assessing the similarity between probability distributions
Jun 21, 2020



The recent advent of powerful generative models has triggered the renewed development of quantitative measures to assess the proximity of two probability distributions. As the scalar Frechet inception distance remains popular, several methods have explored computing entire curves, which reveal the trade-off between the fidelity and variability of the first distribution with respect to the second one. Several of such variants have been proposed independently and while intuitively similar, their relationship has not yet been made explicit. In an effort to make the emerging picture of generative evaluation more clear, we propose a unification of four curves known respectively as: the precision-recall (PR) curve, the Lorenz curve, the receiver operating characteristic (ROC) curve and a special case of R\'enyi divergence frontiers.
Wasserstein Generative Models for Patch-based Texture Synthesis
Jun 19, 2020
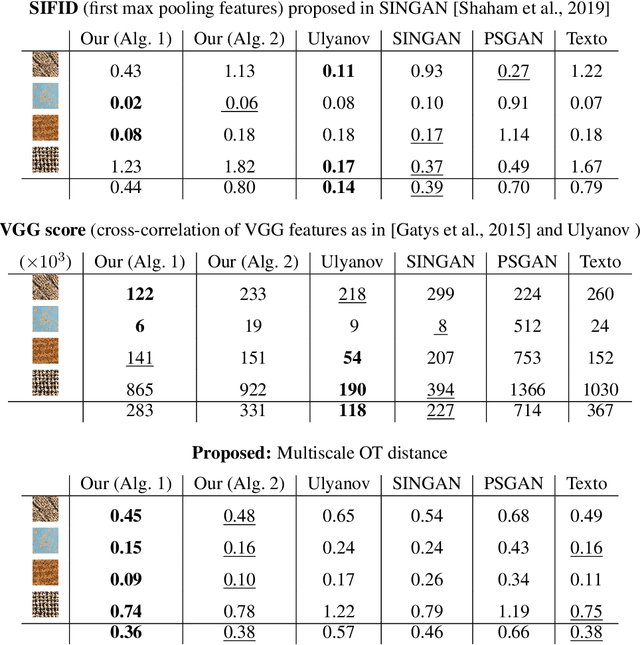


In this paper, we propose a framework to train a generative model for texture image synthesis from a single example. To do so, we exploit the local representation of images via the space of patches, that is, square sub-images of fixed size (e.g. $4\times 4$). Our main contribution is to consider optimal transport to enforce the multiscale patch distribution of generated images, which leads to two different formulations. First, a pixel-based optimization method is proposed, relying on discrete optimal transport. We show that it is related to a well-known texture optimization framework based on iterated patch nearest-neighbor projections, while avoiding some of its shortcomings. Second, in a semi-discrete setting, we exploit the differential properties of Wasserstein distances to learn a fully convolutional network for texture generation. Once estimated, this network produces realistic and arbitrarily large texture samples in real time. The two formulations result in non-convex concave problems that can be optimized efficiently with convergence properties and improved stability compared to adversarial approaches, without relying on any regularization. By directly dealing with the patch distribution of synthesized images, we also overcome limitations of state-of-the art techniques, such as patch aggregation issues that usually lead to low frequency artifacts (e.g. blurring) in traditional patch-based approaches, or statistical inconsistencies (e.g. color or patterns) in learning approaches.
On Demand Solid Texture Synthesis Using Deep 3D Networks
Jan 13, 2020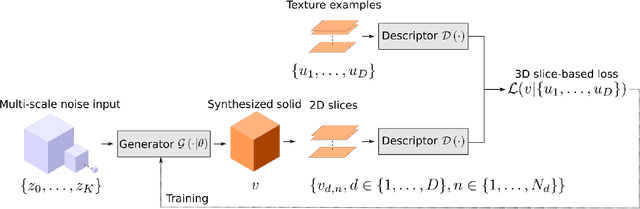
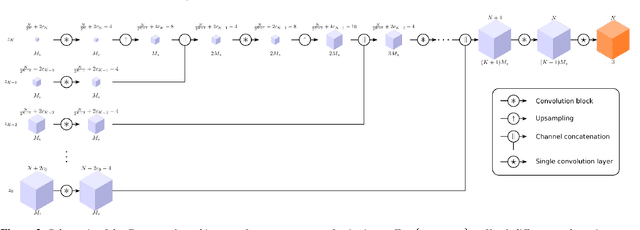
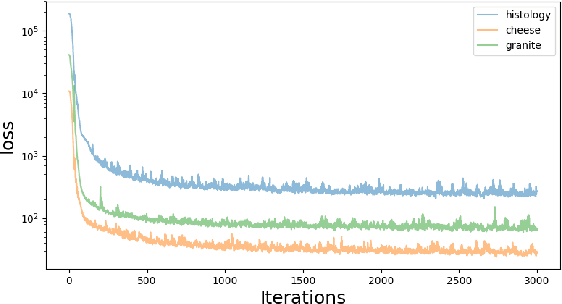

This paper describes a novel approach for on demand volumetric texture synthesis based on a deep learning framework that allows for the generation of high quality 3D data at interactive rates. Based on a few example images of textures, a generative network is trained to synthesize coherent portions of solid textures of arbitrary sizes that reproduce the visual characteristics of the examples along some directions. To cope with memory limitations and computation complexity that are inherent to both high resolution and 3D processing on the GPU, only 2D textures referred to as "slices" are generated during the training stage. These synthetic textures are compared to exemplar images via a perceptual loss function based on a pre-trained deep network. The proposed network is very light (less than 100k parameters), therefore it only requires sustainable training (i.e. few hours) and is capable of very fast generation (around a second for $256^3$ voxels) on a single GPU. Integrated with a spatially seeded PRNG the proposed generator network directly returns an RGB value given a set of 3D coordinates. The synthesized volumes have good visual results that are at least equivalent to the state-of-the-art patch based approaches. They are naturally seamlessly tileable and can be fully generated in parallel.